3.5 持久化与缓存
Spark 的一个独特功能是在内存中持久化 RDD。你可以使用 persist 或 cache 变换来持久化 RDD,如下所示:
上述两个语句都是相同的,并且会在 MEMORY_ONLY 存储级别缓存数据。它们的区别在于:cache 是指 MEMORY_ONLY 存储级别,而 persist 可以根据需要选择不同的存储级别,如下表所示。当第一次使用动作来进行计算时,它将保存在节点上的内存中。了解缓存 RDD 的百分比及其大小的最简单方法是检查管理界面中的 Storage 选项卡,如图3-11 所示:
图3-11 缓存的 RDD:缓存的百分比和大小
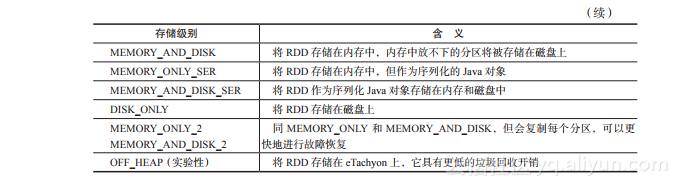
3.5.1 存储级别
根据应用需求的需要,RDD 可以用不同的存储级别来存储。下表显示了 Spark 的存储级别及其含义。
3.5.2 应该选择哪个存储级别
Spark 的各个存储级别在内存占用和 CPU 效率之间提供不同的权衡。你可以按照下面的过程选择其中一个:
如果整个 RDD 能放进内存中,请选择 MEMORY_ONLY。
使用 MEMORY_ONLY_SER 以获得更好的紧凑性和更好的性能。这对 Python 并不重要,因为它的对象总是会用 pickle 库序列化。
如果重新计算比从磁盘读取的开销更大,请使用 MEMORY_AND_DISK。
不要复制 RDD 存储,除非你需要快速的故障恢复。
时间: 2024-12-24 02:02:25