3.3 加法器
n位整数加法器输入两个n位数值和一个可选的输入进位(cin)来产生一个n位的和及最后进位输出(cout)。如图3-3所示,从右(例如最低有效位)开始,两位和先前的进位相加产生一个和及一个进位(0或1)来进行下两位相加。在图中,初始的cin假设为0。算法重复直到最后两位相加并产生最后的和及最后的进位输出cout停止。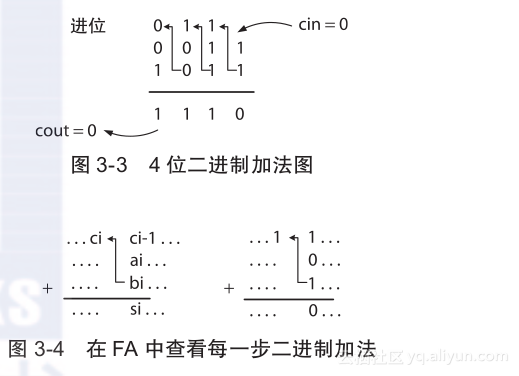
在图中,最先的两位(都为1)和cin = 0相加得到0且进位为1。下一个两位,也都为1,且先前进位为1,相加得到和及进位都为1。其他位也进行类似的加法操作。这个简单的加法算法可以看成是多个1位加法步骤,每一个都是一个全加器FA,如图3-4中第i步所示。在算法的每个步骤中,两个1位输入ai和bi和先前进位ci - 1相加产生和si和下一个进位ci。对于n位数,这个过程需要重复n次及i = 0,1,…,n - 1,c- 1 = cin,cout = cn - 1。
3.3.1 进位传输加法器
在图3-4中实现简单加法算法的n位加法器使用n个FA片串联而成的,如图3-5所示。从最低有效位进位开始,进位c0到cn - 1在每一步中产生一个,类似于手工加法运算。这种加法器又叫进位传输加法器(CPA),因为进位是从一个FA片到下一个FA片一个一个产生的。当进位在电路中波纹传输,就像在进位链中进位反馈给下一个FA片时,这种加法器叫行波进位加法器(RCA)。
进位传输加法器是加法器中最简单的电路,但有正比于进位数量的最长传输延迟。每一个进位信号都依赖于先前的进位信号;c1依赖于c0,c2依赖于c1等(原书有误——译者注)。公式(3-1)用于估计n位CPA的传输延迟,ΔCPA (n)表示n位CPA的传输延迟,ΔFAc和ΔFAs分别表示FA中进位及和的传输延迟。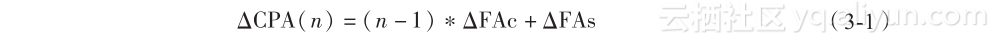
公式(3-2)表示在与非门延迟ΔNAND = 0.1ns和如第2章公式(2-8)SOP表达式中,FA的进位及和延迟分别为ΔFAc = 0.2ns及ΔFAs = 0.3ns的n位CPA传输延迟的计算过程。当n = 8时,ΔCPA (8) = 1.7ns。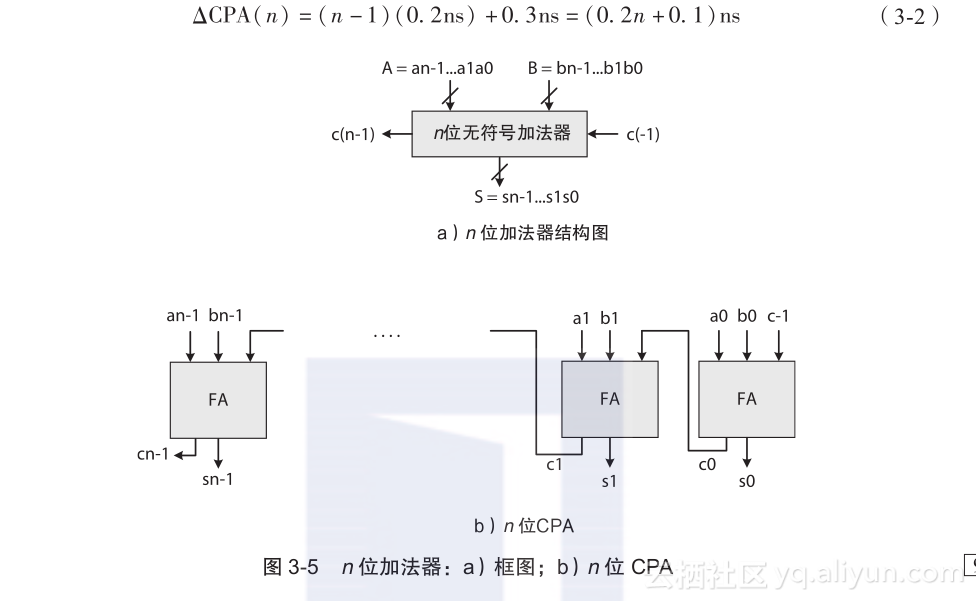
3.3.2 先行进位加法器
当n很大时,CPA的传输延迟可以变得过大。电路会产生一个非常长的进位产生链。然而,我们也可以用更多的独立逻辑门来在更少的时间内并行产生进位。为了说明这点,我们将定义两个变量传输(p)和产生(g),如下所示,其中i为数位位置,i = 0, 1, 2, …, n - 1。
如果每一个依次的进位可以代入后来的进位表达式中,那么就可以并行地产生c1、c2等进位。进位c1和c2的产生过程展示如下:
c1和c2最后的表达式都依赖于c- 1,这样它们就可以并行地产生了。然而相比于公式(3-6),每一个扩展表达式都需要更多的硬件去实现,包括逻辑门、更大的扇入和扇出需求。
p和g位信号是用于定义快速在大量输入中计算进位的模式。图3-6中的例子展示了用3位输入A = a2a1a0和B = b2b1b0的计算过程。在实例a中,p2、p1和p0都为1;这样,进位输入为1(c-1 = 1)将传输输出为c2 = 1,因为在公式(3-7)中p2p1p0c-1 = 1。在实例b中,p2 = 1,p1 = 1且g0 = 1;这样,进位输入为0(例如a0 = 1、b0 = 1,这样g0 = 1)则产生输出c2 = 1,因为p2p1p0 = 1。其他的实例展示了其他情况,使得c2为1。在实例c中,p2g1 = 1,所以c2 = 1,在实例d中,g2 = 1,所以c2 = 1。

当进位求出来以后,和值s0、s1和s2也可以并行地生成,由如下等式确定。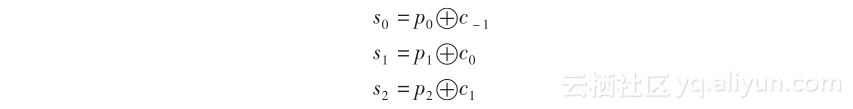
图3-7展示了3位先行进位(CLA)加法器电路。p和g位用三个异或门和三个与门在0.3ns内并行生成,这里最大值ΔXOR = 0.3ns、ΔAND = 0.2ns,假设与非门有0.1ns延迟。这个电路也称为PG单元(PGU)。p和g位和最初进位输入c-1被送入进位生成单元(CGU)。CGU中的三个进位电路是独立的且可以在0.2ns内并行产生所有的进位c0、c1和c2,假设电路用与非门实现。使用另一套异或门,最后和值也可以用p和进位为输入并行生成。这些异或门可以组合成一个称为和单元(SU)的模块。
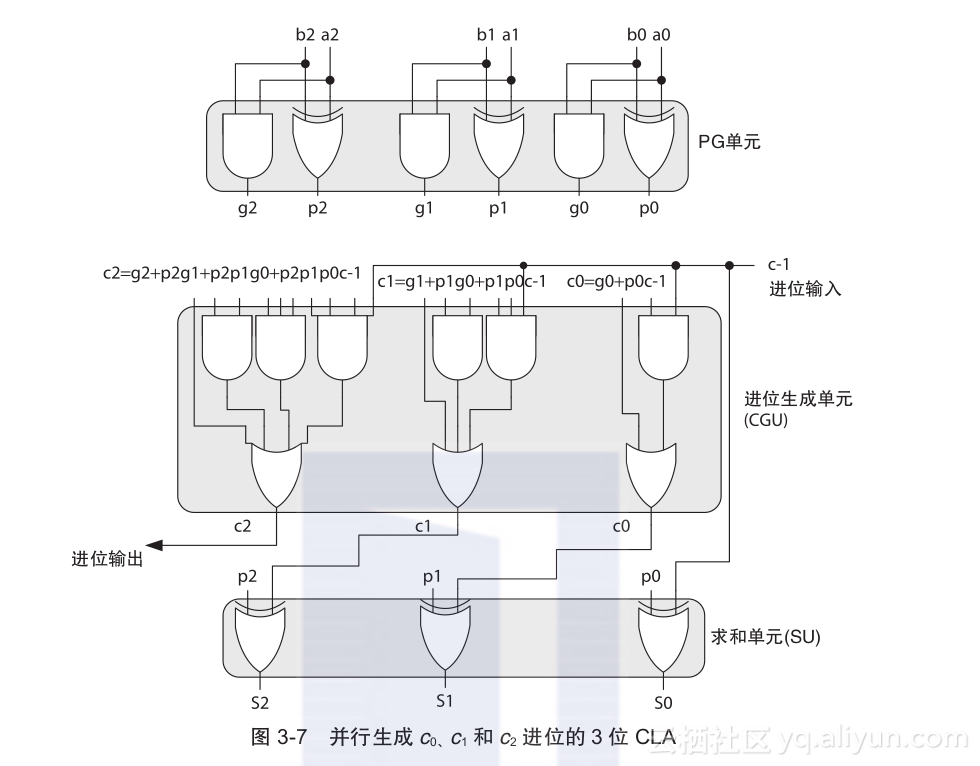
有进位c0~c7的8位CLA仍然比较小,设计不会违反逻辑门扇入和扇出的限制。在这个例子中,进位ci的电路用扇入≤i + 2的逻辑门实现。CLA(8)的延迟为0.8ns,如公式(3-8)所示,假设与非门有0.1ns延迟。CLA(8)比CPA(8)运行速度要快两倍以上;然而,需要更多的硬件去实现其电路。
另一种CLA可以用与门实现g位、用或门实现p位及用FA输出和值[1]。
1.大型CLA加法器
对于很大的n值(例如n > 8),将进位表达式连续代入后边的进位表达式中,如公式(3-7)中的进位c1和c2,最后将产生一个非常长的进位表达式,这样对应的电路会需要很多有大量扇入数量的逻辑门。此外,一些逻辑门,比如产生p信号的异或门需要大量的扇出值,这样p才能作为多个CGU中的进位生成电路的输入去生成其他的进位信号,SU中的和值电路也是如此。这样,当n是一个非常大的数(例如32位或者64位)时,需要另一种方法来限制每一个电路模块的扇入和扇出需求。
在这个实例中,进位表达式被分成不同的集合以便使在对应电路中的逻辑门的最大扇入和扇出可以控制在一个可接受的范围内。简单举例,当n = 8时的情况如下。CLA(8)的进位表达式分成三个集合,如公式(3-9)所示。每一个集合中的表达式都有少于三个逻辑项和少于三个的变量。则对应电路的扇入≤3且扇出≤2。例如,集合1中的c1,根据信号p0,电路有最大扇入= 3和最大扇出= 2。每一个集合中的进位表达式都是数据独立的;这样进位可以在输入可用时立即生成。对于集合1中的表达式,c-1是进位输入;在集合2中,进位输入为c2;在集合3中,进位输入为c5。
在进位输入信号c-1、c2和c5中,进位输入c-1是最初的输入值,而其他两个进位输入必须由其他信号生成。它们由公式(3-10)决定并分为集合4。
考虑到当c2和c5表达式表示成p和g信号表达的形式时都是数据独立的。p和g信号也是数据独立的,且由p和g信号决定。也就是说,c2和c5最终的表达式也和集合1~集合3中的表达式类似,除了这些表达式要求以p和g信号作为输入。p中的号表示比特组中的进位传播。类似地,g中的号表示比特组中的进位生成和传播。当p = 1时,意味着1作为进位进入到块中将被传播为生成进位的1。类似地,当g = 1时,意味着在块中生成的进位1将被传输为进位输出。
集合1中的进位依赖于进位c-1以及p和g信号;这样,它们可以在p和g信号生成之后立即并行地生成。考虑到因为所有p和g信号都可以在同一时间生成,和当c0和c1生成时,它们将被移动到集合1~集合3,如公式(3-11)所示:

8位CLA的详细电路图如图3-8所示。所有8个进位c0~c7都在三步中产生,如下:
1)集合1中的进位c0和c1和所有在集合1、2和3中的p和g信号首先生成;
2)下一步,生成集合4中的进位c2和c5;
3)最后,生成集合2和集合3中的c3、c4、c6和c7。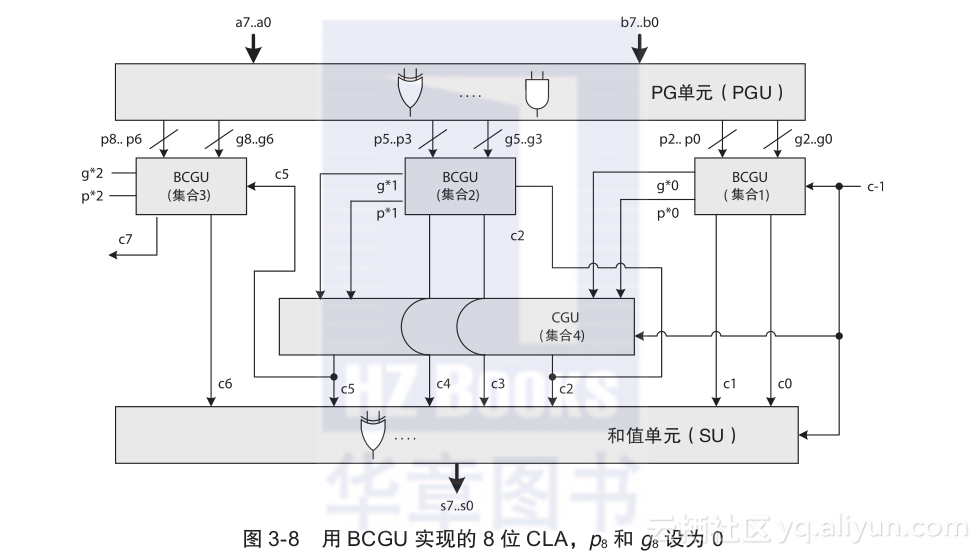
实现集合1~集合3中每一个表达式的电路都称为块进位生成单元(BCGU)。实现集合4中表达式的电路依旧为CGU。当所有进位都生成之后,c-1~c6和p0~p7都被送进SU以便并行生成所有的和值位s0~s7。
对于很大值的n(例如n = 32或者n = 64)来说,CLA(n)电路和图3-8中所示的CLA(8)电路是一样的。除了当n很大时,进位必须被分成更多的集合以避免BCGU或者CGU的扇入和扇出问题。以图3-8中的电路设计为基础,公式(3-12)估算了CLA(n)的传输延迟,假设与非门的延迟为0.1ns。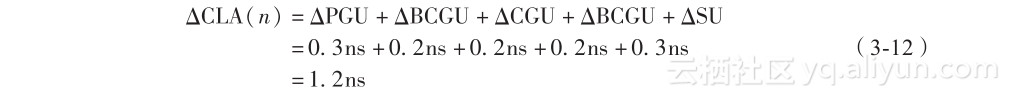
大型CLA加法器比等价的CPA加法器要快得多,但是需要更多的硬件来实现。或者,我们可以设计一个一部分是CLA一部分是CPA的混合加法器。混合加法器比CPA要快,但是比CLA要慢。例如,16位的混合加法器可以用两个CLA(8)片设计,第一片中的进位c7传送到第二片中。这个16位混合加法器要比CPA(16)快,但是要比CLA(16)慢,并且需要的硬件比CLA(16)要少一些。
2.?HDL模块
例3-1~例3-6展示了用一个PGU、三个BCGU、一个CGU和一个SU设计的8位CLA Verilog描述。行为和结构模型都用于设计加法器。
例3-1? 8位CLA加法器的结构化描述:
例3-2? 用BCGU和CGU实现的8位进位生成模块的结构化描述:
例3-3? 3位BCGU的行为描述:

例3-4? 2位CGU的行为描述:
例3-5? 8位PGU的行为描述:
例3-6? n位SU的行为描述: