2.5 K-Means算法原理及Hadoop MapReduce实现
2.5.1 K-Means算法原理
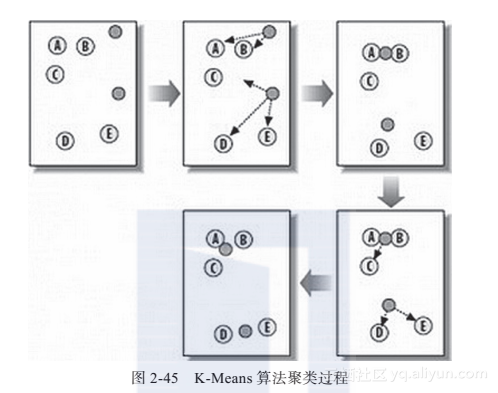
K-Means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表。它是将数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则(如图2-45所示)。K-Means算法以欧氏距离作为相似度测度,求对应某一初始聚类中心向量V最优分类,使得评价指标最小。算法采用误差平方和准则函数作为聚类准则函数。
具体的算法步骤如下:
1)随机在图中取K(这里K=2)个种子点。
2)然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。图2-45中,我们可以看到A、B属于上面的种子点,C、D、E属于下面中部的种子点。
3)接下来,我们要移动种子点到属于它的“点群”的中心。见图2-45中的第3步。
4)然后重复第2)和第3)步,直到种子点没有移动。我们可以看到图2-45中的第4步上面的种子点聚合了A、B、C,下面的种子点聚合了D、E。
图2-46所示为K-Means算法的流程图。
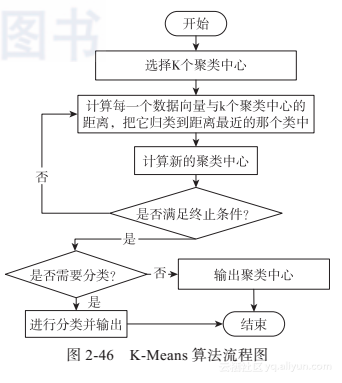
该流程图描述其实和算法步骤类似,不过,这里需要考虑下面几个问题:
1)选择k个聚类中心用什么方法?
提示:可以随机选择或直接取前k条记录。
2)计算距离的方法有哪些?
提示:欧氏距离、余弦距离等。
3)满足终止条件是什么?
提示:使用前后两次的聚类中心误差(需考虑阈值小于多少即可);使用全局误差小于阈值(阈值选择多少?)。
请读者考虑上面的几个问题,并完成下面的动手实践(K-Means算法实现)。
时间: 2025-01-30 02:18:06