2.2 NoSQL数据库也缺少联系
图数据库
大多数NoSQL数据库—无论是键值数据库、文档数据库,还是基于列的数据库—存储的都是无关联的文档/值/列,因此很难将它们用于关联数据和图。
对这些数据库来说,一种广为认知的添加联系的策略是在某个聚合数据(aggregate)中嵌入另一个聚合数据标识符,即添加外键。然而这需要在应用层连接聚合数据,其代价极速增加。
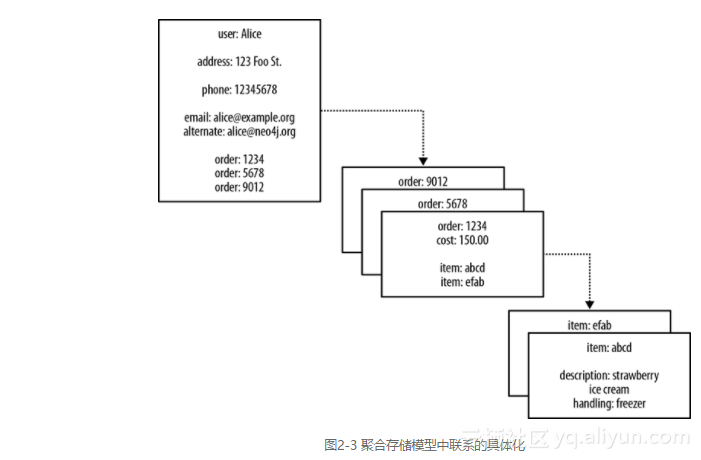
当我们着眼于聚合存储模型(aggregate store model)时,如图2-3所示,我们联想到了联系。看到开头为user: Alice的记录中有对订单的引用order: 1234时,我们推断user: Alice和order: 1234之间存在关联。而这给了我们错误的希望:我们可以使用键值对来管理图。
在图2-3中,我们看到一些属性值确实引用了数据库中其他的聚合数据。然而将这些引用转化为可导航的结构并非是没有代价的,因为聚合数据之间的联系并非数据模型中的一等公民—多数聚合存储只是以内嵌映射结构的方式装饰在聚合数据之内。相反,应用程序使用数据库时必须从这种扁平的、无关联的数据结构中建立起联系。我们还必须确保应用程序能够随着剩余数据的变化更新或删除外部聚合引用,假如不这样做,存储将积累无用的引用,从而破坏数据的质量和查询性能。
Riak中的指针(Links)和查找(Walking)
Riak键值存储引擎允许使用指针(Link)元数据去扩展每个存储的值。指针都是单向的,从一个存储的值指向另一个。Riak允许查找(Walk)(Riak术语)任何数量的指针,从而一定程度上将数据模型关联起来。然而,Riak的指针查找是通过map-reduce驱动的,这一定程度上会有延迟。与图数据库不同,这种指针的连接仅适用于简单的图结构编程,对于通用的图算法就不适用了。
这种方案还有另一个弱点。由于没有反向指针(当然,外部聚合引用的指针不是自反的),数据库丧失了运行其他有趣的查询的能力。比如在图2-3中,想要知道是谁买了某种商品(也许问这个问题的目的是想要基于客户资料进行推荐)就是一个代价高昂的操作。想要回答这类问题,我们可能得通过导出数据集并在外部计算框架(如Hadoop)上运行它们来暴力地获得结果。或者只能回过头将外部聚合引用反向插入,随后才能查询结果。无论哪种方法,结果都不是直接的,都是潜在的。
人们很容易认为聚合存储和图数据在关联数据这方面的功能是等同的。但其实不是这样的。聚合存储并不维护关联数据的一致性,也不提供免索引邻接(index-free adjacency),即元素直接与其邻居相连。因此未解决数据关联问题,聚合存储必须使用天生的潜在的方法在数据模型之外创建和查询联系。
让我们看看它们的局限性是如何表现的。图2-4展示了一个使用聚合存储来实现文档存储的小型社交网络。
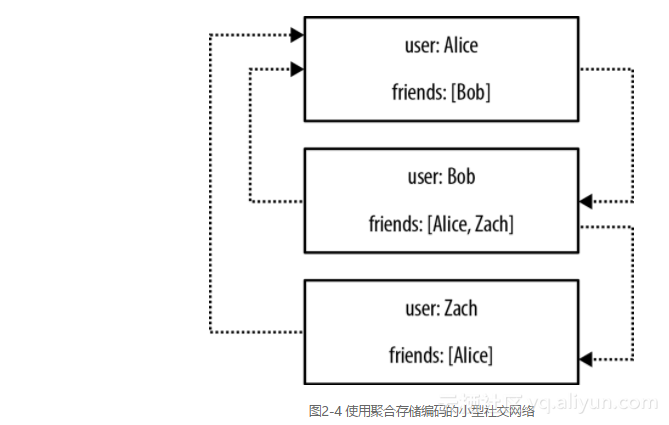
通过这种结构,可以很容易地找到用户的直接朋友—假设应用程序一直在努力确保存储在friends属性中的标识符与数据库中的其他记录的ID保持一致。在这种情况下,我们可以简单地通过它们的ID检索直接朋友,这需要对每个朋友进行大量索引查找,但不需要对整个数据集暴力扫描。这样做我们会发现,Bob认为Alice和Zach是他的朋友。
但朋友关系不总是自反的。如果我们想问问“谁的朋友是Bob?”而不是“谁是Bob的朋友?”,问题就比较难以回答了。在这种情况下,我们唯一的选择是暴力扫描整个数据集,从而在所有friends条目中寻找到包含Bob的条目。
O符号和暴力计算
我们用O符号作为描述一个算法的性能随数据集的大小而变化的简写方式。O(1)算法表示性能的时间复杂度为常数时间,也就是说,该算法与数据集大小无关,无论数据集大小如何,执行算法所花时间都是相同的。O(n)算法表示性能的时间复杂度为线性时间,当数据集增加一倍,执行算法所花时间也会增加一倍。O(log n)算法表示性能的时间复杂度为对数时间,当数据集增加一倍,执行算法所花时间增加一个固定的量。在起步阶段,随着数据集的增大,其所花时间的增加相对很多,但数据集变得非常大的时候,时间的增加会渐渐消失趋于稳定。O(m log n)算法表示的时间复杂度是本书所考虑的最差情况。在O(m log n)的算法中,当数据集增加一倍时,执行时间会在加倍的同时有额外的增加,其增加量与数据集中元素数目成正比。
暴力计算整个数据集的时间复杂度是O(n),因为在数据存储中所有的即n个聚合数据都需要加以考虑。这对于大多数合理规模的数据集来说代价过高,在这里我们要选择一个时间复杂度为O(log n)的算法(这很大程度上是高效的,因为它在每次迭代时能够丢弃掉一半的潜在工作量)或者复杂度更低的算法。
相反,图数据库对于同一个查询提供恒定的查找顺序。在这种情况下,我们只需在图中找到表示Bob的节点,然后寻找任何friend的入度联系,这些联系连接的节点表示那些认为Bob是他们的朋友的人。这比暴力扫描的代价小得多,因为它只和网络中很少的节点相关,即,那些和Bob关联的节点。当然,如果所有人都认为Bob是他们的朋友,我们还是会遍历到整个数据集。
为了避免处理整个数据集,我们可以增加反向指针,但这会反规范化存储模型。通过为每个用户添加另一个属性,也许可以称为friended_by,我们可以列出与该用户相关联的入度朋友关系。但这不是没有代价的。对于起点数据,我们要因写入延迟增加初始成本和后续成本,还要为存储额外的元数据增加磁盘使用开销。最重要的是,因为每一跳(hop)都需要通过一次索引查找,所以遍历指针的代价仍然很高。这是因为聚合数据没有局部性这个概念,它不像图数据库那样通过真实的(而不是具体化的)联系自然地提供免索引邻接。如此,通过实现图结构之上的非原生存储,我们获得了局部连通性的好处,但却引入了巨大的开销。
当遍历涉及比一跳更深的时候,这种巨大的开销被放大了。朋友关系是足够简单的,然而想象一下,当试图实时地计算朋友的朋友,或是朋友的朋友的朋友时,这类数据库就不合时宜了,因为遍历一个虚假的联系的代价并不小。这不仅限制了你扩大社交网络的机会,也减少了有益的推荐,错过数据中心的故障设备,并让欺诈采购活动成为漏网之鱼。许多系统试图去维护类图的计算处理,但仍很难避免要分批处理,并不能按照用户需求提供实时的交互。
本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。