
作者经过研发多个大数据产品,将自己形成关于大数据知识体系的干货分享出来,希望给大家能够快速建立起大数据产品的体系思路,让大家系统性学习和了解有关大数据的设计架构。
很多人都看过不同类型的书,也接触过很多有关大数据方面的文章,但都是很零散不成系统,对自己也没有起到多大的作用,所以作者第一时间,带大家从整体体系思路上,了解大数据产品设计架构和技术策略。
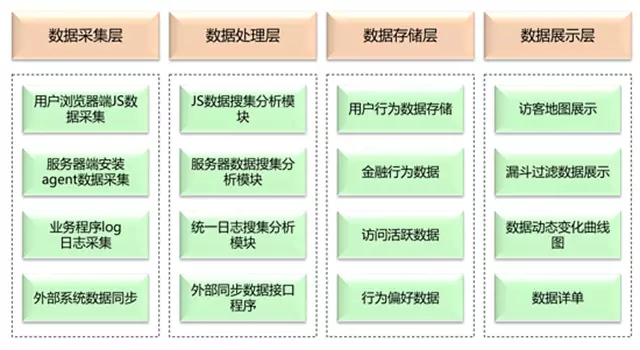
大数据产品,从系统性和体系思路上来做,主要分为五步:
针对前端不同渠道进行数据埋点,然后根据不同渠道的采集多维数据,也就是做大数据的第一步,没有全量数据,何谈大数据分析;
第二步,基于采集回来的多维度数据,采用ETL对其各类数据进行结构化处理及加载;
然后第三步,对于ETL处理后的标准化结构数据,建立数据存储管理子系统,归集到底层数据仓库,这一步很关键,基于数据仓库,对其内部数据分解成基础的同类数据集市;
然后基于归集分解的不同数据集市,利用各类R函数包对其数据集进行数据建模和各类算法设计,里面算法是需要自己设计,个别算法可以用R函数,这个过程产品和运营参与最多;这一步做好了,也是很多公司用户画像系统的底层。
最后根据建立的各类数据模型及算法,结合前端不同渠道不同业务特征,根据渠道触点自动匹配后端模型自动展现用户个性化产品和服务。
建立系统性数据采集指标体系
建立数据采集分析指标体系是形成营销数据集市的基础,也是营销数据集市覆盖用户行为数据广度和深度的前提,数据采集分析体系要包含用户全活动行为触点数据,用户结构化相关数据及非结构化相关数据,根据数据分析指标体系才能归类汇总形成筛选用户条件的属性和属性值,也是发现新的营销事件的基础。
构建营销数据指标分析模型,完善升级数据指标采集,依托用户全流程行为触点,建立用户行为消费特征和个体属性,从用户行为分析、商业经营数据分析、营销数据分析三个维度,形成用户行为特征分析模型。用户维度数据指标是不同维度分析要素与用户全生命周期轨迹各触点的二维交叉得出。
目前做大数据平台的公司,大多数采集的数据指标和输出的可视化报表,都存在几个关键问题:
- 采集的数据都是以渠道、日期、地区统计,无法定位到具体每个用户;
- 计算统计出的数据都是规模数据,针对规模数据进行挖掘分析,无法支持;
- 数据无法支撑系统做用户获客、留存、营销推送使用;
所以,要使系统采集的数据指标能够支持平台前端的个性化行为分析,必须围绕用户为主线来进行画像设计,在初期可视化报表成果基础上,将统计出来的不同规模数据,细分定位到每个用户,使每个数据都有一个用户归属。
将分散无序的统计数据,在依据用户来衔接起来,在现有产品界面上,每个统计数据都增加一个标签,点击标签,可以展示对应每个用户的行为数据,同时可以链接到其他统计数据页面。
由此可以推导出,以用户为主线来建立数据采集指标维度:用户身份信息、用户社会生活信息、用户资产信息、用户行为偏好信息、用户购物偏好、用户价值、用户反馈、用户忠诚度等多个维度,依据建立的采集数据维度,可以细分到数据指标或数据属性项。
① 用户身份信息维度
性别,年龄,星座,居住城市,活跃区域,证件信息,学历,收入,健康等。
② 用户社会生活信息维度
行业,职业,是否有孩子,孩子年龄,车辆,住房性质,通信情况,流量使用情况……
③ 用户行为偏好信息
是否有网购行为,风险敏感度,价格敏感度,品牌敏感度,收益敏感度,产品偏好,渠道偏好……
④ 用户购物偏好信息
品类偏好,产品偏好,购物频次,浏览偏好,营销广告喜好,购物时间偏好,单次购物最高金额……
⑤ 用户反馈信息维度
用户参与的活动,参与的讨论,收藏的产品,购买过的商品,推荐过的产品,评论过的产品……
基于采集回来的多维度数据,采用ETL对其各类数据进行结构化处理及加载
数据补缺:对空数据、缺失数据进行数据补缺操作,无法处理的做标记。
数据替换:对无效数据进行数据的替换。
格式规范化:将源数据抽取的数据格式转换成为便于进入仓库处理的目标数据格式。
主外键约束:通过建立主外键约束,对非法数据进行数据替换或导出到错误文件重新处理。
数据合并:多用表关联实现(每个字段加索引,保证关联查询的效率)
数据拆分:按一定规则进行数据拆分
行列互换、排序/修改序号、去除重复记录
数据处理层 由 hadoop集群 组成 , Hadoop集群从数据采集源读取业务数据,通过并行计算完成业务数据的处理逻辑,将数据筛选归并形成目标数据。
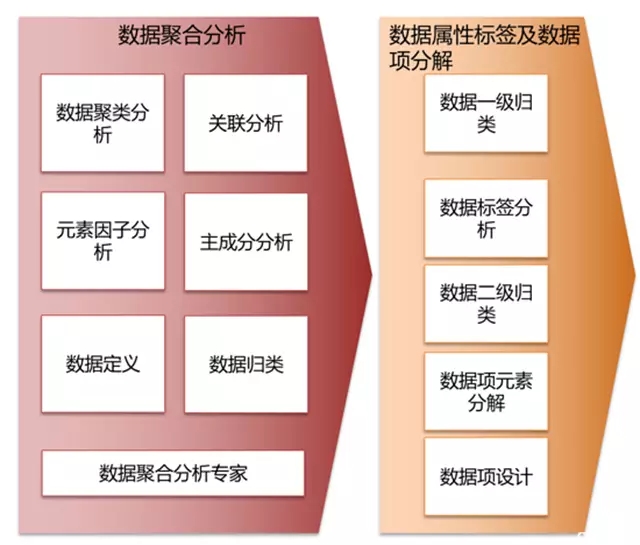
数据建模、用户画像及特征算法
提取与营销相关的客户、产品、服务数据,采用聚类分析和关联分析方法搭建数据模型,通过用户规则属性配置、规则模板配置、用户画像打标签,形成用户数据规则集,利用规则引擎实现营销推送和条件触发的实时营销推送,同步到前端渠道交互平台来执行营销规则,并将营销执行效果信息实时返回到大数据系统。
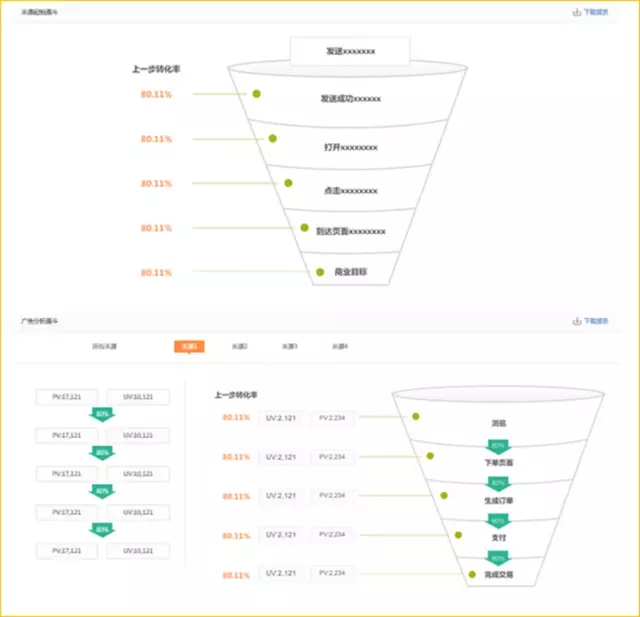
根据前端用户不同个性化行为,自动匹配规则并触发推送内容
根据用户全流程活动行为轨迹,分析用户与线上渠道与线下渠道接触的所有行为触点,对营销用户打标签,形成用户行为画像,基于用户画像提炼汇总营销筛选规则属性及属性值,最终形成细分用户群体的条件。每个用户属性对应多个不同属性值,属性值可根据不同活动个性化进行配置,支持用户黑白名单的管理功能。
可以预先配置好基于不同用户身份特性的活动规则和模型,当前端用户来触发配置好的营销事件,数据系统根据匹配度最高的原则来实时自动推送营销规则,并通过实时推送功能来配置推送的活动内容、优惠信息和产品信息等,同时汇总前端反馈回的效果数据,对推送规则和内容进行优化调整。
大数据系统结合客户营销系统在现有用户画像、用户属性打标签、客户和营销规则配置推送、同类型用户特性归集分库模型基础上,未来将逐步扩展机器深度学习功能,通过系统自动搜集分析前端用户实时变化数据,依据建设的机器深度学习函数模型,自动计算匹配用户需求的函数参数和对应规则,营销系统根据计算出的规则模型,实时自动推送高度匹配的营销活动和内容信息。
机器自学习模型算法是未来大数据系统深度学习的核心,通过系统大量采样训练,多次数据验证和参数调整,才能最终确定相对精准的函数因子和参数值,从而可以根据前端用户产生的实时行为数据,系统可自动计算对应的营销规则和推荐模型。
大数据系统在深度自学习外,未来将通过逐步开放合作理念,对接外部第三方平台,扩展客户数据范围和行为触点,尽可能覆盖用户线上线下全生命周期行为轨迹,掌握用户各行为触点数据,扩大客户数据集市和事件库,才能深层次挖掘客户全方位需求,结合机器自学习功能,从根本上提升产品销售能力和客户全方位体验感知。
本文作者:刘永平
来源:51CTO