https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
http://www.slideshare.net/databricks/a-deep-dive-into-structured-streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine.
You can express your streaming computation the same way you would express a batch computation on static data.
The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the Dataset/DataFrame API in Scala, Java or Python to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine.
Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write Ahead Logs.
In short, Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
你可以像在静态数据源上一样,使用DataFrame接口去执行SQL,这些SQL会跑在和batch相同的optimized Spark SQL engine上
并且可以保证exactly-once fault-tolerance,通过checkpointing and Write Ahead Logs
只是将DStream抽象,换成DataFrame,即table
这样就可以进行结构化的操作,
并且基本和处理batch数据一样,

可以看到差别不大
整个过程是这样的,

可以看到,这里的output模式是complete,因为有聚合,所以每次输出需要,输出until now的统计数据
输出的mode,分为,
The “Output” is defined as what gets written out to the external storage. The output can be defined in different modes
- Complete Mode - The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle writing of the entire table.
- Append Mode - Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only on the queries where existing rows in the Result Table are not expected to change.
- Update Mode - Only the rows that were updated in the Result Table since the last trigger will be written to the external storage (not available yet in Spark 2.0). Note that this is different from the Complete Mode in that this mode does not output the rows that are not changed.
complete mode上面的例子已经给出
append mode,就是每次只输出增量,这个对于没有聚合的场景就是合适的
Window Operations on Event Time
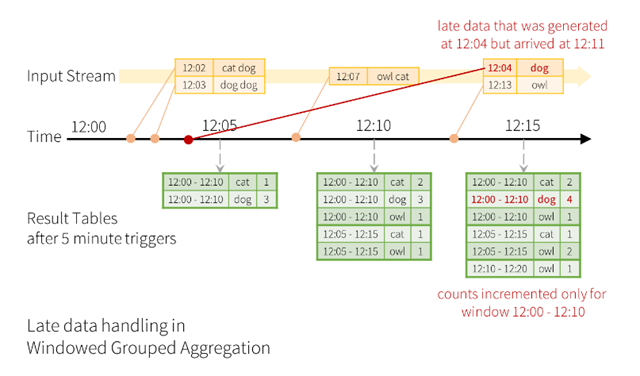
spark认为自己对于Event time是天然支持的,只需要把它作为dataframe里面的一个列,然后做groupby即可以
然后对于late data,因为是增量输出的,所以也是可以handle的
Fault Tolerance Semantics
Delivering end-to-end exactly-once semantics was one of key goals behind the design of Structured Streaming.
To achieve that, we have designed the Structured Streaming sources, the sinks and the execution engine to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing. Every streaming source is assumed to have offsets (similar to Kafka offsets, or Kinesis sequence numbers) to track the read position in the stream. The engine uses checkpointing and write ahead logs to record the offset range of the data being processed in each trigger. The streaming sinks are designed to be idempotent for handling reprocessing. Together, using replayable sources and idempotant sinks, Structured Streaming can ensure end-to-end exactly-once semantics under any failure.
首先依赖source是可以依据offset replay,而sink是幂等的,这样只需要通过Write Ahead Logs记录offset,checkpoint记录state,就可以做到exactly once,因为本质是batch