第1章 从宏观视角看大数据分析
本书的目标是让你熟悉 Apache Spark用到的工具和技术,重点介绍Hadoop平台上使用的Hadoop部署和工具。大多数Spark的生产环境会采用Hadoop集群,用户在集成 Spark和Hadoop配套的各种工具时会遇到很多挑战。本书将讲解Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)和另一种资源协商器(Yet Another Resource Negotiator,YARN)面临的集成挑战,以及Spark和Hadoop使用的各种工具。本书还会讨论所有Spark组件—Spark Core、Spark SQL、DataFrame、Dataset、Spark Streaming、Structured Streaming、MLlib、GraphX 和 SparkR,以及它与分析组件(如Jupyter、Zeppelin、Hive、HBase)及数据流工具(例如 NiFi)的集成。此外,本书还会通过使用MLlib的一个实时推荐系统示例来帮助我们理解数据科学技术。
在本章,我们会从比较宏观的角度来介绍大数据分析,并尝试了解在 Apache Hadoop 和 Apache Spark 平台上使用的工具和技术。
大数据分析是分析大数据的过程,它可以提取过去、当前和未来的统计数据,以及用于改进业务决策的内在规律性。
大数据分析大致可分为两大类:数据分析和数据科学,它们是相互关联的学科。本章会解释数据分析与数据科学之间的差异。数据分析和数据科学在当前行业里的定义会随着它们的应用案例的不同而不同,但让我们尝试理解它们分别能够完成什么工作。
数据分析侧重于数据的收集和解释,通常侧重于过去和现在的统计。而另一方面,数据科学通过进行探索性分析,可以根据过去和现在的数据所识别的模型来产生推荐,重点关注于未来。
图1-1解释了数据分析和数据科学在时间和实现的价值方面的差异。图中还显示了它们解决的典型问题和使用的工具及技术。数据分析主要有两种类型的分析:描述性分析和诊断性分析。数据科学也有两种类型的分析:预测性分析和规范性分析。数据科学和数据分析的具体情况如图1-1所示。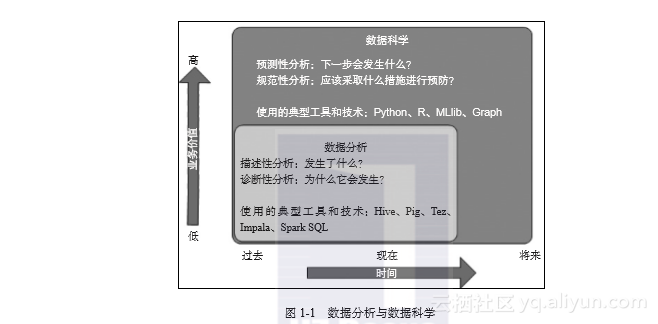
图1-1 数据分析与数据科学
两者之间在过程、工具、技术、技能和输出方面的差异见下表: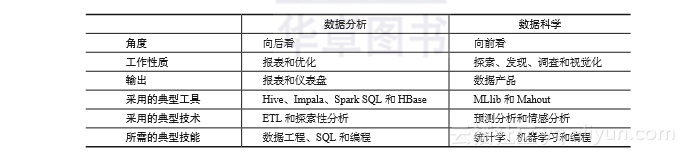
本章要讨论的主题如下:
大数据分析以及Hadoop和Spark在其中承担的角色
大数据科学以及Hadoop和Spark在其中承担的角色
相关的工具和技术
真实环境下的用例.