导读
前段时间楼主决定潜心研究google的word2vec中使用到的相关原理,但是在一番学习之后,楼主发现作为一枚小白,如果对自然语言处理的基础原理都不了解的话,实在是很难理解word2vec中的那些算法/公式等等,于是楼主又转而开始学习自然语言处理中用到的那些基础方法和原理。
那么今天,楼主就以一枚小白的身份来介绍介绍自然语言处理中的一些基础概念和原理,当然,概念和原理很多,楼主这里先介绍的是其中看起来比较基础部分,也是自己感觉能够理解明白的一部分,其他内容,会在系列文章的后续介绍。在此也希望路过的大神以及同样对自然语言处理感兴趣的同学多多交流学习,共同成长。
自然语言处理经历的两个阶段
自然语言处理始于上世纪50年代,起初,研究自然语言处理的前辈们认为,如果要让机器能够和人进行语言交流,那么首先需要让机器能够理解人类的语言,也就是说,机器需要了解词性/词义/语法/文法等等这些规则,是基于语义规则进行的自然语言处理,通常也被称为“鸟飞派”。
然而,这种基于语义规则的自然语言处理研究很快就遇到了瓶颈,因为本身人类语言所涉及的那些规则就非常非常多,在同种语言内就有很多规则是在特定场景下才有效的,且规则与规则之间还存在冲突,在编写规则的时候需要定义该规则的适用场景,而语言本身又在不停的发展,要增加或者修改某一规则的同时还会涉及到其他很多规则的连带改动。而不同的语言又是基于不同的规则的,在不同语言之间这种基于语法规则的自然语言处理根本就没有通用性。以上种种原因,使得基于规则的自然语言处理很快就停滞不前了。
到了70年代,有人提出了基于统计的自然语言处理方法,这个人就是“贾里尼克”,这种自然语言处理方法有效的避开了上述问题,并且获得了众多自然语言处理科学家们的认可。但是新老交替的过程及其漫长,从70年代一直持续到了90年代,期间的原因这里就不多掰了,无非就是新生力量在老一辈没有倒下之前一直被打压的故事等等。接下来,我们就来看看基于统计的语言模型是怎么样的。
统计语言模型
基于统计的语言模型,最主要体现在统计和概率上,大体思路可以通过下面这个例子来介绍:
假设 S 表示一个句子,W1,W2 ... Wn 则表示句子 S 中第1到第n个词,P(S)就表示 S 这个句子在所有的语料中出现的概率。它的概率就是W1,W2 ... Wn同时出现的概率,于是有以下公式:
P(S) = P(W1,W2,…,Wn)
而W1,W2 ... Wn同时出现的概率又可以由下面的公式得到:
P(W1,W2,…,Wn) = P(W1)·P(W2|W1)·P(W3|W1,W2)…P(Wn|W1,W2,…,Wn-1)
这里先解释一下表达式 P(A|B) 的含义:B表示前提条件,A表示概率对象,整个表达式表示在B存在的条件下,A出现的概率。
所以上面的表达式代表:W1作为句首出现的概率乘以W1出现时W2也出现的概率乘以W1和W2同时出现的情况下W3也出现的概率...以此类推,一直乘到W1,W2...Wn-1都出现的情况下Wn也出现的概率。
那么这个概率又是怎么来的呢,这里就要依赖我们的预料库了,语料库是很大很大的一堆语料文本,上面说的概率就是去计算在这个语料库中,这些词出现的概率,所以语料库的大小和质量,直接决定了自然语言处理的准确度。
P(W1)·P(W2|W1)·P(W3|W1,W2)…P(Wn|W1,W2,…,Wn-1) 从这个公式我们可以看出,在语料库特别大,S又是一个长句的情况下,这个公式的计算量是非常非常大的,几乎可以说是不可能算出来的。那怎么办呢?这时候,数学家们的神通本领就显现出来了。
这里用到的是“马尔可夫假设”,马尔可夫假设是俄国数学家马尔可夫在19世纪末20世纪初提出的一种处理上述情况的方法。即当上述情况出现时,我们可以假设某一个元素的出现只和它的前一个元素相关,于是上面的表达式可以变成:
P(W1)·P(W2|W1)·P(W3|W1,W2)…P(Wn|W1,W2,…,Wn-1) = P(W1)·P(W2|W1)·P(W3|W2)…P(Wi|Wi-1)…P(Wn|Wn-1)
表达式变成上面这样以后,我们可以看出,整体的计算量要比之前小了很多很多,计算机很容易就可以算出。上面的公式就是我们统计语言模型常说的二元模型(Bigram Model)。这种马尔可夫假设,也被称为二阶马尔可夫假设。为了使计算变的更加准确,我们还可以使用N-1阶马尔可夫假设来进行处理,即认为一个词出现的概率和它前面的N-1个词相关,这也就是我们常说的N元模型(N-gram Model)。
N元模型的空间复杂度为: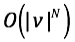
时间复杂度为: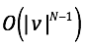
从目前工业上的应用情况来看,当N=3时,较二元模型的处理效果要显著上升,但当N=4或者更大时,这种上升的效果就没有那么明显了,而且对于计算资源成本来说是陡增的,所以,目前工业上的应用应该大部分都选择的是N=3的N元模型。
中文分词
中文分词在整个自然语言处理学科中来说,应该说是相对简单,而且也是已经做的比较好的一个部分了,这里就简单点介绍一下。
最初的中文分词是基于“查词典”的方式来做的,即准备一个中文辞典,在输入一句话以后,系统从左至右进行一轮扫描,基于长词优先的原则,或者是按照最少词划分原则等等,将一句话中的词分割开来。通过这些手段进行的分词方法,基本可以处理大部分的分词情况了。但是在一些复杂的情况下,这种分词方法就显得不是那么的有效了,举下面的例子来说明一下:
发展/中国/家 按照字典查询的方式,“中”本应该是作为一个单独的字,但是按照字典查询,它和后面的“国”组成了“中国”,然而整个句子的分词是不对的。
上海大学/城/书店 按照长词优先的原则,“上海大学”被截成了一个长词,而原本的划分应该是:“上海”/“大学城”/“书店”。
如何解决上述的这些问题呢?其实很简单,利用统计和概率来判断就好了。举个例子,如果一个句子,按照各种分词的方法,可以分成以下三种情况:
A1,A2,A3,…,Ak
B1,B2,B3,…,Bk
C1,C2,C3,…,Ck
那么哪种分词才是最合理的呢?我们利用上一个章节讲到的统计语言模型来解决这个问题,当出现以下这种概率情况的时候,那么按照A的方法来进行分词,一定就是我们最优的分词方法了。
P(A1,A2,A3,…,Ak) > P(B1,B2,B3,…,Bk)
P(A1,A2,A3,…,Ak) > P(C1,C2,C3,…,Ck)
逆文本频率值TF-IDF
这个章节我们来聊一聊逆文本频率值(TF-IDF)。
先来解释一下字面意思:
TF:Term Frequency 即词频。
IDF:Inverse Document Frequecy 逆文本频率指数(数学家取的名字,确实很难理解)。
IF-IDF 简单点可以理解为是加权重的词频。
那么这个东西是用来干什么的呢?我们继续举例子来说明。
假设,我在进行网页关键字搜索的时候,“原子能的应用”这个关键字,一定会有很多可以匹配到的网页,那么搜索引擎应该返回哪些结果呢?按照什么顺序来返回呢?把哪些搜索结果放在前面呢?这里其实有很多需要考虑的因素,其中“查询相关性”就是一个非常重要的因素。而这个TF-IDF就是可以用来进行查询相关性的计算的。
什么是查询相关性呢?我们接着刚才那个例子来讲。假如现在查到了很多个网页上面都包含了“原子能的应用”这组关键字(当然,一般是按照分词后的结果来进行查询的,即“原子能/的/应用”)。那么如果有一个结果网页上一共有1000个词,在这个网页上,“原子能”出现了2次,“的”出现了35次,“应用”出现了5次。则它们在该网页上的的词频分别为0.002,0.035,0.005,于是,我们可以简单的认为“原子能的应用”这组关键字和这个网页的查询相关性为:
(0.002+0.035+0.005)=0.042
但是这个简单的方法中有一些问题:1. “的”这个关键字在整个相关性中贡献了大部分的比重,而“的”这个关键字其实对于主题相关性的判断几乎是没有意义的;2. “应用”这个关键字也贡献了0.005,比“原子能”的贡献高了2.5倍,但其实这组关键字中,“原子能”其实才是和主题相关性最强的。
所以,我们需要在这个简单的以词频来衡量的相关性中加上词的权重来重新计算查询的相关性。方法如下:
为查询关键词设置相关性权重,权重的设定需满足以下条件:
1. 一个词预测主题的能力越强,权重越大,反之,权重越小;
2. 停止词的权重为零。
假定一个关键词 W 在 Dw 个网页中出现过,那么 Dw 越大,则词 W 的权重越小,反之亦然。
计算公式: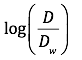
其中D为全部网页数。
举个例子来看下:
例:假设所有的中文网页数为10亿,如果“的”在所有的网页中都出现过,那么它的IDF = log(10亿/10亿) = 0
“原子能”在200万个网页中出现过,那么它的IDF = log(500) = 8.96
“应用”在5亿个网页中出现过,那么它的IDF = log(2) = 1
那么和该网页的查询相关性公式应该从简单的词频相加优化成:
TF1IDF1+TF2IDF2+...+TFn*IDFn
即:0.0028.96+0.0350+0.005*1=0.0161
现在再来看这个方法得出的网页相关性以及每个词的贡献值,就要合理得多了。
这个方法最早是用来进行关键字搜索相关性计算的,在自然语言处理中自然也能用来搜索对话内容匹配答案等等。
向量的相似度
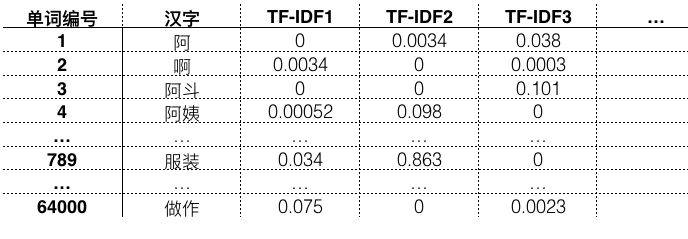
上表的意思先解释一下,表中的第一列就是一个大的词典中的词编号,可以看到共有64000个词。第二列是这个词典中具体的词。第三列呢,它代表一篇文章,但它不是我们可以看懂的文章,而是给计算机去读的一篇文章,它的每一行代表了词典中的这个词在这篇文章中的逆文本频率值(TF-IDF)。那么第四列,则是另一篇文章了,第五列,就是第三篇文章。
我们可以看出,代表文章的每一列,其实是一组64000个元素的超大数组,在自然语言处理中,我们把它叫作一个向量,是一个代表一篇文章的64000维的向量。
那么文章的向量是个什么鬼呢?它是要用来干嘛的?
回想一下上一个章节所讲的内容,TF-IDF是用来表示主题相关性的一个指标,那么这个文章的向量呢,其实也就是代表一篇文章的主题(当然,一篇文章可能涉及多个主题,但是没关系,都可以在这个向量中体现出来)。
一个向量是从空间中的一个点指向另一个点的一段距离,所以,它有两个特征,一个是距离,一个是方向。对于长度非常长的文章来说,它的向量距离则会更长,而反之则越短,而文章的长度和主题其实并没有什么关系,所以向量的长度自然也不会和文章的主题有什么关系。那么向量除了距离之外的另一个属性,则是方向了,如果文章的主题是相似的,则两个代表文章的向量它们的方向也将是相似的(这一点我们把文章向量的维度降维到2维/3维应该很容易就看出来了,这里就不多掰了)。于是,我们可以通过判断两个文章向量的夹角大小来判断,这两篇文章是否是主题相似的。利用余弦定理:
有如下三角形
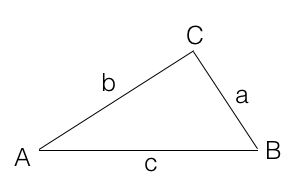
则角A的余弦: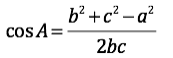
把两边b,c看成是两个以A为起点的向量,则上面公式等价于: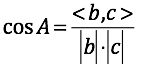
假如文章A和文章B对应的向量分别为:
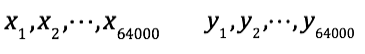
那么,它们夹角的余弦等于:
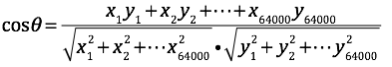
上述公式中,分子分母都是正数,所以结果是在0-1之间的,根据余弦定理我们可以知道,当两个向量相似的时候,它们的夹角将是较小的,最后的结果将接近1,说明它们是主题相似的两篇文章,当两个向量重合时,上式的结果等于1,说明它们是主题完全相同的两篇文章。而当两个向量夹角比较大的时候,甚至相互垂直的时候,结果则是趋于0的。
自然语言处理中用这种向量的方式来计算两个语言对象的相似性,它们可以是词向量,句向量或者文章向量,划分向量的维度可能不同,但是计算相似性的原理是一样的。
矩阵运算中的奇异值分解
最后一部分来聊一下矩阵中的奇异值分解,这个东西嘛,个人感觉是对自然语言处理中工程化进行简化的一种算法,它可以将超大的矩阵运算量成倍的降低,也算是自然语言处理工程化中非常重要的一个部分。
首先来看一下下面这个矩阵:
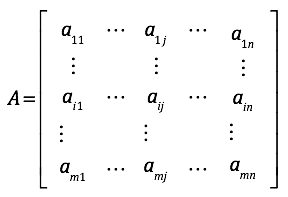
我们假设,有N个词,M篇文章,组成矩阵A,矩阵每行对应一篇文章,每列对应一个词,矩阵中的每个元素代表字典中第j个词在第i篇文章中出现的加权词频(如TF-IDF)。
假如 M=1,000,000 N=500,000,则矩阵中共有5000亿个元素,设想一下,要对这样一个矩阵进行运算,首先,这个矩阵的存储就是一个很困难的事情,要进行运算的话,那就更不要提了。
于是,数学家们提供了一种有效的方法来对这个矩阵进行处理,方法如下:
首先,将矩阵A分解成三个小矩阵X,B,Y。
X:对文章进行分类的结果,每行表示一篇文章,每列表示一个文章主题,一行中每个元素表示这篇文章和各个主题的相关性;
Y:对词进行分类的结果,每列对应一个词,每行对应一个语义类,一列中的每个元素表示这个词和每个语义类的相关性;
B:表示词的语义类和文章主题之间的关系。
于是,矩阵A被分解成了如下三个 1,000,000100 / 100100/100*500,000 的较小矩阵,虽然这三个矩阵仍然不小,但是它们的全部元素加起来,也不过1.5亿,只有矩阵A元素的1/3000不到,相应的存储量和计算量也都会小三个数量级以上。
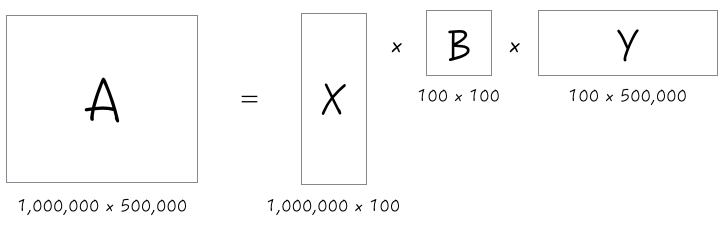
这种方法,在矩阵运算中被称作奇异值分解。
小结
本次分享到此就结束了,对于楼主来说,像线性代数啊,余弦定理啊这些东西,早在很多年前就已经还给老师了,所以这次分享也就不涉及到这些公式的推导,过程的证明了(这些都是数学家们的事情,估计以前学的数学就算记得可能也不怎么管用),纯原理性的东西分享,希望可以和大家多多交流。走过路过的老司机们,看到讲的不对的地方,请不吝纠正。