逻辑回归
逻辑回归模型
逻辑回归表达式:
$$h_\theta(x) = g(\theta^Tx)$$
$$z = \theta^Tx$$
$$g(z) = {1\over 1+e^{-z}}$$
综上,$$h_\theta(x) = {1\over 1+e^{-\theta^Tx}}$$
sigmoid函数:

选择题1:


接下来我们深入的来理解下这个sigmoid函数。通过图可以知道:
- 如果想要判断预测分类$\color{red}{y=1}$,则必须保证$\color{red}{h_\theta(x)>=0.5}$,这里如果用$g(z)$来代替$h_\theta(x)$的话也即$g(z)>=0.5$,则对应的$x$轴则是$z>=0$,所以转换过来也即是$\color{red}{\theta^Tx>=0}$。
- 如果想要判断预测分类$\color{red}{y=0}$,则必须保证$\color{red}{h_\theta(x)<0.5}$,这里如果用$g(z)$来代替$h_\theta(x)$的话也即$g(z)<0.5$,则对应的$x$轴则是$z<0$,所以转换过来也即是$\color{red}{\theta^Tx<0}$。
决策边界
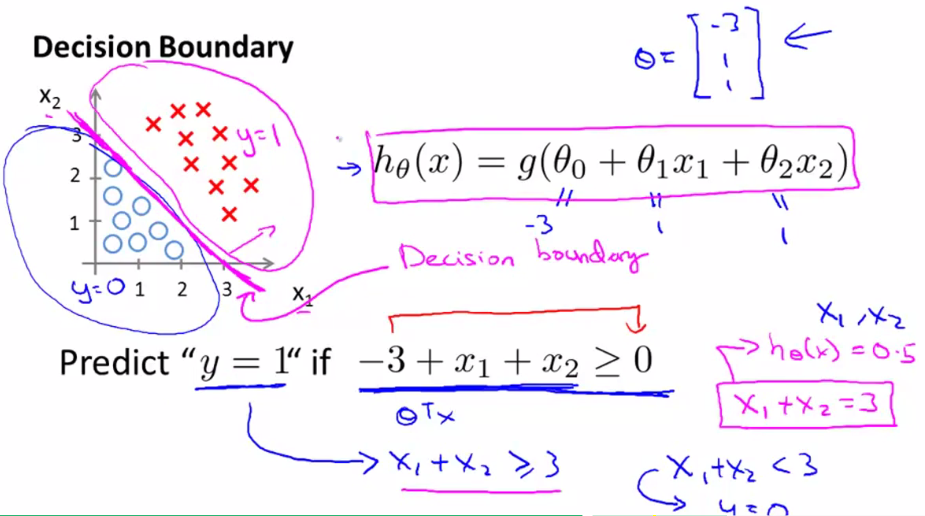
- 对于线性回归:假设$\theta$矩阵中的$\theta_0,\theta_1,\theta_2$已经确定,也就是$\theta^Tx$确定了,那么就会确定一条直线,比如图中的$\color{red}{x_1 + x_2 = 3}$这条直线,我们可以利用这条直线来确定一个边界,边界的一侧是y=1类,另一侧则是y=0类。

- 对于非线性回归:假设$\theta$矩阵已经确定,也就是$\theta^Tx$确定了,那么就会确定一条曲线,比如图中的$\color{red}{x_3^2 + x_4^2 = 1}$这条曲线,我们可以利用这条曲线来确定一个边界,边界的外侧是y=1类,内侧则是y=0类。
代价函数:
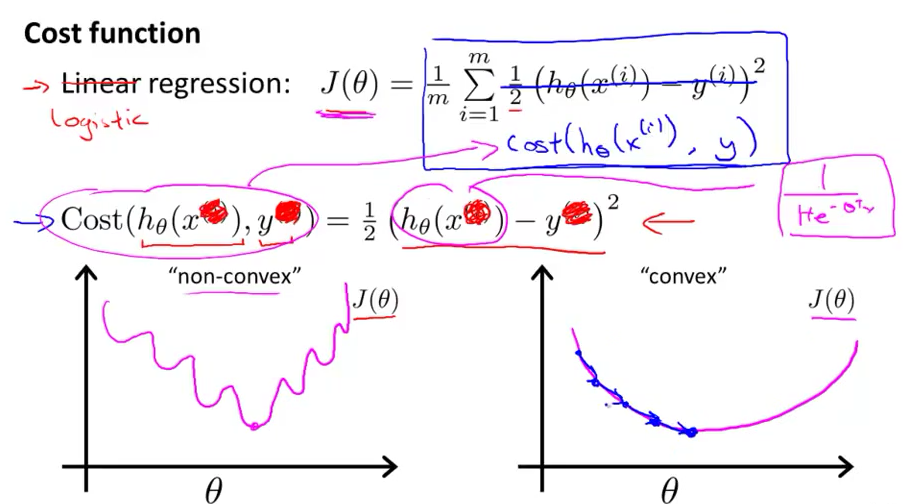
我们由线性代价函数来引入,可以看到,如果将各个单个值的序号去掉那么线性的代价函数无非就是${1\over 2}(h_\theta(x)-y)^2$这个表达式,然而此时我们将线性代数的假设函数$h_\theta(x)$替换成了sigmoid函数,如果继续按着之前的表达式求它的代价cost的话那么它的函数曲线将会是一个“非凸”函数(non-convex),而非一个碗型的“凸”函数(convex)。所以,对于逻辑回归我们将会采用新的代价函数。如下图:

- 对于$\color{red}{y=1}$来说:
此时的cost计算公式为:$$Cost(h_\theta(x)) = -log(h_\theta(x))$$
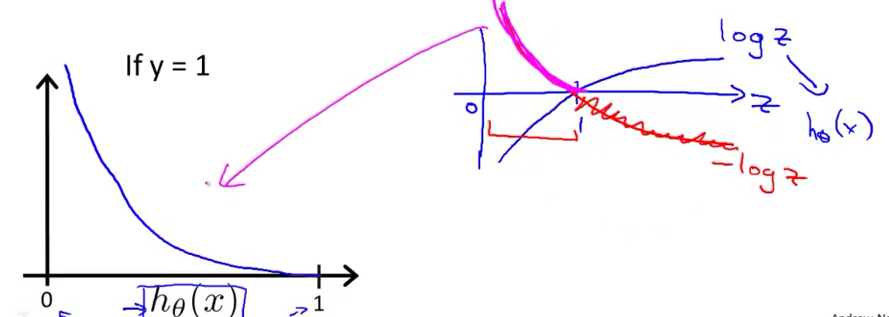
因为$h_\theta(x)$是sigmoid函数,所以它的值域为(0,1),故我们只讨论横坐标$h_\theta(x)$在(0,1)范围内的costJ代价的变化。

如果$y=1,h_\theta(x)=1$,那么就可以说我的预测值与实际值是无偏差的,可以说是$cost=0$,但是假如$y=1,h_\theta(x)=0$,那么意味着我的预测值与实际值是有很大偏差的,那么就要惩罚学习算法让它的代价变大,于是对应上图就可明白,当横坐标$h_\theta(x)=1$时,曲线确实cost=0,而当$h_\theta(x)=0$时,cost趋于了无穷大。
- 对于$\color{red}{y=0}$来说:
此时的cost计算公式为:$$Cost(h_\theta(x)) = -log(1-h_\theta(x))$$
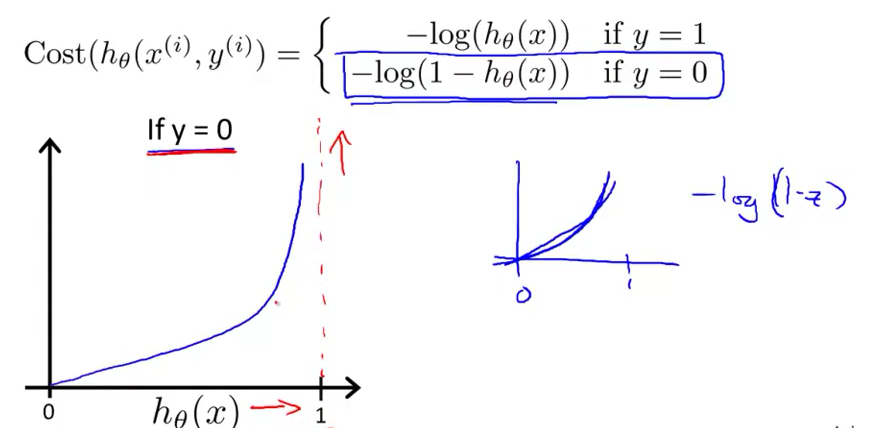
同样$h_\theta(x)$的值域为(0,1),所以我们只讨论横坐标在(0,1)的范围内的cost的变化。如果$y=0$,$h_\theta(x)=0$,那么就可以说我的预测值与实际值是无偏差的,可以说是$cost=0$,但是假如$y=0$,$h_\theta(x)=1$,那么意味着我的预测值与实际值是有很大偏差的,那么就要惩罚学习算法让它的代价变大,于是对应上图就可明白,当横坐标$h_\theta(x)=0$时,曲线确实cost=0,而当$h_\theta(x)=1$时,cost趋于了无穷大。
有时,我们也把上面的函数写成一个表达式:
$$Cost(h_\theta(x)) = -ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))$$
如果x和y变成多维,则代价函数变为:
$$J(\theta) = -{1\over m}[\sum_{i=1}^{m}y^{(i)}log(h_\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)}))]$$
$\color{red}{注意}$:上面是Andrew NG直接给出的cost function,并没有给出推导,这里我把具体的cost function由来给写一下供大家参考:
对于Logistic regression,$h_\theta(x)$函数代表的是等于1的概率,所以有如下的条件概率分布:
$$P(Y=1|x) = {1\over 1 + e^{-\theta^Tx}} = h_\theta(x)$$
$$P(Y=0|x) = 1-{1\over 1 + e^{-\theta^Tx}} = 1 - h_\theta(x)$$
那么将两个式子合并起来写在一起就是:
$$P(Y|x) = h_\theta(x)^y(1-h_\theta(x))^{1-y}$$
对上面这个式子求似然函数:
$$L(\theta) = \prod_{i=1}^{m}{P(Y_i|x_i)} = \prod_{i=1}^{m}{h_\theta(x_i)^{y_i}(1-h_\theta(x_i))^{1-y_i}}$$
在对上面的似然函数求对数为:
$$l(\theta) = logL(\theta) = \sum_{i=1}^{m}[{y_ilogh_\theta(x_i)+(1-y_i)log(1-h_\theta(x_i))}]$$
如果想求最优解则对上式求极大值时下的$\theta$,则此时运用的是梯度上升法,但是在Andrew NG的课程中使用的是梯度下降算法,故有:
$$J(\theta) = -{1\over m}l(\theta) = -{1\over m}[\sum_{i=1}^{m}y^{(i)}log(h_\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)}))]$$即为所求。
选择题2:
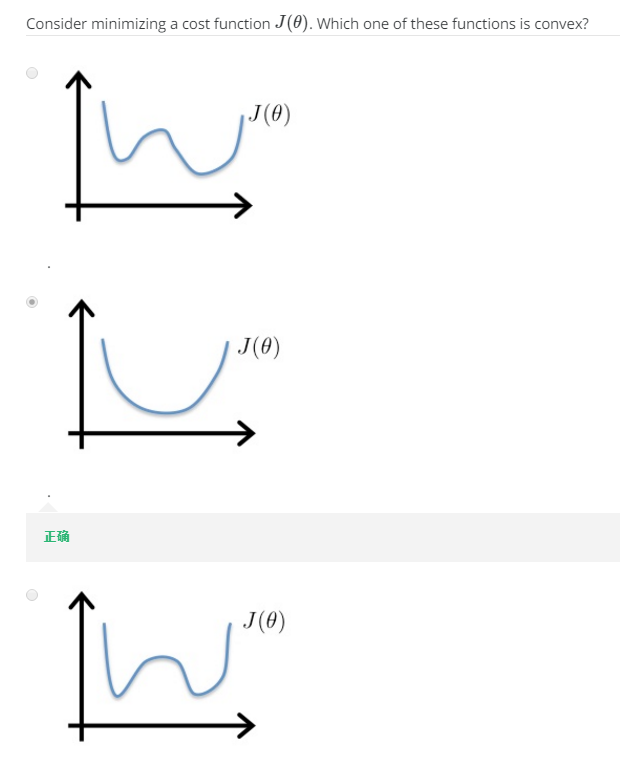
选择题3:

梯度下降

选择题4:

选择题5:

解析
- 也可写成如下


优化梯度下降算法

在Octave中,用此方法来替代梯度下降算法,因为此优化算法不用人为指定conjugate:
- 不需进行学习速率$\alpha$,所以可以将此算法看成是加强版的选择。
- 通常比梯度下降算法快。
选择题6:
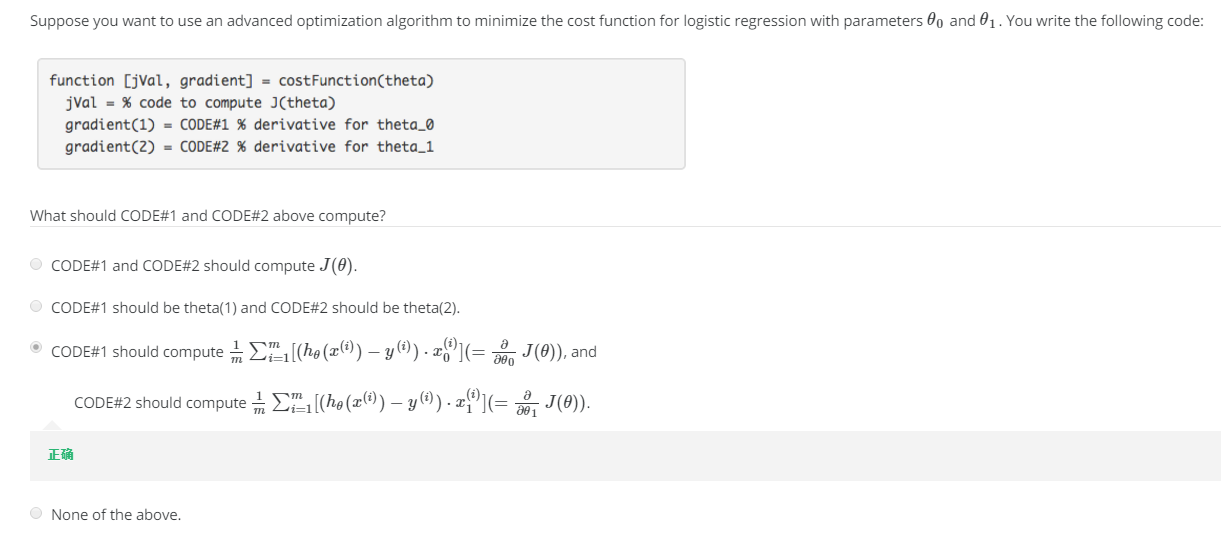
多分类
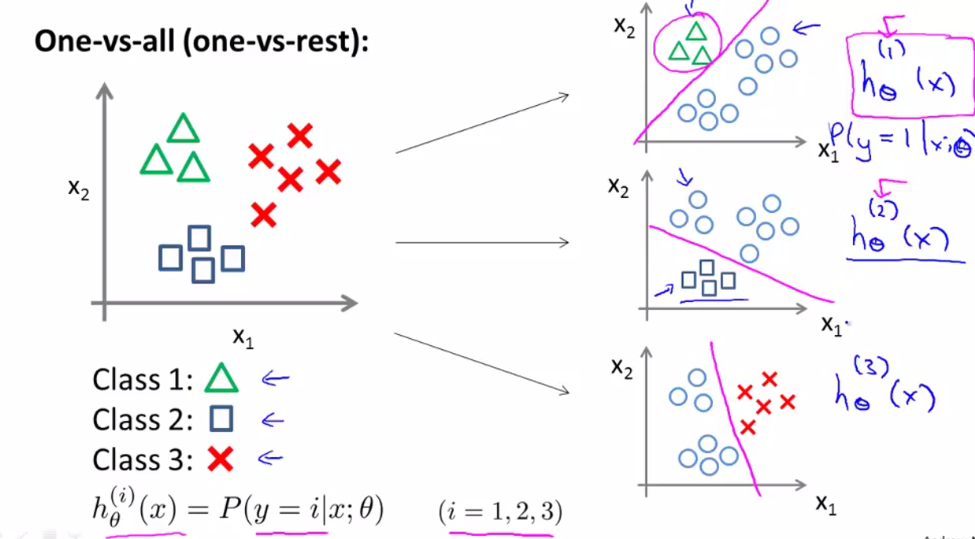
多分类的一种方法是采用“one-vs-all”的方法将多种类别区分:具体思想是针对每一个类别可以训练分类器以区分是否为该类,这样如果有$k$个类别,那么就会训练出$k$个模型。

然后如果想要预测$test$到底为哪一类别时,将$test$分别输入到这$k$个模型中,哪一类的输出概率最大就分类为哪一类。
选择题7:
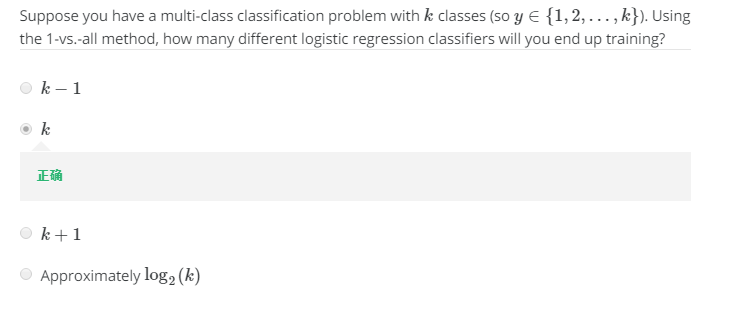
小节测试题1:

小节测试题2:
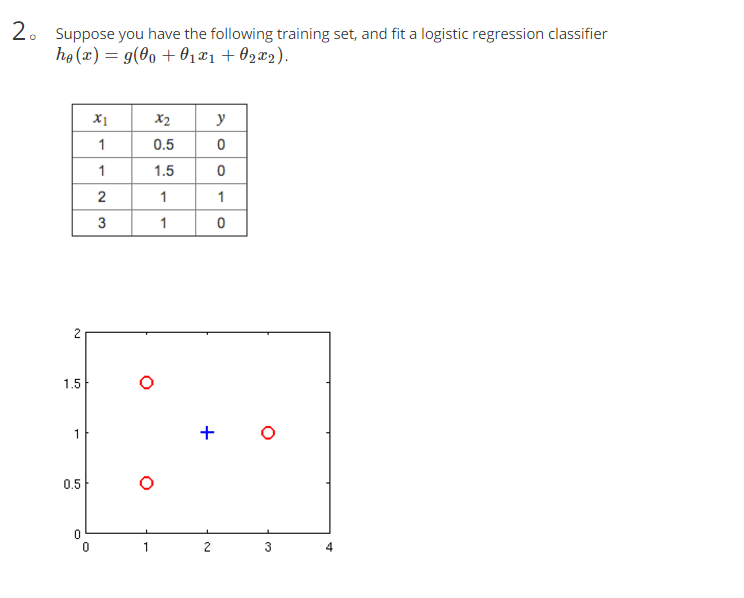

小节测试题3:

小节测试题4:

小节测试题5:
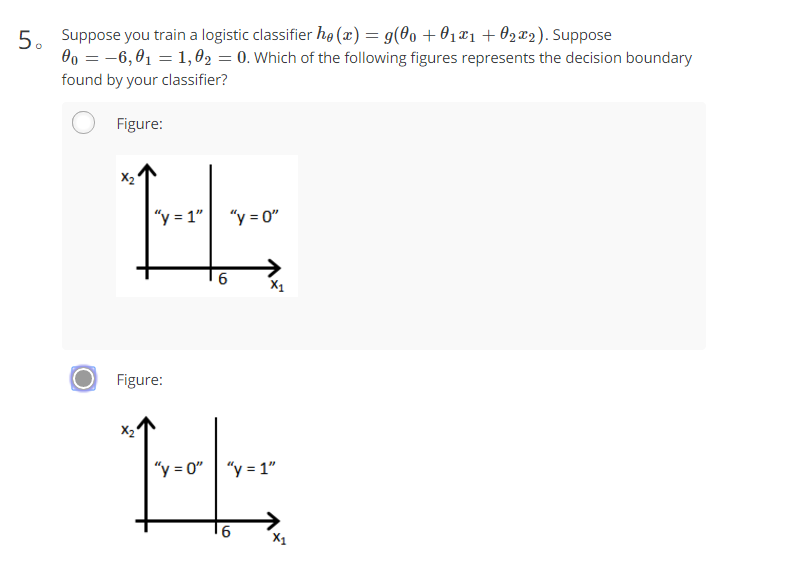
解析
- 线性回归是用来拟合数据对数据进行预测属于回归,但是逻辑回归是用来分类的属于分类。而区分类别是根据$h_\theta(x)$与0.5的关系,也就是$\theta^Tx$与0的关系,所以题中的$\theta^Tx$即为$-x+6$,所以当$x-6>0$时为$y=1$类,反之为$y=0$类。
- 但是算法复杂。
### 多分类
解决过拟合问题
过拟合
产生过拟合问题的原因:数据集的特征非常多并且数据集很小。
选择题1:

如何解决过拟合:
1、减少特征的数量
- 手动的选择要保留的特征。
- 模型选择算法(会自动的选择要保留的特征,之后会讲到)
2、正则化
- 保留所有的特征,并减小$\theta_j$的值或数量级
带正则化项的cost function

如图所示,将之前的cost function加上一个正则化项:
$$J(\theta)={1\over2}[\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_{j=1}^{n}\theta_j^2]$$
注意到,后面的正则项是从$j=1$开始的,不包括$\theta_0$。参数$\lambda$叫做正则化项参数,用来减小$\theta_j$的值,当$\lambda$很大时,$\theta_j$都会变得很小。所以就相当于只剩下$\theta_0$了。

选择题2:

带有正则化项的线性回归
- 在梯度下降方法中
如图,

在带有正则项的线性回归的梯度下降中,可以将$\theta$的更新分成两部分,一部分是$\theta_0$,另一部分是$\theta_j,j=1,2,3...$,而后者可以等价于:
$$\theta_j = \theta_j(1-\alpha{\lambda\over m})-\alpha{1\over m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}$$
选择题3:

- 在正规方程中

在正规方程中,正则化项为一个$(n+1)*(n+1)$的矩阵。
带有正则项的逻辑回归
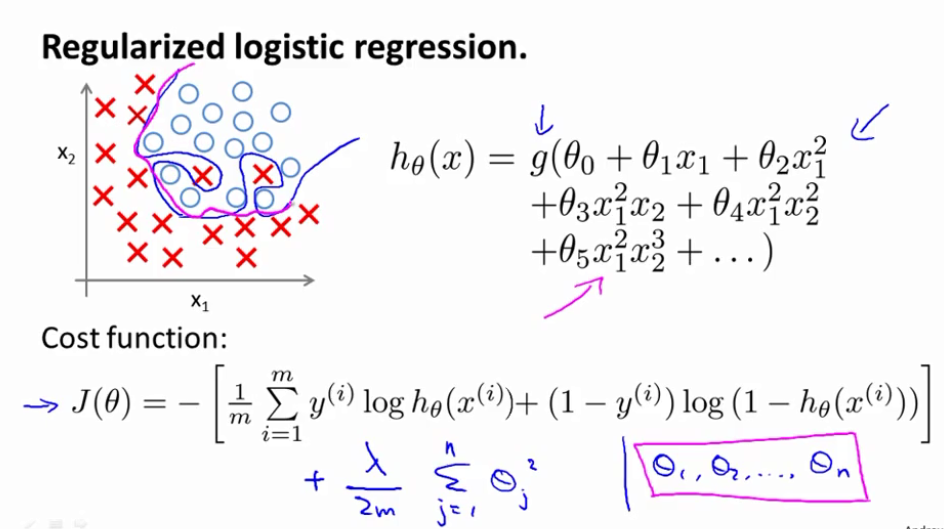
在逻辑回归中,cost function带有了正则项后就变成这样:
$$J(\theta)=-[{1\over m}\sum_{i=1}^{m}y^{(i)}logh_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+{\lambda\over 2m}\sum_{j=1}^{n}\theta_j^2$$
于是,随后的计算梯度就变成了这样,但一定要注意的是$\color{red}{j=0}$与$\color{red}{j=1}$是不同的。
${\partial J(\theta)\over \partial\theta_0} = {1\over m}\sum_{i=1}^m{(h_\theta(x^{(i)})-y^{(i)})}x_j^{(i)}$ $\color{red}{for\ j=0}$
${\partial J(\theta)\over \partial\theta_0} = ({1\over m}\sum_{i=1}^m{(h_\theta(x^{(i)})-y^{(i)})}x_j^{(i)})+{\lambda\over m}\theta_j$ $\color{red}{for\ j>=1}$
选择题4:
