第2章 深度学习是什么
2.1 神经网络是什么
要说深度学习(deep learning),就必须先说神经网络,或者称人工神经网络(artificial neural network,ANN)。神经网络是一种人类由于受到生物神经细胞结构启发而研究出的一种算法体系。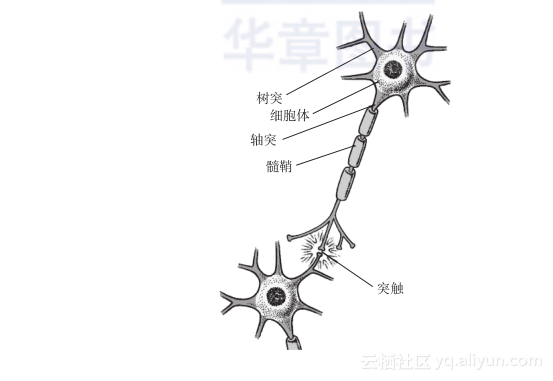
人的神经细胞就像图上这样,枝枝杈杈很多,远远看上去一边比较粗大一边比较纤细。最上端粗大的这一边就是细胞体的所在,细胞体上有一些小枝杈叫做树突,细长的这一条像尾巴一样的东西叫做轴突。不同细胞之间通过树突和轴突相互传递信息,它们的接触点叫突触,准确说是由一个细胞的轴突通过突触将信号传递给另一个细胞的树突。
神经细胞在信号的传递中用的是化学信号进行传递,化学信号就是靠一些有机化学分子的传输来传递信息,但是有机化学分子太复杂了,到现在为止人类对于这些化学分子所具体承载的信息仍旧是一知半解,还没有形成完整的体系性解释。而人类从这种通过神经细胞之间的刺激来传递信息的方式中获得了启迪——是否我们也可以设计这样一种网络状连接的处理单元,让它们彼此之间通过某种方式互相刺激、协同完成信息处理呢?前人们还真有这种脑洞大又圆的。
比较早的我们可以追溯到1957年Rosenblatt提出的感知器模型(perceptron),这种模型和现在最新应用框架中的神经网络单元形式上还确实是非常接近的。我们要想了解神经网络,就应该先看看它最基本的组成单元——神经元。
2.1.1 神经元
神经网络让人觉得难以亲近的地方其实就是它的实现原理,至少远远没有原来我们接触到的各种基于统计的算法那么直观。我们原来在数据结构研究领域和基础算法研究领域中所接触到的各种算法基本都是一些加减乘除、比大小、循环、分支、读写数据,用这些基本的组合就能够完成一个相对确定的目标任务了,即便这个目标是一个比较复杂的算法内容。而神经网络和这种方式感觉上还真是有那么点不一样,我们先来看看神经元是个什么东西。
这就是一个最简单的神经元了,有一个输入,一个输出,所以它所表达的含义跟一个普通的函数没有什么区别。不过请注意,现在我们使用的神经元通常有两个部分组成,一个是“线性模型”,另一个是“激励函数”。如果你对机器学习不大了解的话,我们就先说说这个“线性模型”。
假设这个神经元的函数表达为:
那么这就是一个普通的一次函数。也就是说,当输入为x?=?1时,输出端的f(x)?=?2;当输入为x?=?100时,输出端的f(x)?=?101。怎么样,是不是很简单。没错,你刚刚看到的就是最为简单的神经元工作的原理,和普通的函数真的看不出什么太大的区别。也许你要说,这么简单的东西干嘛非要往神经元上去靠,这不是把问题复杂化了么?好吧,这个问题我也先不做解释,我们再看下一个例子。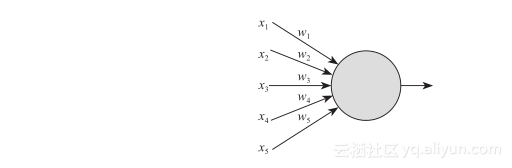
x既然可以是一个一维的向量,那其实也可以是5维的(就如上图这样),当然也可以是100维或更多,我们就说它的输入为一个n维向量吧。按照前面一维向量的处理方式,我们可以建立一个有n个输入项的神经元f(x),把它展开写就是f(x1, x2,…, xn),咱们在这特别声明一下这个x是一个n维的向量,然后带有一个输出函数值output,这个output的输出值就是函数的输出值f(x),即output?=?f(x),而这个函数的处理我们写作:
这种方式也是神经元最核心部分对x所做的线性处理,其中x是一个1×n的矩阵,而w是一个n×1的权重矩阵,b是偏置项。这种写法看上去很简洁,但是容易让初学者感到糊涂,至少没看明白w和x还有b一起做了啥,那么我们把这个计算过程拆解一下。
假设,n是5,那么x是一个1×5的输入矩阵,例如:
这个就是一个完整的特征向量x了,它表示了对一个样本的描述,这个描述是个多维度的描述,具体每个维度指代的含义在不同的场景下是对应有不同解释的。比如这个矩阵有可能表示的是一个样本客户的个人财务状况,分别表示:
下一个用户可能又是别的值,这样一个一个样本组合起来形成了一个很大的样本空间——注意,这些样本最终都会用来训练模型,我们先记住它们的作用,后面再来逐步讲解究竟是怎么个用法。
w是一个n×1的矩阵,它表示的是一个权重的概念,例如:
[0.3 0.8 1.5 1.2 0.5]
它们分别表示:
[性别权重 年龄权重 年收入权重 用户忠诚度指数权重 负债权重]
还有一个是b,b是一个实数值,或者你把它视作一个1×1的矩阵也无妨。当我们在此回顾刚刚说的这个函数f(x)?=?wx?+?b的时候,我们试着来解读一下这个函数的含义。
wx相乘是两个矩阵进行内积的操作,乘出来是一个实数,最后再加上b。以我们刚刚的例子来看,我们先假设在这个例子中b是0,会得到这样一个结果,即f(x)?=?wx?+?b就变成了: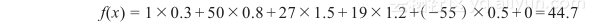
这个函数很有可能是某个金融机构用来评价客户质量所使用的评价函数,那么如果再有一个样本(客户信息),譬如:

在这样的一种评价体系下,第二位客户要比第一位客户获得更高的质量评分。
那么在这个金融机构的日常工作中就可以利用这个函数对客户的情况进行评分,并进行相应的信用额度给予,以及产品推荐等进一步的工作了。这就是一个神经元工作时最直观的感觉,w和x求内积,加b产生这样一个线性的结果输出。因为一个神经元也是一个逻辑简单的模型,所以它本身也能够单独胜任一些逻辑简单的场景。单个的神经元工作起来基本就是这个样子,只不过后面还会加一个激励函数而已,至于激励函数是什么,后面会讲。怎么样,到目前为止还算直观吗?
好,接着刚才的问题来说。问题是,这个权重是谁规定的?
对机器学习有概念的朋友可能不会陌生,如果真的在某个金融机构里有这种公式的话,十有八九是通过“逆向”的方法得到的。什么意思呢?就是说,我们先假设这里有一些未知的权重w(也就是我们刚刚说的那个n×1的矩阵),然后我们同时还拥有大量的客户样本,注意这个地方的样本可不是只有:
这种维度标识,除此之外还有具体被赋予的分数——这个分数一定是由其他方式获得的,比如通过多年的业务经验总结,由业务专家给予的每个样本所拥有的一个分数标签。这样一来场景是什么样的呢?
我们手里的数据:
样本1:(性别1,年龄1,年收入1,用户忠诚度指数1,负债1),分数1
样本2:(性别2,年龄2,年收入2,用户忠诚度指数2,负债2),分数2
……
样本n:(性别n,年龄n,年收入n,用户忠诚度指数n,负债n),分数n
当有了n个这种样本以后,我们通过类似多元线性回归的方式把这些值代入我们假定的f(x)函数,就会得到:
分数1 =性别1×性别权重+年龄1×年龄权重+年收入1×年收入权重+用户忠诚度指数1×用户忠诚度权重+负债1×负债权重+偏置
分数2 =性别2×性别权重+年龄2×年龄权重+年收入2×年收入权重+用户忠诚度指数2×用户忠诚度权重+负债2×负债权重+偏置
……
分数n =性别n×性别权重+年龄n×年龄权重+年收入n×年收入权重+用户忠诚度指数n×用户忠诚度权重+负债n×负债权重+偏置
在前面讲解回归的部分,我们提到过一个叫Loss的函数:
来描述拟合与真实观测的差异之和,我们称之为残差。在这个例子中,如果要想得到比较合适的w和b,那就还是要想办法让这个函数Loss(w, b)尽可能小,然后取满足这个状态的w和b。这个过程是没有区别的。
回想一下在第1章里面我们是不是也见过这个非常熟悉的过程呢?再加深一遍印象吧,在后面的学习中每一个单独的模型都要经历这样一个完整的过程。
2.1.2 激励函数
激励函数(activation function)——也有翻译成激活函数的,也是神经元中重要的组成部分。激励函数在一个神经元当中跟随在f(x)?=?wx?+?b函数之后,用来加入一些非线性的因素。
在谷歌网站的搜索结果中或者别的相关网站资料上我们会看到激励函数有很多种类,就看看它们画出来的曲线吧,见下图,真可谓五花八门。然而在目前成熟的深度学习框架中,供我们使用的激励函数其实很有限,主要也都是手边上那些比较好用的,那我们就看一下通常激励函数都有哪些吧。
1 . Sigmoid函数
Sigmoid函数基本上是我们所有学习神经网络的人第一个接触到的激励函数了。它的定义是这样的:
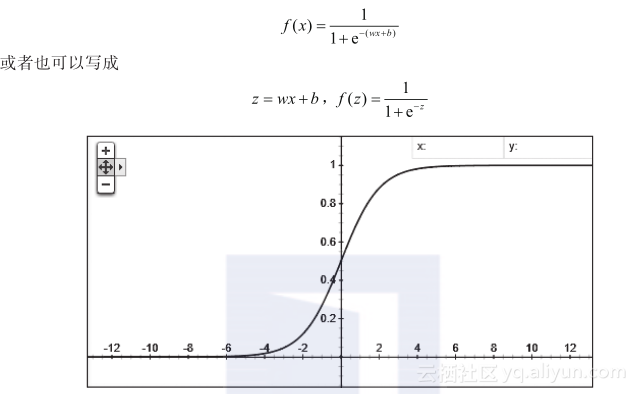
这里的横轴是z,纵轴是f(z)。在这个曲线中我们可以看到,对于一个高维的x向量的输入,在wx两个矩阵做完内积之后,再加上b,这样的一个线性模型的结果充当自变量z再叠加到了当中去。这就使得输入x与输出的f(x)关系与前面我们所举例的内容不同,前面我们只讲了f(x)以线性回归的方式去工作的过程,不过那不是它在神经网络中工作的状态。当一个完整的神经元被定义的时候,它通常是带有“线性模型”和“激励函数”两个部分首尾相接而成的。所以最后一个神经元大概是这么个感觉,前半部分接收外界进来的x向量作为刺激,经过wx?+?b的线性模型后又经过一个激励函数,最后输出。这里只是为了看着方便,x只画了6条线,实际在工作中很多全连接的网络里x要真画出来是要画几万条线不止的。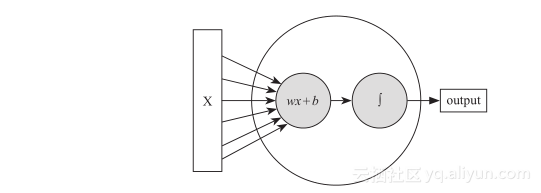
Sigmoid函数是一种较早出现的激励函数,把激励值最终投射到了0和1两个值上。通过这种方式引入了非线性因素。其中的“1”表示完全激活的状态,“0”表示完全不激活的状态,其他各种输出值就介于两者之间,表示其激活程度不同。
说到为什么要引入非线性因素,这个可能是个比较有趣的话题。因为最终用一个大的函数“网络”去拟合一个对应的关系的时候你会发现,如果仅有线性函数来拟合的话,那么拟合的结果一定仅仅包含各种各样的线性关系。一旦这个客观的、我们要求解的关系中本就含有非线性关系的话,那么这个网络必定严重欠拟合——因为从一开始设计出来的网络就属于“先天残疾”,一开始就猜错了人家本身长的样子,那再怎么训练都不会有好结果。线性就是用形如f(x)?=?wx?+?b的表达式来表示的输入与输出的关系,而其他的都应该算作非线性关系了,后面我们会看到具体的例子。
2 . Tanh函数
Tanh函数也算是比较常见的激励函数了,在后面学习循环神经网络RNN(recurrent neural networks)的时候我们就会接触到了。
Tanh函数也叫双曲正切函数,表达式如下:
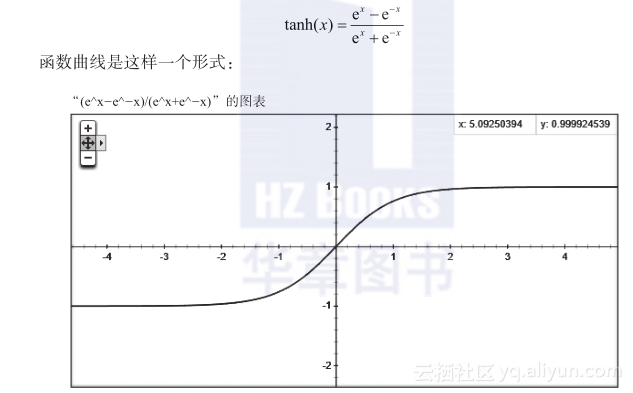
大家可以看到,Tanh函数跟Sigmoid函数长相是很相近的,都是一条“S”型曲线。只不过Tanh函数是把输入值投射到-1和1上去。其中“-1”表示完全不激活,“1”表示完全激活,中间其他值也是不同的激活程度的描述。除了映射区间不同以外,跟Sigmoid似乎区别不是很大。从x和y的关系来看,Sigmoid函数在|?x?|>4之后曲线就非常平缓极为贴近0或1,Tanh函数在|?x?|>2之后会让曲线非常平缓极为贴近-1或1,这多多少少会影响一些训练过程中待定系数的收敛问题,其他的影响单纯从激励函数本身的特性来说还看不出来。
3 . ReLU函数
ReLU函数是目前大部分卷积神经网络CNN(convolutional neural networks)中喜欢使用的激励函数,它的全名是rectified linear units。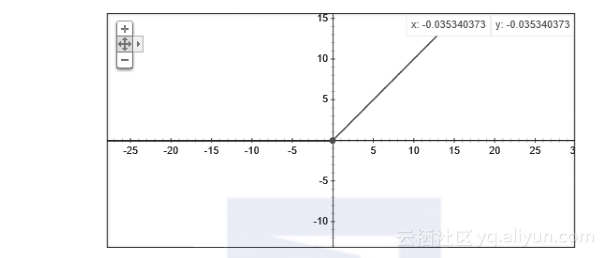
这个函数的形式为y=?max(x, 0),在这个函数的原点左侧部分斜率为0,在右侧则是一条斜率为1的直线。从样子上来看,这显然是非线性的函数,x小于0时输出一律为0,x大于0时输出就是输入值。
这个函数在刚刚我们看过的几个函数图像中看上去是最有棱角、最明朗了的。“人有古怪相必有古怪能”——这函数还真是有一些非常优秀的特性,所以才会让大家在很多网络里都会倾向于使用它。至于为什么我们后面也会详细讲解的,先让它跟你混个脸熟。
4 . Linear函数
Linear激励函数在实际应用中并不太多,原因刚刚已经做过简单的解释了。那就是如果网络中前面的线性层引入的是线性关系,后面的激励层还是线性关系,那么就会让网络没办法很好地拟合非线性特性的关系,从而发生严重的欠拟合现象。
函数表达式: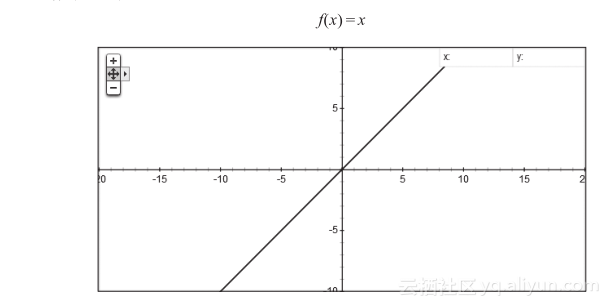
由于这类激励函数的局限性问题,目前主要也就是出现在一些参考资料当中做个“标本”,商用环境是比较罕见的,至少笔者到目前使用这种激励函数的项目也还非常少。
2.1.3 神经网络
一旦多个神经元首尾连接形成一个类似网络的结构来协同工作的时候,那就可以被称为神经网络了。一般也没有人硬性规定网络必须有多少层,每层有多少个神经元节点,完全是在各个场景的Case中根据经验和一些相关理论进行尝试,最后得到一个适应当前场景的网络设计。
大家请注意这一点,在学习神经网络(深度学习)的整个历程中你会不断发现这样或者那样的不同形式的网络,每种网络或出自某个具体的工程项目,根据需求、工程人员经验、实验效果来选定的,或者出自某些尖端的实验室(例如谷歌、微软以及国内一些顶级企业等),并辅以相关的论文对网络在实验中的效果与同期其他网络的解决方案做对比。但是你极少能发现在这些网络的诞生过程中有完整的、严谨的、普适的、毋庸置疑的推导过程——也难怪有不少从事深度学习多年的资深老兵说深度学习越学越像老中医。我觉得这个说法还挺形象,年轻大夫没经验不敢轻易开方子,等熬成了老中医的时候才发现里面门道太深,深到了研究了一辈子也没办法总结出完整的、可以精确推导的公式或定理,大部分情况只能靠自己的经验和实验结果调整药方。听起来好像挺无奈的是吧?其实你学过之后就知道了,用好了是真能解决问题,因为还是有一些沉淀下来相对比较固定的设计思路、设计技巧和体系。
闲言少叙,咱们来看神经网络的结构吧。这就是一个比较简单的神经网络结构了。在一个神经网络中通常会分这样几层:输入层(input layer)、隐藏层(hidden layer,也叫隐含层)、输出层(output layer)。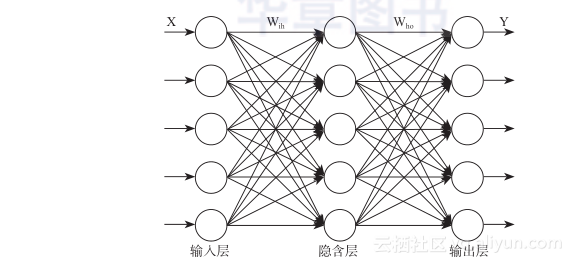
输入层在整个网络的最前端部分,直接接受输入的向量,它是不对数据做任何处理的,所以通常这一层是不计入层数的。
隐藏层可以有一层或多层,现在比较深的网络据我所知有超过50层的,甚至在一些“特殊”的网络——例如深度残差网络中有超过150层的!这已经非常多了,在本书所涉及的实验中是没有这么多层的神经网络出现的。
输出层是最后一层,用来输出整个网络处理的值,这个值可能是一个分类向量值,也可能是一个类似线性回归那样产生的连续的值,也可能是别的复杂类型的值或者向量,根据不同的需求输出层的构造也不尽相同,后面我们会逐步接触到。
神经元就是像图上所画的这种首尾相接的方式进行数据传递的,前一个神经元接收数据,数据经过处理会输出给后面一层的相应的一个或多个神经元。对于一个x向量中的任何一个维度分量,你都可以在这种拓扑描述中看到它在通过一层一层的处理时通过了哪些神经元的处理,并且在输出后又输入了哪些神经元。形式上就是这个样子,所以叫法很形象,神经网络——由神经元(神经节点)所组织的网络。