ART世界探险(19) - 优化编译器的编译流程
前面,我们对于快速编译器的知识有了一点了解,对于CompilerDriver,MIRGraph等都有了初步的印象。
下面,我们回头看一下优化编译器的编译过程。有了前面的基础,后面的学习过程会更顺利一些。
下面我们先看个地图,看看我们将遇到哪些新的对象:
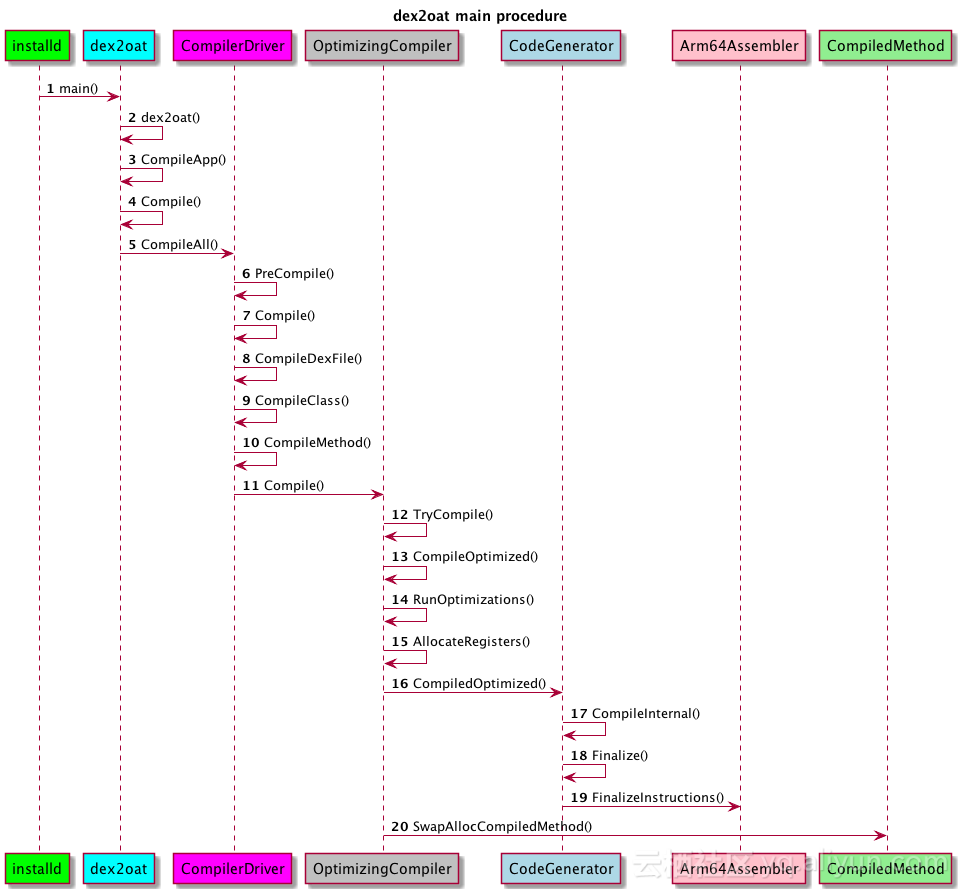
OptimizingCompiler::Compile
我们先来看看优化编译的入口点,Compile函数:
CompiledMethod OptimizingCompiler::Compile(const DexFile::CodeItem code_item,
uint32_t access_flags,
InvokeType invoke_type,
uint16_t class_def_idx,
uint32_t method_idx,
jobject jclass_loader,
const DexFile& dex_file) const {
CompilerDriver* compiler_driver = GetCompilerDriver();
CompiledMethod* method = nullptr;
if (compiler_driver->IsMethodVerifiedWithoutFailures(method_idx, class_def_idx, dex_file) &&
!compiler_driver->GetVerifiedMethod(&dex_file, method_idx)->HasRuntimeThrow()) {
校验成功的话,下面就调用TryCompile方法来完成编译。
method = TryCompile(code_item, access_flags, invoke_type, class_def_idx,
method_idx, jclass_loader, dex_file);
} else {
if (compiler_driver->GetCompilerOptions().VerifyAtRuntime()) {
MaybeRecordStat(MethodCompilationStat::kNotCompiledVerifyAtRuntime);
} else {
MaybeRecordStat(MethodCompilationStat::kNotCompiledClassNotVerified);
}
}
如果编译成功了,则直接返回。如果不成功,则再调用其他方式编译。
if (method != nullptr) {
return method;
}
method = delegate_->Compile(code_item, access_flags, invoke_type, class_def_idx, method_idx,
jclass_loader, dex_file);
if (method != nullptr) {
MaybeRecordStat(MethodCompilationStat::kCompiledQuick);
}
return method;
}
OptimizingCompiler::TryCompile
CompiledMethod OptimizingCompiler::TryCompile(const DexFile::CodeItem code_item,
uint32_t access_flags,
InvokeType invoke_type,
uint16_t class_def_idx,
uint32_t method_idx,
jobject class_loader,
const DexFile& dex_file) const {
UNUSED(invoke_type);
std::string method_name = PrettyMethod(method_idx, dex_file);
MaybeRecordStat(MethodCompilationStat::kAttemptCompilation);
CompilerDriver* compiler_driver = GetCompilerDriver();
对于ARM32位的架构,我们默认使用Thumb2指令集。
关于ARM指令集,我们之前在《ART世界探险(3) - ARM 64位CPU的架构快餐教程》中有过介绍。
InstructionSet instruction_set = compiler_driver->GetInstructionSet();
// Always use the thumb2 assembler: some runtime functionality (like implicit stack
// overflow checks) assume thumb2.
if (instruction_set == kArm) {
instruction_set = kThumb2;
}
如果无法优化,或者要求不优化,返直接返回
// `run_optimizations_` is set explicitly (either through a compiler filter
// or the debuggable flag). If it is set, we can run baseline. Otherwise, we
// fall back to Quick.
bool should_use_baseline = !run_optimizations_;
bool can_optimize = CanOptimize(*code_item);
if (!can_optimize && !should_use_baseline) {
// We know we will not compile this method. Bail out before doing any work.
return nullptr;
}
指令集都不支持,那也就不用编了
// Do not attempt to compile on architectures we do not support.
if (!IsInstructionSetSupported(instruction_set)) {
MaybeRecordStat(MethodCompilationStat::kNotCompiledUnsupportedIsa);
return nullptr;
}
如果不值得编的话,就不编了。
怎么算值不值得编呢?指令太多了的,或者是虚拟寄存器使用比较多的,就不编了,我们来看IsPathologicalCase的代码:
bool Compiler::IsPathologicalCase(const DexFile::CodeItem& code_item,
uint32_t method_idx,
const DexFile& dex_file) {
/*
* Skip compilation for pathologically large methods - either by instruction count or num vregs.
* Dalvik uses 16-bit uints for instruction and register counts. We'll limit to a quarter
* of that, which also guarantees we cannot overflow our 16-bit internal Quick SSA name space.
*/
if (code_item.insns_size_in_code_units_ >= UINT16_MAX / 4) {
LOG(INFO) << "Method exceeds compiler instruction limit: "
<< code_item.insns_size_in_code_units_
<< " in " << PrettyMethod(method_idx, dex_file);
return true;
}
if (code_item.registers_size_ >= UINT16_MAX / 4) {
LOG(INFO) << "Method exceeds compiler virtual register limit: "
<< code_item.registers_size_ << " in " << PrettyMethod(method_idx, dex_file);
return true;
}
return false;
}
UINT16_MAX是两个字节的最大整数,为65535,除以4大约是16384。
if (Compiler::IsPathologicalCase(*code_item, method_idx, dex_file)) {
MaybeRecordStat(MethodCompilationStat::kNotCompiledPathological);
return nullptr;
}
下面处理空间选项,大于128单元的代码项不编译,以节省空间。
// Implementation of the space filter: do not compile a code item whose size in
// code units is bigger than 128.
static constexpr size_t kSpaceFilterOptimizingThreshold = 128;
const CompilerOptions& compiler_options = compiler_driver->GetCompilerOptions();
if ((compiler_options.GetCompilerFilter() == CompilerOptions::kSpace)
&& (code_item->insns_size_in_code_units_ > kSpaceFilterOptimizingThreshold)) {
MaybeRecordStat(MethodCompilationStat::kNotCompiledSpaceFilter);
return nullptr;
}
下面我们的老朋友DexComplicationUnit又出来了。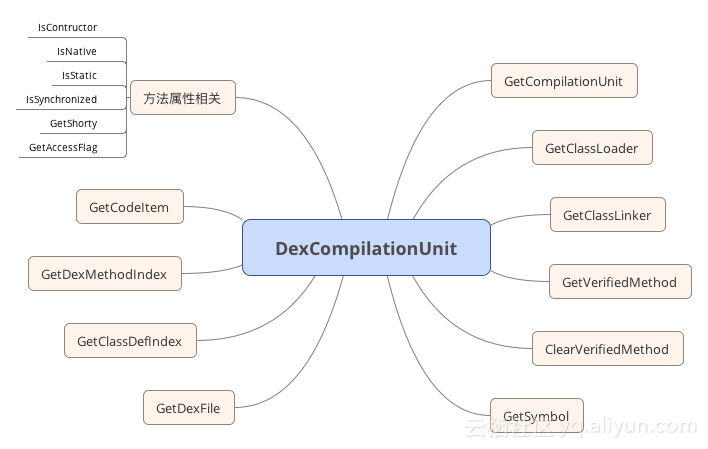
DexCompilationUnit dex_compilation_unit(
nullptr, class_loader, art::Runtime::Current()->GetClassLinker(), dex_file, code_item,
class_def_idx, method_idx, access_flags,
compiler_driver->GetVerifiedMethod(&dex_file, method_idx));
然后我们构造一个HGraph对象,作用相当于quick Compiler中的MIRGraph.
ArenaAllocator arena(Runtime::Current()->GetArenaPool());
HGraph* graph = new (&arena) HGraph(
&arena, dex_file, method_idx, compiler_driver->GetInstructionSet(),
compiler_driver->GetCompilerOptions().GetDebuggable());
// For testing purposes, we put a special marker on method names that should be compiled
// with this compiler. This makes sure we're not regressing.
bool shouldCompile = method_name.find("$opt$") != std::string::npos;
bool shouldOptimize = method_name.find("$opt$reg$") != std::string::npos && run_optimizations_;
std::unique_ptr<CodeGenerator> codegen(
CodeGenerator::Create(graph,
instruction_set,
*compiler_driver->GetInstructionSetFeatures(),
compiler_driver->GetCompilerOptions()));
if (codegen.get() == nullptr) {
CHECK(!shouldCompile) << "Could not find code generator for optimizing compiler";
MaybeRecordStat(MethodCompilationStat::kNotCompiledNoCodegen);
return nullptr;
}
codegen->GetAssembler()->cfi().SetEnabled(
compiler_driver->GetCompilerOptions().GetGenerateDebugInfo());
PassInfoPrinter pass_info_printer(graph,
method_name.c_str(),
*codegen.get(),
visualizer_output_.get(),
compiler_driver);
下面构造一个HGraphBuilder对象,然后调用HGraphBuilder的BuildGraph方法构造这个图。
HGraphBuilder builder(graph,
&dex_compilation_unit,
&dex_compilation_unit,
&dex_file,
compiler_driver,
compilation_stats_.get());
VLOG(compiler) << "Building " << method_name;
{
PassInfo pass_info(HGraphBuilder::kBuilderPassName, &pass_info_printer);
if (!builder.BuildGraph(*code_item)) {
DCHECK(!(IsCompilingWithCoreImage() && shouldCompile))
<< "Could not build graph in optimizing compiler";
return nullptr;
}
}
下一步,尝试对HGraph构造SSA。
bool can_allocate_registers = RegisterAllocator::CanAllocateRegistersFor(*graph, instruction_set);
if (run_optimizations_ && can_optimize && can_allocate_registers) {
VLOG(compiler) << "Optimizing " << method_name;
{
PassInfo pass_info(SsaBuilder::kSsaBuilderPassName, &pass_info_printer);
if (!graph->TryBuildingSsa()) {
// We could not transform the graph to SSA, bailout.
LOG(INFO) << "Skipping compilation of " << method_name << ": it contains a non natural loop";
MaybeRecordStat(MethodCompilationStat::kNotCompiledCannotBuildSSA);
return nullptr;
}
}
return CompileOptimized(graph,
codegen.get(),
compiler_driver,
dex_file,
dex_compilation_unit,
&pass_info_printer);
} else if (shouldOptimize && can_allocate_registers) {
LOG(FATAL) << "Could not allocate registers in optimizing compiler";
UNREACHABLE();
} else if (should_use_baseline) {
下面是不优化的情况:
VLOG(compiler) << "Compile baseline " << method_name;
if (!run_optimizations_) {
MaybeRecordStat(MethodCompilationStat::kNotOptimizedDisabled);
} else if (!can_optimize) {
MaybeRecordStat(MethodCompilationStat::kNotOptimizedTryCatch);
} else if (!can_allocate_registers) {
MaybeRecordStat(MethodCompilationStat::kNotOptimizedRegisterAllocator);
}
return CompileBaseline(codegen.get(), compiler_driver, dex_compilation_unit);
} else {
return nullptr;
}
}
OptimizingCompiler::CompileOptimized
下面我们再看看优化编译的部分:
CompiledMethod OptimizingCompiler::CompileOptimized(HGraph graph,
CodeGenerator* codegen,
CompilerDriver* compiler_driver,
const DexFile& dex_file,
const DexCompilationUnit& dex_compilation_unit,
PassInfoPrinter* pass_info_printer) const {
StackHandleScopeCollection handles(Thread::Current());
下面开始调用RunOptimizations进行优化,一共15轮优化。
AllocateRegisters是第16轮优化,liveness优化。
RunOptimizations(graph, compiler_driver, compilation_stats_.get(),
dex_file, dex_compilation_unit, pass_info_printer, &handles);
AllocateRegisters(graph, codegen, pass_info_printer);
下面是生成目标代码:
CodeVectorAllocator allocator;
codegen->CompileOptimized(&allocator);
DefaultSrcMap src_mapping_table;
if (compiler_driver->GetCompilerOptions().GetGenerateDebugInfo()) {
codegen->BuildSourceMap(&src_mapping_table);
}
std::vector<uint8_t> stack_map;
codegen->BuildStackMaps(&stack_map);
MaybeRecordStat(MethodCompilationStat::kCompiledOptimized);
最后分配空间,将编译的方法保存起来:
return CompiledMethod::SwapAllocCompiledMethod(
compiler_driver,
codegen->GetInstructionSet(),
ArrayRef<const uint8_t>(allocator.GetMemory()),
// Follow Quick's behavior and set the frame size to zero if it is
// considered "empty" (see the definition of
// art::CodeGenerator::HasEmptyFrame).
codegen->HasEmptyFrame() ? 0 : codegen->GetFrameSize(),
codegen->GetCoreSpillMask(),
codegen->GetFpuSpillMask(),
&src_mapping_table,
ArrayRef<const uint8_t>(), // mapping_table.
ArrayRef<const uint8_t>(stack_map),
ArrayRef<const uint8_t>(), // native_gc_map.
ArrayRef<const uint8_t>(*codegen->GetAssembler()->cfi().data()),
ArrayRef<const LinkerPatch>());
}
RunOptimizations
优化的过程:
- IntrinsicsRecognizer
- 第一次HConstantFolding
- 第二次InstructionSimplifier
- HDeadCodeElimination
- HInliner
- HBooleanSimplifier
- 第二次HConstantFolding
- SideEffectsAnalysis
- GVNOptimization
- LICM
- BoundsCheckElimination
- ReferenceTypePropagation
- 第二次InstructionSimplifier
- 第二次HDeadCodeElimination
- 第三次InstructionSimplifier
static void RunOptimizations(HGraph* graph,
CompilerDriver* driver,
OptimizingCompilerStats* stats,
const DexFile& dex_file,
const DexCompilationUnit& dex_compilation_unit,
PassInfoPrinter* pass_info_printer,
StackHandleScopeCollection* handles) {
HDeadCodeElimination dce1(graph, stats,
HDeadCodeElimination::kInitialDeadCodeEliminationPassName);
HDeadCodeElimination dce2(graph, stats,
HDeadCodeElimination::kFinalDeadCodeEliminationPassName);
HConstantFolding fold1(graph);
InstructionSimplifier simplify1(graph, stats);
HBooleanSimplifier boolean_simplify(graph);
HInliner inliner(graph, dex_compilation_unit, dex_compilation_unit, driver, stats);
HConstantFolding fold2(graph, "constant_folding_after_inlining");
SideEffectsAnalysis side_effects(graph);
GVNOptimization gvn(graph, side_effects);
LICM licm(graph, side_effects);
BoundsCheckElimination bce(graph);
ReferenceTypePropagation type_propagation(graph, dex_file, dex_compilation_unit, handles);
InstructionSimplifier simplify2(graph, stats, "instruction_simplifier_after_types");
InstructionSimplifier simplify3(graph, stats, "instruction_simplifier_before_codegen");
IntrinsicsRecognizer intrinsics(graph, dex_compilation_unit.GetDexFile(), driver);
HOptimization* optimizations[] = {
&intrinsics,
&fold1,
&simplify1,
&dce1,
&inliner,
// BooleanSimplifier depends on the InstructionSimplifier removing redundant
// suspend checks to recognize empty blocks.
&boolean_simplify,
&fold2,
&side_effects,
&gvn,
&licm,
&bce,
&type_propagation,
&simplify2,
&dce2,
// The codegen has a few assumptions that only the instruction simplifier can
// satisfy. For example, the code generator does not expect to see a
// HTypeConversion from a type to the same type.
&simplify3,
};
RunOptimizations(optimizations, arraysize(optimizations), pass_info_printer);
}
AllocateRegisters
进行liveness优化:
static void AllocateRegisters(HGraph* graph,
CodeGenerator* codegen,
PassInfoPrinter* pass_info_printer) {
PrepareForRegisterAllocation(graph).Run();
SsaLivenessAnalysis liveness(graph, codegen);
{
PassInfo pass_info(SsaLivenessAnalysis::kLivenessPassName, pass_info_printer);
liveness.Analyze();
}
{
PassInfo pass_info(RegisterAllocator::kRegisterAllocatorPassName, pass_info_printer);
RegisterAllocator(graph->GetArena(), codegen, liveness).AllocateRegisters();
}
}
CodeGenerator::CompiledOptimized
主要逻辑拆成Initialize()和CompileInternal()两部分
void CodeGenerator::CompileOptimized(CodeAllocator* allocator) {
// The register allocator already called `InitializeCodeGeneration`,
// where the frame size has been computed.
DCHECK(block_order_ != nullptr);
Initialize();
CompileInternal(allocator, / is_baseline / false);
}
CodeGenerator::CompileInternal
void CodeGenerator::CompileInternal(CodeAllocator* allocator, bool is_baseline) {
is_baseline_ = is_baseline;
HGraphVisitor* instruction_visitor = GetInstructionVisitor();
DCHECK_EQ(current_block_index_, 0u);
GenerateFrameEntry();
DCHECK_EQ(GetAssembler()->cfi().GetCurrentCFAOffset(), static_cast<int>(frame_size_));
for (size_t e = block_order_->Size(); current_block_index_ < e; ++current_block_index_) {
HBasicBlock* block = block_order_->Get(current_block_index_);
// Don't generate code for an empty block. Its predecessors will branch to its successor
// directly. Also, the label of that block will not be emitted, so this helps catch
// errors where we reference that label.
if (block->IsSingleGoto()) continue;
到Bind的时候,已经进入跟具体架构相关的生成代码的部分了。比如针对arm64架构,就是CodeGeneratorARM64的Bind:
void CodeGeneratorARM64::Bind(HBasicBlock* block) {
__ Bind(GetLabelOf(block));
}
Bind之后,对于block之中的指令进行遍历。
Bind(block);
for (HInstructionIterator it(block->GetInstructions()); !it.Done(); it.Advance()) {
HInstruction* current = it.Current();
if (is_baseline) {
InitLocationsBaseline(current);
}
DCHECK(CheckTypeConsistency(current));
current->Accept(instruction_visitor);
}
}
下面处理慢路径下的操作:
// Generate the slow paths.
for (size_t i = 0, e = slow_paths_.Size(); i < e; ++i) {
slow_paths_.Get(i)->EmitNativeCode(this);
}
最后调用汇编器生成指令
// Finalize instructions in assember;
Finalize(allocator);
}
CodeGenerator::Finalize
void CodeGenerator::Finalize(CodeAllocator* allocator) {
size_t code_size = GetAssembler()->CodeSize();
uint8_t* buffer = allocator->Allocate(code_size);
MemoryRegion code(buffer, code_size);
GetAssembler()->FinalizeInstructions(code);
}
Arm64Assembler::FinalizeInstructions
下面是Arm64Assembler的FinalizeInstructions,其它芯片用的是通用的版本。
void Arm64Assembler::FinalizeInstructions(const MemoryRegion& region) {
// Copy the instructions from the buffer.
MemoryRegion from(vixl_masm_->GetStartAddress<void*>(), CodeSize());
region.CopyFrom(0, from);
}
CompiledMethod::SwapAllocCompiledMethod
最后看下SwapAllocCompiledMethod,基本上就是分配空间了。
CompiledMethod* CompiledMethod::SwapAllocCompiledMethod(
CompilerDriver* driver,
InstructionSet instruction_set,
const ArrayRef<const uint8_t>& quick_code,
const size_t frame_size_in_bytes,
const uint32_t core_spill_mask,
const uint32_t fp_spill_mask,
DefaultSrcMap* src_mapping_table,
const ArrayRef<const uint8_t>& mapping_table,
const ArrayRef<const uint8_t>& vmap_table,
const ArrayRef<const uint8_t>& native_gc_map,
const ArrayRef<const uint8_t>& cfi_info,
const ArrayRef<const LinkerPatch>& patches) {
SwapAllocator<CompiledMethod> alloc(driver->GetSwapSpaceAllocator());
CompiledMethod* ret = alloc.allocate(1);
alloc.construct(ret, driver, instruction_set, quick_code, frame_size_in_bytes, core_spill_mask,
fp_spill_mask, src_mapping_table, mapping_table, vmap_table, native_gc_map,
cfi_info, patches);
return ret;
}