本节书摘来自华章出版社《R语言数据分析》一书中的第2章,第2.1节,作者盖尔盖伊·道罗齐(Gergely Daróczi),潘怡 译,更多章节内容可以访问“华章计算机”公众号查看。
第2章
从Web获取数据
实际项目中,经常会碰见所需数据不能从本地数据库或硬盘中获取而需要通过Internet获得的情况。此时,可以要求公司的IT部门或数据工程师按照下图所示的流程将原有的数据仓库扩展,从网络获取处理所需要的数据再倒入公司自己的数据库:
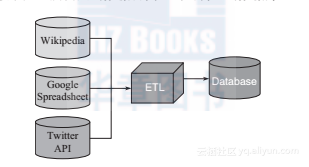
如果公司还没有建立ETL系统(抽取、转换装载数据),或者我们等不及IT部门用几个星期那么长的时间来完成任务,我们也可以选择自己动手,这样的工作对数据科学家来说是很常见的任务,因为大多数时候我们都在开发一些原型系统然后再由软件工程师们将其转化为实际产品。因此,在日常工作中,我们必须要掌握一些基本技能:
用程序从网络上下载数据
处理XML和JSON格式的数据
从原始的HTML源
与API实现交互
尽管数据科学家被认为是21世纪最具吸引力的工作(参见:https://hbr.org/2012/10/data-scientist-the-sexiest-job-ofthe-21st-century/),大多数数据科学家的工作都与数据分析无关。而有可能更糟糕的是,有些时候这样的工作看起来还很乏味,或者日常工作也仅需一些基本的IT技能就足以应付,与机器学习根本不相干。因此,我更愿意把这类工作称为“数据黑客”,而不是数据科学家,这也意味着我们在工作时必须学会亲自动手。
数据筛选和数据清洗是数据分析中最乏味的部分,但却是整个数据分析工作中最重要的步骤之一。也可以说,80%的数据分析工作其实都是在做数据清洗,在这一部分也不需要对这些垃圾数据用最先进的机器学习算法处理,因此,读者应该确保将时间用于从数据源取得有用和干净的数据。
本章将通过R包大量使用网络浏览器debugging工具,包括Chrome的DevTools和Firefox的FireBug。这些工具都比较容易使用,而为了下一步的工作,我们也有必要好好了解和掌握它们。因此,如果读者正面临获取在线数据的问题,可以关注其中一些工具的使用手册。本书的附录也列出了一些起步的方法。
读者也可以参考“Web Technologies and Services CRANTask View”(http://cran.r-project.org/web/views/WebTechnologies.html),快速了解R中能够实现获取Web数据以及与Web服务进行交互功能的包。
2.1 从Internet导入数据集
可以分两步完成从Web获取数据集并将其导入到R会话的任务:
(1)将数据集保存到磁盘。
(2)使用类似read.table这类标准函数完成数据读取,例如:foreign::read.spss可以导入sav格式的文件。
我们也可以通过直接从文件的URL读取平坦文本的数据文件来省略掉第一步的工作。下面的样例将从Americas Open Geocode(AOG)数据库(http://opengeocode.org),获取一个以逗号分隔的文件,AOG网站提供了政府和国家机构的统计信息、人口信息、以及全国各邮政机构的网址信息:

在本例中,我们在read.table命令中将f?ile参数的值设置为一个超链接,可以在处理之前下载相应的文本文件。read.table函数在后台会使用url函数,该函数支持HTTP和FTP协议,也能处理代理服务器,但还是存在一定的局限性。例如,除了Windows系统的一些特殊情况,它一般不支持超文本安全传输协议(Hypertext Transfer Protocol Secure,HTTPS),而该协议却是实现敏感数据Web服务通常必须要遵守的协议。
HTTPS不是一个与HTTP独立的协议,而是在HTTP协议上再增加一个封装好了的SSL/TLS连接。由于HTTP在服务器和客户端之间可以传输未经封装的数据包,因此通常认为使用HTTP协议不能保证数据传输的安全。而HTTPS协议通过可信标记可以拒绝第三方窃取敏感信息。
如果是这类应用,最有效也最合理的解决方法就是安装和使用RCurl包,该包支持R客户端和curl(http://curl.haxx.se)的接口。Curl支持非常多的协议类型,也支持URI框架,还能处理cookie,授权、重定向、计时等多项任务。
例如,我们先检查一下http://catalog.data.gov/dataset上U.S.政府部门的公开数据日志。尽管不使用SSL也可以访问这个常用网址,但大多数提供下载功能的URL地址遵守的还是HTTPS URL协议。在以下样例中,我们将从消费者金融保护局的顾客意见反馈数据库(http://catalog.data.gov/dataset/consumercomplaint-database)提供的网址上下载逗号分隔值文件(Comma Separated Values,CSV)格式的文件。
该CSV文件包括了自2011年以来,大约25万条顾客对金融产品和金融服务的反馈意见。文件大小约为35M~40M,因此下载可能会需要花一点时间。而且读者也可能不希望在移动网络或受限环境下重复接下来的操作。如果getURL函数在验证的时候出现错误(常见于某些Windows系统),可以通过Options参数手动填写验证路径(RCurlOptions = list(cainfo= system.f?ile ("CurlSSL", "cacert.pem", package = "RCurl"))),或者尝试使用Hadley Wickham提供的httr(RCurl前端)或者是Jeroen Ooms提供的curl包——详细说明参见下文。
当把这些CSV文件下载下来直接导入R后,让我们先看一下有关产品类别的反馈意见:

从中可以发现大多数意见都是针对债权问题,这里工作的重点是介绍使用curl包从某个HTTPS URL下载CSV文件,然后通过read.csv函数(也可以使用其他后述章节将讨论的其他函数)读取文件内容的过程。
除了GET请求,读者还可以使用POST、DELETE或PUT请求与RESTful API端点交互,也可以使用RCurl包的postForm函数和httpDELETE,httpPUT或httpHEAD函数—详细内容请稍后参考下文关于httr包的内容。
也可以使用Curl从那些要求授权的有安全保护的站点下载数据。最简单的方法是在主页注册,将cookie保存到一个文本文件中,然后在getCurlHandle中将文件路径传给cookief?ile参数。也可以在其他选项中指明useragent类型。请参考http://www.omegahat.org/RCurl/RCurlJSS.pdf获得更详细和全面(也是非常有用)有关RCurl重要特性的帮助。
curl功能已经非常强大,但对于那些没有一定IT背景的用户来说,它的语法和众多选项让人难以适应。相比而言,httr包是对RCurl的一个简化,既封装了常见的操作和日常应用功能,同时配置要求也相对简单。
例如,httr包对连接同一网站的不同请求的cookies基本上都是自动采用统一的连接方式,对错误的处理方法也进行了优化,降低了用户的调试难度,提供了更多的辅助函数,包括头文件配置、代理使用方法以及GET、POST、PUT、DELETE等方法的使用等。另外,httr包对授权请求的处理也更人性化,提供了OAuth支持。
OAuth是中介服务提供商支持的一种开源授权标准。有了OAuth,用户就不需要分享实际的信用证书,而可以通过授权方式来共享服务提供商的某些信息。例如,用户可以授权谷歌与第三方之间分享实际的用户名、e-mail地址等信息,而不用公开其他敏感信息,也没必要公开密码。OAuth最常见的应用是被用于以无密码方式访问各类Web服务和API等。更多相关信息,请参考本书第14章,我们将在14章中就如何使用OAuth和Twitter授权R会话获取数据进行详细探讨。
但如果遇到了数据不能以CSV文件格式下载的情况该怎么办呢?