2.5 在多核系统中并行运行
尽管本章使用了NVIDIA GPU,但OpenACC不是一个GPU编程模型,而是一种普遍适用的并行编程模型。尽管在2.4节中使用的循环优化技术仅适用于GPU,关于并行度和数据移动的技术手段适用于任意并行架构设备。本章使用的PGI编译器支持多种目标加速器,包括NVIDIA和AMD公司的GPU,以及多核x86 CPU。如果在多核CPU上开发和运行代码,将会发生什么呢?为多核目标平台重新编译代码,而不是将目标设定为tesla(见图2-29和图2-30)。
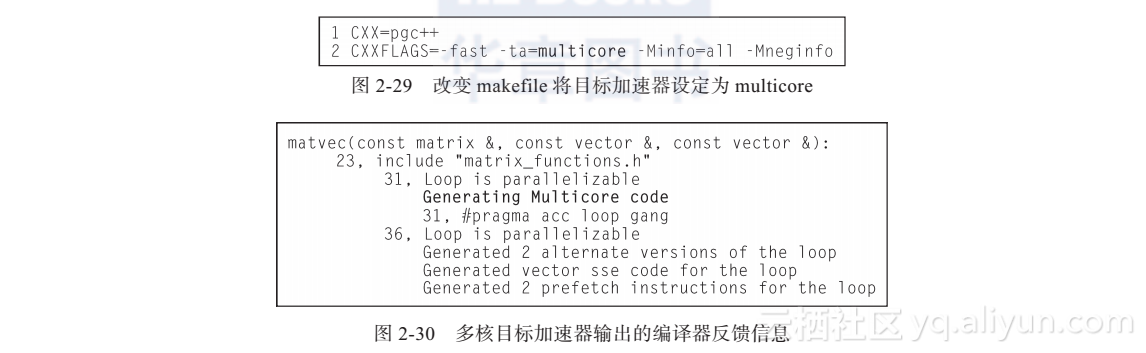
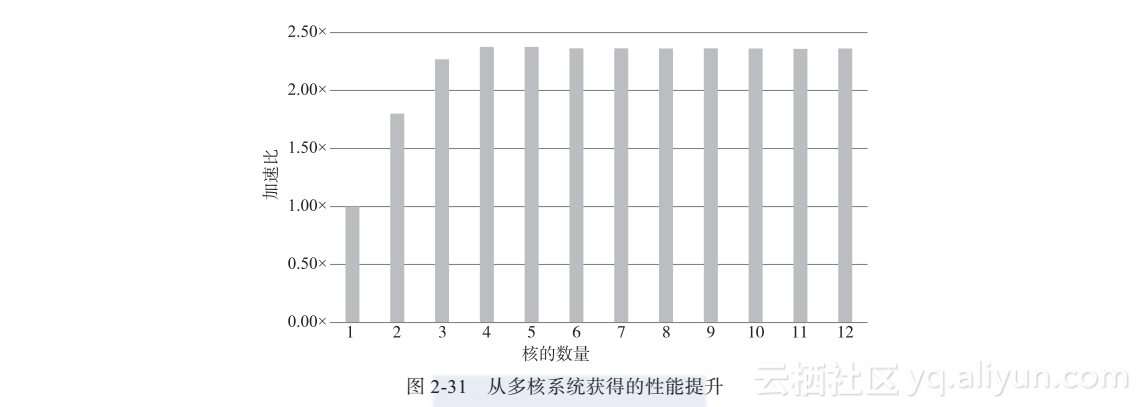
如果运行可执行程序,它将在测试机的多核CPU上并行化各循环,而不是在GPU上运行了。通过设定ACC_NUM_CORES环境变量可以用来调整参与并行计算的CPU的核心数目。图2-31展示了调整核心数目后的加速比情况,该机器具有的最大核心数目是12。性能在使用超过4个CPU核之后保持稳定,这是因为测试程序的性能主要受制于CPU带宽。
时间: 2024-09-16 21:52:53