第3章 Greenplum实战
从本章开始我们结合实际需求,阐述一下日常项目开发中如何结合Greenplum的特性进行高效的开发,展现出Greenplum在海量数据分析中的优势。
本章将介绍两个完整的例子:数据仓库拉链记历史和网页浏览日志分析。在这两个例子中,会结合Greenplum的一些特性加以描述,之后会介绍使用Greenplum中要注意的一些特性,以及这些特性对性能的影响。
3.1 历史拉链表
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。由于需要反映历史变化,数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
历史拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的。顾名思义,所谓历史拉链表,就是记录一个事物从开始一直到当前状态的所有变化的信息。拉链表可以避免按每一天存储所有记录造成的海量存储问题,同时也是处理缓慢变化数据的一种常见方式。
3.1.1 应用场景描述
现假设有如下场景:一个企业拥有5000万会员信息,每天有20万会员资料变更,我们需要在Greenplum中记录会员表的历史变化以备数据挖掘分析等使用,即每天都要保留一个快照供查询,反映历史数据的情况。在此场景中,需要反映5000万会员的历史变化,如果保留快照,存储两年就需要2×365×5000W条数据存储空间,数据量为365亿,如果存储更长时间,则无法估计需要的存储空间。而用拉链算法存储,每日只向历史表中添加新增和变化的数据量,每日不过20万条,存储4年也只需要3亿存储空间。
接下来我们将概要讲述整个分析实施过程。
3.1.2 原理及步骤
在拉链表中,每一条数据都有一个生效日期(dw_beg_date)和失效日期(dw_end_date)。假设在一个用户表中,在2011年12月1日新增了两个用户,如表3-1所示,则这两条记录的生效时间为当天,由于到2011年12月1日为止,这两条记录还没有被修改过,所以失效时间为无穷大,这里设置为数据库中的最大值(3000-12-31)。
第二天(2011-12-02),用户10001被删除了,用户10002的电话号码被修改成13600000002。为了保留历史状态,用户10001的失效时间被修改为2011-12-02,用户10002则变成两条记录,如表3-2所示。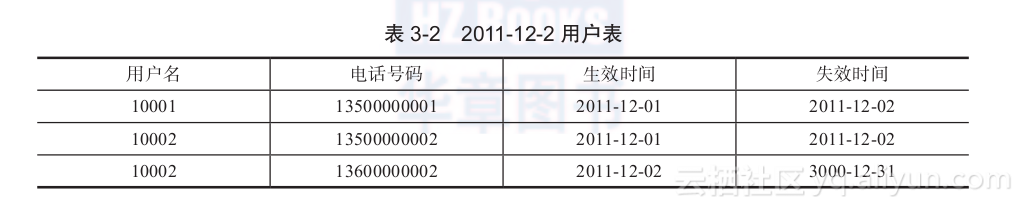
第三天(2011-12-03),又新增了用户10003,则用户表数据如表3-3所示。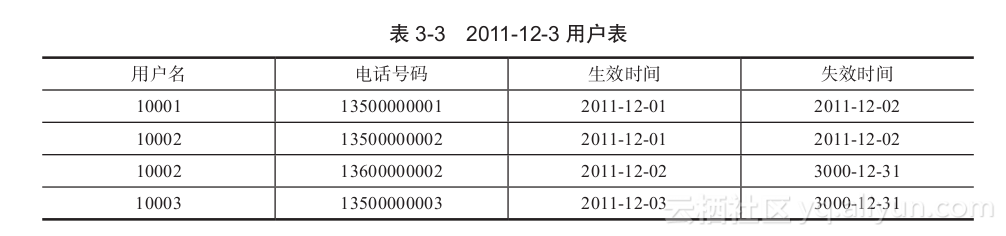
如果要查询最新的数据,那么只要查询失效时间为3000-12-31的数据即可,如果要查询12月1号的历史数据,则筛选生效时间≤2011-12-01并且失效时间>2011-12-01的数据即可。如果查询的是12月2号的数据,那么筛选条件则是生效时间≤2011-12-02 并且失效时间>2011-12-02。读者可对表3-3的数据进行筛选,以检验结果是否正确。
在Greenplum中,则可以利用分区表按照dw_end_date保存时间,这样在查询的时候可以利用Greenplum的分区裁剪,从而减少IO消耗。下面通过图3-1讲解拉链表刷新的步骤,连线代表数据流向,线上的编号就是步骤编号。
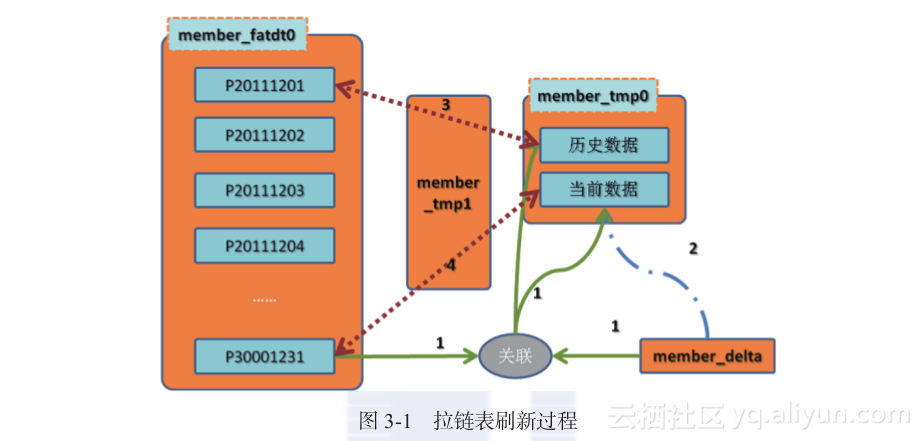
首先介绍每个表的用途。
member_fatdt0:表示member的事实表,其中P30001231保存的是最新数据,每个分区保留的都是历史已失效的数据。
member_delta:当天的数据库变更数据,action字段表示该数据为新增(I)、更新(U)、删除(D)。
member_tmp0:刷新过程中的临时表,这个表有两个分区,分别记录历史数据,即当天失效数据,另一个分区记录的是当前数据。
member_tmp1:同样是刷新过程中的临时表,主要是在交换分区的时候使用。
刷新过程简单来说,就是将前一天的全量数据(分区P30001231)与当天的增量数据进行关联,并对不同的变更类型(action)进行相应的处理,最终生成最新数据,以及当天发生变更的历史数据。后续数据刷新实战中会介绍具体的步骤,下面先从表结构开始介绍。
3.1.3 表结构
- 拉链表(member_fatdt0)结构
member_fatdt0使用member_id作为分布键,使数据尽量打散在每个机器上(参考3.3节数据分布),通过with(appendonly=true,compresslevel=5)指定该表为压缩表,可以减少IO操作(参考3.4节数据压缩),将dw_end_date作为分区字段。建表语句如下:
```javascript
Create table public.member_fatdt0
(
Member_id varchar(64) --会员ID
,phoneno varchar(20) --电话号码
,dw_beg_date date --生效日期
,dw_end_date date --失效日期
,dtype char(1) --类型(历史数据、当前数据)
,dw_status char(1) --数据操作类型(I,D,U)
,dw_ins_date date --数据仓库插入日期
) with(appendonly=true,compresslevel=5)
distributed by(member_id)
PARTITION BY RANGE (dw_end_date)
(
PARTITION p20111201 START (date '2011-12-01') INCLUSIVE ,
PARTITION p20111202 START (date '2011-12-02') INCLUSIVE ,
PARTITION p20111203 START (date '2011-12-03') INCLUSIVE ,
PARTITION p20111204 START (date '2011-12-04') INCLUSIVE ,
PARTITION p20111205 START (date '2011-12-05') INCLUSIVE ,
PARTITION p20111206 START (date '2011-12-06') INCLUSIVE ,
PARTITION p20111207 START (date '2011-12-07') INCLUSIVE ,
PARTITION p30001231 START (date '3000-12-31') INCLUSIVE
END (date '3001-01-01') EXCLUSIVE
);
2. 增量表(member_delta)结构
建表语句如下:
```javascript
Create table public.member_delta
(
Member_id varchar(64) --会员ID
,phoneno varchar(20) --电话号码
,action char(1) --类型 (新增,删除,更新)
,dw_ins_date date --数据仓库插入日期
) with(appendonly=true,compresslevel=5)
distributed by(member_id);
- 临时表0(member_tmp0)结构
dtype为分区字段,H表示历史数据,C表示当前数据,建表语句如下:
```javascript
Create table public.member_tmp0
(
Member_id varchar(64) --会员ID
,phoneno varchar(20) --电话号码
,dw_beg_date date -生效日期
,dw_end_date date --失效日期
,dtype char(1) --类型 (历史数据、当前数据)
,dw_status char(1) --数据操作类型(I,D,U)
,dw_ins_date date --数据仓库插入日期
) with(appendonly=true,compresslevel=5)
distributed by(member_id)
PARTITION BY LIST (dtype)
( PARTITION PHIS VALUES ('H'),
PARTITION PCUR VALUES ('C'),
DEFAULT PARTITION other );
4. 临时表1(member_tmp1)结构
表结构与member_tmp1、member_fatdt0一模一样,建表语句如下:
```javascript
Create table public.member_tmp1
(
Member_id varchar(64) --会员ID
,phoneno varchar(20) --电话号码
,dw_beg_date date --生效日期
,dw_end_date date --失效日期
,dtype char(1) --类型 (历史数据、当前数据)
,dw_status char(1) --数据操作类型(I,D,U)
,dw_ins_date date --数据仓库插入日期
) with(appendonly=true,compresslevel=5)
distributed by(member_id);
3.1.4 Demo数据准备
在这里为了清晰展示整个逻辑,仅以少量demo数据为例。
(1)增量表数据
12月2号增量数据,新增、删除、更新各有一条记录,如表3-4所示。
表3-4 12月2号增量数据
12月3号增量数据,新增、删除、更新各有一条记录,如表3-5所示。
(2)历史表初始数据
初始数据为12月1号,失效日期为3000年12月31号,如表3-6所示。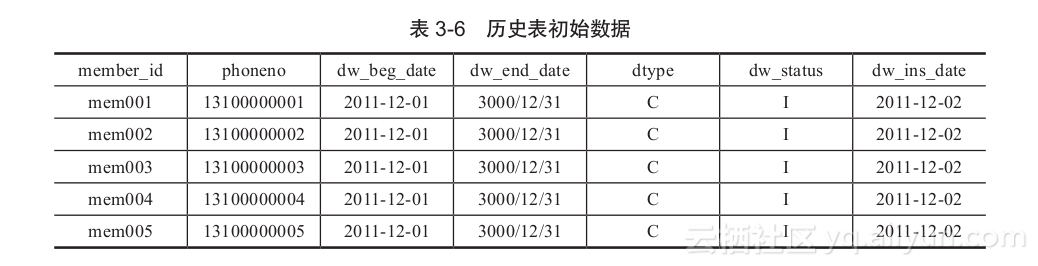
3.1.5 数据加载
Greenplum数据加载主要包括标准SQL的insert、copy、外部表、gpload、web external table几种方式,通过这个例子,将这几种方式一起来向读者介绍一下。
1. insert
这种数据加载方式效率最差,只适合加载极少量数据。这里向12月2号会员增量表中插入数据:
insert into public.member_delta values('mem006','13100000006','I',date'2011-12-03');
insert into public.member_delta values('mem002','13100000002','D',date'2011-12-03');
insert into public.member_delta values('mem003','13800000003','U',date'2011-12-03');
- copy
copy这种数据加载方式源于PostgreSQL,较SQL的 insert方式效率大大提升,但是数据仍然需通过Master节点,无法实现并行高效数据加载。这里向会员历史表加载12月1号开始的初始数据。
我们将数据以逗号分隔,存放在member_his_init.dat文件中,内容如下:
```javascript
mem001,13100000001,2011-12-01,3000-12-31,C,I,2011-12-01
mem002,13100000002,2011-12-01,3000-12-31,C,I,2011-12-01
mem003,13100000003,2011-12-01,3000-12-31,C,I,2011-12-01
mem004,13100000004,2011-12-01,3000-12-31,C,I,2011-12-01
mem005,13100000005,2011-12-01,3000-12-31,C,I,2011-12-01
copy命令如下,指定分隔符还有数据文件。
```javascript
testDB=# copy public.member_fatdt0_1_prt_p30001231 from '/home/gpadmin/member_his_init.dat' with delimiter ',';
COPY 5
- 外部表
外部表在2.3.8节中已经简单介绍过了,首先,启动gpfdist服务:
```javascript
$nohup gpfdist -d /home/gpadmin/data/ -p 8888 -l /home/gpadmin/data/gpfdist.log &
其次,创建外部表:
```javascript
drop external table if exists public.member_ext;
create external table public.member_ext
(
Member_id varchar(64)
,phoneno varchar(20)
,action char(1)
,dw_ins_date date
)
location ('gpfdist://localhost:8888/member_delta.dat')
format 'text'
(delimiter ',' null as '' escape 'off')
encoding 'gb18030'
log errors into member_err segment reject limit 2 rows;
最后,执行数据装载:
testDB=# Insert into public.member_delta select * from public.member_ext;
INSERT 0 3
- gpload
gpload是对外部表的一层封装,详细可参考用户手册,这里直接介绍使用语法,首先,编写gpload控制文件member.yml,代码如下:
```javascript
---
VERSION: 1.0.0.1
DATABASE: testDB
USER: gpadmin
HOST: localhost
PORT: 5432
GPLOAD:
INPUT:
- SOURCE:
LOCAL_HOSTNAME:
- mdw
PORT: 8081
FILE:
- /home/gpadmin/data/member_delta.dat
- COLUMNS:
- Member_id: varchar(64)
- phoneno: varchar(20)
- action: char(1)
- dw_ins_date: date
- FORMAT: text
- DELIMITER: ','
- ERROR_LIMIT: 2
- ERROR_TABLE: public.member_err
OUTPUT:
- TABLE: public.member_delta
- MODE: INSERT
SQL:
- BEFORE: "truncate table public.member_delta"
- AFTER: "analyze public.member_delta"
其次,执行数据加载:
```javascript
$gpload -f member.yml
2012-01-08 14:30:01|INFO|gpload session started 2012-01-08 14:30:01
2012-01-08 14:30:01|INFO|started gpfdist -p 8081 -P 8082 -f "/home/gpadmin/data/member_delta.dat" -t 30
2012-01-08 14:30:09|INFO|running time: 7.85 seconds
2012-01-08 14:30:09|INFO|rows Inserted = 3
2012-01-08 14:30:09|INFO|rows Updated = 0
2012-01-08 14:30:09|INFO|data formatting errors = 0
2012-01-08 14:30:09|INFO|gpload succeeded
最后,验证数据:
testDB=# select * from public.member_delta;
member_id | phoneno | action | dw_ins_date
-----------+-------------+--------+-------------
mem006 | 13100000006 | I | 2011-12-02
mem002 | 13100000002 | D | 2011-12-02
mem003 | 13100000003 | U | 2011-12-02
(3 rows)
- 可执行外部表
可执行外部表会在6.3.4节中介绍,其中基于操作系统命令读取数据文件的方式如下,用法跟普通外部表类似,不过不用启动gpfdist服务,下面的外部表只在Master上执行:
```javascript
drop external web table if exists public.member_ext;
create external web table public.member_ext
(
Member_id varchar(64)
,phoneno varchar(20)
,action char(1)
,dw_ins_date date
)
EXECUTE 'cat /home/gpadmin/data/member_delta.dat' ON master
format 'text'
(delimiter ',' null as '' escape 'off')
encoding 'gb18030'
;
清空member_delta表并插入数据:
```javascript
testDB=# truncate table public.member_delta ;
TRUNCATE TABLE
testDB=# Insert into public.member_delta select * from public.member_ext;
INSERT 0 3
3.1.6 数据刷新
- 拉链表刷新
Step1:对事实表中最新数据(分区P30001231)与member_delta表中的更新、删除数据进行左外连接,关联上则说明该数据已发生过变更,需要将该数据的失效时间更新为当天,并插入到member_tmp0表中的历史数据分区中,关联不上则说明没有发生过变更,需要将该数据插入到member_tmp0表的当前数据分区中。Greenplum会根据dtype的数据自动选择对应的分区。
初始全量数据为2011-12-01号,在12月3号刷新12月2号增量数据,代码如下:
```javascript
truncate table public.member_tmp0;
```javascript
--清理临时表
INSERT INTO public.member_tmp0
(
Member_id
,phoneno
,dw_beg_date
,dw_end_date
,dtype
,dw_status
,dw_ins_date
)
SELECT a.Member_id
,a.phoneno
,a.dw_beg_date
,CASE WHEN b.Member_id IS NULL THEN a.dw_end_date
ELSE date'2011-12-02'
END AS dw_end_date
,CASE WHEN b.Member_id IS NULL THEN 'C'
ELSE 'H'
END AS dtype
,CASE WHEN b.Member_id IS NULL THEN a.dw_status
ELSE b.action
END AS dw_status
,date'2011-12-03'
FROM public.member_fatdt0 a
left join public.member_delta b
ON a.Member_id=b.Member_id
AND b.action IN('D','U')
WHERE a.dw_beg_date<=cast('2011-12-02' as date)-1
AND a.dw_end_date>cast('2011-12-02' as date)-1;
Step2:将member_delta的新增、更新数据插入到member_tmp0表的当前数据分区中。
INSERT INTO public.member_tmp0
(
Member_id
,phoneno
,dw_beg_date
,dw_end_date
,dtype
,dw_status
,dw_ins_date
)
SELECT Member_id
,phoneno
,cast('2011-12-02' as date)
,cast('3000-12-31' as date)
,'C'
,action
,cast('2011-12-03' as date)
FROM public.member_delta
WHERE action IN('I','U');
Step3:将member_fatdt0表中的对应分区(P20121201)与member_tmp0表的历史数据分区交换。
Truncate table public.member_tmp1;
alter table public.member_tmp0 exchange partition for('H') with table public.member_tmp1;
alter table public.member_fatdt0 exchange partition for('2011-12-02') with table public.member_tmp1;
Step4:将member_fatdt0表中对应的当前数据分区(p30001231)与member_tmp0表的当前数据分区交换。
alter table public.member_tmp0 exchange partition for('C') with table public.member_tmp1;
alter table public.member_fatdt0 exchange partition for('3000-12-31') with table public.member_tmp1;
至此,拉链表数据刷新完成,数据验证如图3-2所示。
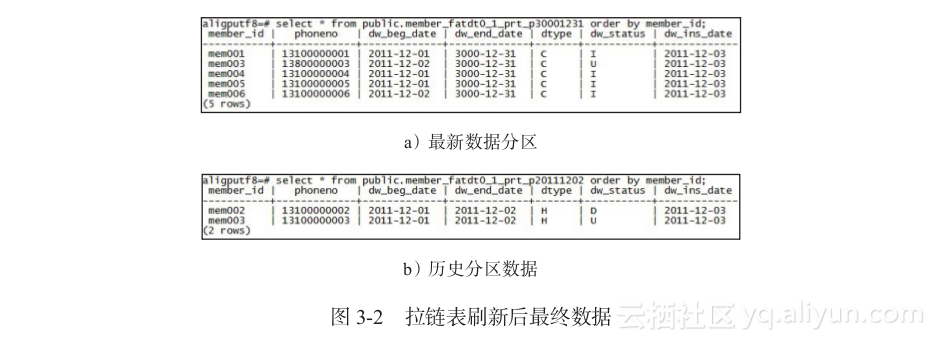
同样,更新对应的日期,可以刷新3号的增量数据。
2. 历史数据查询
基于拉链表,我们可以回溯到历史上任意一天的数据状态。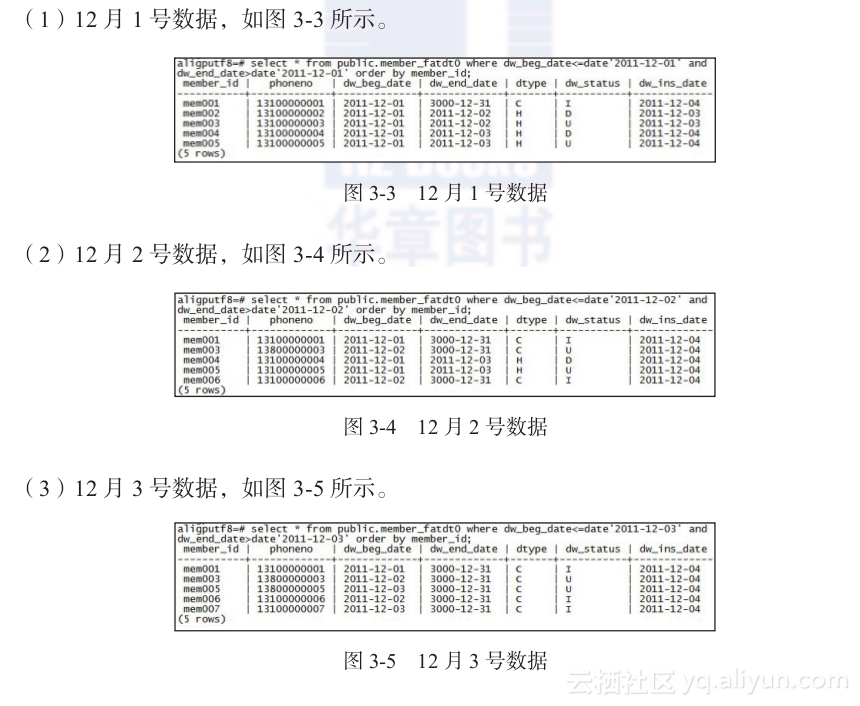
3.1.7 分区裁剪
下面通过查看执行计划(第5章讲详细介绍执行计划)来介绍Greenplum的分区表的功能。
全表扫描的执行计划如下:
testDB=# explain select * from public.member_fatdt0;
QUERY PLAN
-----------------------------------------------------------------------------
Gather Motion 6:1 (slice1; segments: 6) (cost=0.00..108.40 rows=1708 width=36)
-> Append (cost=0.00..108.40 rows=1708 width=36)
-> Append-only Scan on member_fatdt0_1_prt_p20111201 member_fatdt0 (cost=0.00..0.00 rows=1 width=232)
-> Append-only Scan on member_fatdt0_1_prt_p20111202 member_fatdt0 (cost=0.00..0.00 rows=1 width=232)
-> Append-only Scan on member_fatdt0_1_prt_p20111203 member_fatdt0 (cost=0.00..0.00 rows=1 width=232)
…
-> Append-only Scan on member_fatdt0_1_prt_p30001231 member_fatdt0 (cost=0.00..108.40 rows=1707 width=3
5)
(10 rows)
通过执行计划可以看出,Greenplum扫描了所有的分区。当加入筛选条件dw_end_date='3000-12-31'时,执行计划如下:
testDB=# explain select * from public.member_fatdt0 where dw_end_date='3000-12-31';
QUERY PLAN
---------------------------------------------------------------
Gather Motion 6:1 (slice1; segments: 6) (cost=0.00..134.00 rows=1707 width=35)
-> Append (cost=0.00..134.00 rows=1707 width=35)
-> Append-only Scan on member_fatdt0_1_prt_p30001231 member_fatdt0 (cost=0.00..134.00 rows=1707 width=35)
Filter: dw_end_date = '3000-12-31'::date
(4 rows)
这时,分区裁剪发生了作用,只扫描了P30001231这个分区。
3.1.8 数据导出
Greenplum在处理大数据量数据导出时常用的方式主要有并行导出(可写外部表)和非并行导出(COPY),copy命令比较简单,就不细说了。下面我们分别简单介绍下可写外部表数据导出方式,通过gpfdist可写外部表将数据导出至文件服务器。
1)创建可写外部表:
testDB=# CREATE WRITABLE EXTERNAL TABLE member_tmp1_unload
testDB-# ( LIKE member_tmp1 )
testDB-# LOCATION ('gpfdist://localhost:8080/member_tmp1.dat')
testDB-# FORMAT 'TEXT' (DELIMITER ',')
testDB-# DISTRIBUTED BY (member_id);
CREATE EXTERNAL TABLE
WRITABLE关键字表示该外部表是可写外部表;Like语句表示创建的外部表的表结构与member_tmp1表结构一样;LOCATION指定gpfdist的机器名跟端口,还有保存的文件名;FORMAT为导出文件格式定义。
2)执行数据导出:
testDB=# insert into member_tmp1_unload select * from member_tmp1;
INSERT 0 5
跟普通insert语句一样,只需要将数据插入外部表即可。
3)验证生成的文件:
$less member_tmp1.dat
mem004,13100000004,2011-12-01,3000-12-31,C,I,2011-12-03
mem006,13100000006,2011-12-02,3000-12-31,C,I,2011-12-03
mem001,13100000001,2011-12-01,3000-12-31,C,I,2011-12-03
mem005,13100000005,2011-12-01,3000-12-31,C,I,2011-12-03
mem003,13800000003,2011-12-02,3000-12-31,C,U,2011-12-03
$