![]()
对于 JavaScript 使用的是 UCS-2 还是 UTF-16 这个问题,我找了很久,没有发现一个权威的回答,我决定自己研究一下它。这个回答来自于你对 JavaScript 引擎或者对 JavaScript 语言的理解。
一、著名的 BMP(Basic Multilingual Plane)
Unicode 标识符通过一个明确的名字和一个整数来作为它的码位(code point).比如,“” 字符的码位可以用“版权标志”和U+00A9(0xA9,也可以写作十进制 169)来表示。
Unicode 字符分为 17 组平面,每个平面拥有 2^16
(65,536)个码位.有一些码位没有分配字符,也有一些码位被保留,成为私有的,也有一些码位是永远被保留的,作为无字符的标志。每一个码位都可以用
16 进制 xy0000 到 xyFFFF 来表示,这里的 xy 是表示一个 16 进制的值,从 00 到 10。
这第一个位置(当 xy 是 00 的时候)被称为 BMP (基本多文种平面, Basic Multilingual Plane)。它包含了最常用的码位从 U+0000 到 U+FFFF。
这里需要补充一点额外的平面知识,以及术语的表格。
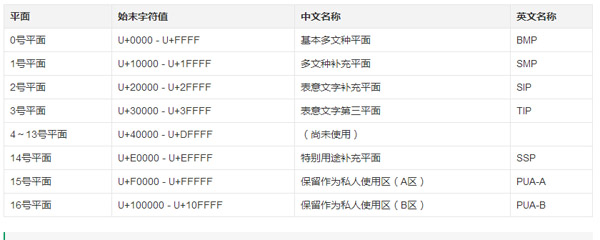
引用自:wikipedia
其余 16号平面(U+100000 到 U+10FFFF)称为补充的平面。这里我将不讨论它;只需要记住两个概念:BMP 字符和非 BMP 字符,后者也被称为补充字符。
二、UCS-2 和 UTF-16 之间的不同
UCS-2 和 UTF-16 都是 Unicode 的字符编码方式。
UCS-2(2个字节的通用字符集)是一种固定长度的编码格式,只需要使用编码为 16 字节编码单元来表示码位。这样的表示结果将和 UTF-16 在 0 到 0xFFFF (BMP)范围内大多数的结果一样。
UTF-16(16 位 Unicode 转换格式)是对 UCS-2 的一个扩展,它允许表示比 BMP
范围内更多的字符。它是一种可变长度格式,它的每个码位能够使用 1 位或者 2 位 16字节编码单元来表示。这种方式能够编码的码位在 0 到
0x10FFFF 之间。
比如,在 UCS-2 和 UTF-16 中,对于 BMP 字符 U+00A9 版权标志()都能被编码为:0x00A9。
这里补充一下 UCS-2、UCS-4、BMP
CPU 处理多字节数的方式分为:“大尾”(big endian)和“小尾”(little endian),简单的理解就是一个 Unicode 编码,比如6C49,写到文件里面 6C 49 或者 49 6C,两种方式,前者就叫“大尾”,后者就叫“小尾”。
UCS 可以分为两种格式:UCS-2 和 UCS-4。UCS-2 使用两个字节编码,UCS-4 使用4个字节(实际只有 31 位,最高位必须是 0)编码。
转换关系:UCS-4 中高两个字节为 0 的码位称为 BMP;UCS-4 的 BMP 去掉前面两个零字节就得到 UCS-2;UCS-2 加上两个零字节就得到 UCS-4 中的 BMP。
三、代理对(Surrogate pairs)
对于 BMP 之外的字符,比如 U+1D306 四条线居中(其实不好翻译:tetragram for centre,?),只能使用
UTF-16 中两个 16 字节来编码:0xD834 0XDF06。这种就被称为代理对。值得注意的是一个代理对只代表一个单字符。
补充一下代理对的概念
实际上就是指上面的一个 UTF-16 编码,使用 2 个 16 字节来编码。那是因为一个 UTF-16 编码不够,然后就应该使用 2 个
UTF-16 编码来表示更多的字符。然后这样就会出现:之前 2 个字节的空间表示一个字符,就会变成 4
个字节的空间。所以就规定只有一定范围内使用 2 个 UTF-16 编码来表示一个字符,这样的方式就叫代理对,其余的依然使用 2 个字节来表示。
代理对中的第一个字符单元总是在 0xD800 到 0xDBFF 之间,称为高位代理或者顶部代理(high surrogate or
lead surrogate,暂时这样,查到专业术语再翻译)。第二个字符单元总是处于 0xDC00 到 0xDFFF
之间,称为低位代理或者尾部代理(low surrogate or trail surrogate)。
UCS-2 是缺乏对代理对的支持的,所以要表示之前的字符需要使用 2 个分隔的字符。
四、码位(code points)和代理对(surrogate pairs)之间的转换
Section 3.7 of The Unicode Standard 3.0(pdf)中定义了一个转换算法。
假设:一个码位 C 大于 0xFFFF 的编码使用代理对 <H, L> 来表示的公式为:
- H = Math.floor((C - 0x10000) / 0x400) + 0xD800
- L = (C - 0x10000) % 0x400 + 0xDC00
转换公式变换后,比如从代理对 <H, L> 转换成一个 Unicode 码位 C,可以使用公式:
- C = (H - 0xD800) * 0x400 + L - 0xDC00 + 0x10000
五、Ok,那么关于 JavaScript 的编码问题呢?
在 ECMAScript 中定义来怎样解释字符的问题.
在 level 3 或者更高等级的实现中,遵循国际标准,与 Unicode 3.0 标准或者更新的标准,以及 ISO/IEC
10646-1,和 UCS-2 或者 UTF-16 作为编码格式。如果采用的 ISO/IEC 10646-1 自己未被指定,它被认定为 BMP
的自己,集合 300(这里没懂)。如果没有采用其它的编码格式,那么将按照 UTF-16 进行编码。
换句话说,JavaScript 引擎是允许使用 UCS-2 或者 UTF-16 进行编码的。
然后按照 specific parts 规定,认为引擎里面的编码需要一些 UTF-16 的知识。
当然,内部引擎对于大多数 JavaScript 开发者来说没有实际影响。对于更多有趣的发现JavaScript 是如何考虑字符的 中,有一段:
尽管在本文档的其它部分中,表示字符单元和文字字符将使用 16 位的无符号值,用来表示单个 16 位文本单元。Unicode
字符将使用抽象的语言或印刷单元(可超过16位,因此可以由多个代码单元)来表示。码位可以用 Unicode
标准值来表示。一个组合字符序列的成分可以有个别“Unicode 字符”,即使一个用户可能会认为整个序列是单个字符。
可能需要重新翻译,原文
Throughout the rest of this document, the phrase code unit and the
word character will be used to refer to a 16-bit unsigned value used to
represent a single 16-bit unit of text.
The phrase Unicode character will be used to refer to the abstract
linguistic or typographical unit represented by a single Unicode scalar
value (which may be longer than 16 bits and thus may be represented by
more than one code unit).
The phrase code point refers to such a Unicode scalar value.
Unicode character only refers to entities represented by single
Unicode scalar values: the components of a combining character sequence
are still individual “Unicode characters”, even though a user might
think of the whole sequence as a single character.
JavaScript 使用单独字符来处理字符单元,然后人们通常认为是一组 Unicode 字符。当使用 BMP 范围外 Unicode
字符的时候,这样会有一些不好的结果。比如代理对使用 2 个字符单元组成:'?'.length == 2,即使这里是只有一个 Unicode
字符。如果是字符,代理对将暴露一部分:'?' == '\uD834\uDF06'。
在这里你想到了什么呢?对于这种方式,至少是 UCS-2 的替代方式(不同的地方是,UCS-2 不允许有代理字符,然后 JavaScript 字符串是这样做的)。
你可以认为它像 UTF-16
一样在工作,特别是分成两部分的方式是被允许的,代理的这种错误排序是被允许的,代理被暴露成了分离的字符。我认为你将更容易的理解成这种行为叫“UCS-2
的代理方式”(UCS-2 with surrogates,不好翻译,也可以理解成伴随着代理的 UCS-2)。
类似 UCS-2 的行为对整个语言更有影响,比如 补充字符范围的正则表达式 比那些支持 UTF-16 的语言要更难写。
代理对只是为了显示在浏览器中(layout 的时候),对单个 Unicode 字符的重新组合。这发生在 JavaScript 引擎的影响范围之外。为了证明这个,你能在 document.write() 的时候分开写一个高位代理和地位代理字符.
- document.write('\uD834');
- document.write('\uDF06');
在结束后也将被渲染成一个图案:?。
六、结论
JavaScript 引擎内部是自由的使用 UCS-2 或者 UTF-16。我所知道的大多数引擎使用的是 UTF-16,无论它们使用什么方式实现,它只是一个具体的实现,这不将影响到语言的特性。
然后对于 ECMAScript/JavaScript 语言本身,实现的效果是通过 UCS-2,而非 UTF-16。
如果你在任何时候需要 编码一个 Unicode 字符, 在必要的时候能够替换成分离的代理,也可以免费试用我的 JavaScript escaper 工具。
如果你想在一个 JavaScript 字符串中获取 Unicode 字符的长度,或者创建一个基于 non-BMP Unicode 码位的字符串,你能使用Punycode.js 的工具方法,将 UCS-2 字符串转换成 UTF-16 码位。
- // `String.length` 只是统计所以 Unicode 字符
- punycode.ucs2.decode('?').length; // 1
- // `String.fromCharCode` 能够让你直接使用非分离的代理
- punycode.ucs2.encode([0x1D306]); // '?'
- punycode.ucs2.encode([119558]); // '?'
ECMAScript 6 在字符串中将支持一些新的编码序列(现在看来已经 ok 了,可以查看一下资料简单了解下),名为 Unicode
code point escapes 比如:\u{1D306}。另外,它将定义 String.fromCodePoint 和
String#codePointAt,这两个方法都接受码位(code points) 而不是字符单元(code units)
感谢:Jonas ‘nlogax’ Westerlund, Andrew ‘bobince’ Clover 以及 Tab Atkins Jr.。他们给了我调查的灵感和帮助我。
提示:如果你喜欢阅读关于 JavaScript 的内部字符编码,可以 check out JavaScript has a Unicode problem,这里更详细解释了实际的问题,以及提供了解决方法。
作者:小撸
来源:51CTO