一、写在前面
本人之前一直从事程序开发的(PHP、JAVA、Python)工作,在之前的工作经历中有过一段时间配合Hadoop工程师的事务,但接触的并不深,只能说略知点皮毛,有点管中窥豹的感觉。
今年进了新公司,因为公司正在组建新的数据部门,非常有幸本人得以调入该部门,恰逢MaxCompute横空出世,刚好因为我那时工作比较空闲,得以安排调研它的功能及测试是否符合我们的要求。
由于个人对大数据这块的经验不足,涉及的内容也不是太高端的,所得知识基本是通过阅读文档获得,所以本文仅以初学者的角度去阐述,主要围绕数据迁移这块,其他部分还未来得急涉及,如有不正确的地方,还请指出,谢谢。
二、平台体系的选型
因初期数据量相对较小,使用Kettle进行抽取数据等工作,ETL的工作大部分在MySQL数据仓库中完成。多种数据源使用Presto(集群)作为查询中间键进行相应的数据分析。但随着业务的疯狂增长,数据表单表达到数亿后,磁盘容量达数几百GB时,数据要求的复杂度逐步提升,使用MySQL作为基础数据仓库的基石已经不足以应付,常出现查询响应时间等待过长,甚至内存崩溃导致执行失败的情况,极大的影响了工作效率。所以使用选择一款大数据平台势在必行。初期考虑使用Hadoop来做进行数据分析平台,恰逢MaxCompute横空出世给我们一个新的选择,在经过仔细比对后,考虑到公司新数据部门刚成立不久,Hadoop大数据相关人才储备较为紧缺,如果等待Hadoop体系完成搭建并使用,可能需要更多的时间,而这势必会拖慢之后的工作进度。而如果使用MaxCompute相对于自建Haoop数据平台要简单,快速的多,但任何产品在正式使用前必然需要进行详细的调研,所以我就开始调研的过程。
三、数据迁移
3.1 数据源类型介绍
目前我们主要有两种数据源的数据需要放至MaxCompute中进行处理,一种为MySQL,一种为MongoDB。在此主要描述MySQL相关的,至于MongoDB嘛,看到最后你就会知道了^_^。
3.2 迁移工具的选择
虽然MaxCompute有多种迁移方案可供选择,但如果使用大数据开发套件上的脚本模式能够有效完成的话,个人还是比较倾向使用大数据开发套件去完成,除非在此之上无法完成。因为相对于自己使用SDK直接同步或其他工具去实现,大数据开发平台要简单快速的多,任务调度系统完善,任务运行情况相对清晰便于查错,之后更多任务可以灵活组合搭配。
3.3 同步策略介绍
数据主要分为会变化的数据(有修改+有增加)与不会变化的数据(只增加),官方文档中是建议每天全量的同步策略,即每天的数据作为一个副本存至同步日期为分区,这样做确实有很多的好处。
但实际情况可能由于数据量过大,每天同步可能会花更多的时间(测试过1亿数据大概在3~4小时左右,脚本参数配置speed": { "concurrent": "1", "mbps": "1" }),因为我们业务中不存在DELTE操作,所以我们这里处理不管数据是否变化都使用每日增量的方式处理,最终按数据的创建日期存放在对应的分区(前期也不知道怎么设计,如何设计最佳,所以就先设计为1级分区),虽然这样需要多做一步合并操作,多耗费一些资源费用,但确实是实现我们的要求。
3.4 步骤介绍
在“大数据开发套件”中同步数据主要使用时间段的方式进行同步,主要分为两个步骤,第一步为手动全量同步,第二步为自动每日增量。如果想让数据的每条数据按数据的创建时间存放到对应的日期的话,则需要在此基础上进行细化。针对不同的数据(会变化与不会变化)的处理方式也各有所不同,基本上是按照文档中所描述的进行了,只是稍微有些不同。
3.5 举例说明
3.5.1 准备工作
- 假设当前日期为: 2017-07-13
- Mysql表信息
数据表名: test
创建时间字段: created_at
更改时间字段: updated_at
时间字段值: unix时间戳
表结构定义如下:CREATE TABLE `test` ( `uid` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID', `name` varchar(10) NOT NULL COMMENT '姓名', `age` tinyint(4) NOT NULL COMMENT '年龄', `sex` tinyint(4) NOT NULL DEFAULT '0' COMMENT '性名(1=男, 2=女, 0=未选择)', `created_at` int(11) NOT NULL COMMENT '创建时间', `updated_at` int(11) NOT NULL COMMENT '修改时间', PRIMARY KEY ( `uid`), KEY `created_at` ( `created_at`), KEY `updated_at` ( `updated_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息表' - MaxCompute数据表
创建一张与这对应的MaxCompute数据表
数据表名: odps_test_history
分 区 名: pt
分 区 值: 数据的创建日期
表结构定义如下:CREATE TABLE odps_test_history ( uid BIGINT COMMENT '用户ID', name STRING COMMENT '姓名', age BIGINT COMMENT '年龄', sex BIGINT COMMENT '性名(1=男, 2=女, 0=未选择)', created_at BIGINT COMMENT '创建时间', updated_at BIGINT COMMENT '修改时' ) PARTITIONED BY ( pt STRING ) LIFECYCLE 100000; - 命名约定
临时表表名后缀:_history
增量表表名后缀:_ inc
3.5.1 同步不会变化的数据
1. 手动全量同步
通过脚本模式将小于当前日期(2017-07-13)的所有的数据一次性导入到一张临时表中。
在数据开发中点击测试运行,看到任务成功运行后,在任务设置调度参数中设置暂停(测试运行不会受到调度干扰,直接运行)。
脚本配置如下:
{
"configuration": {
"reader": {
"plugin": "mysql",
"parameter": {
"datasource": "mysql_db001",
"column": [
"uid",
"name",
"age",
"sex",
"created_at",
"updated_at"
],
"where": "created_at < UNIX_TIMESTAMP('20170713')",
"splitPk": "uid",
"table": "test"
}
},
"writer": {
"plugin": "odps",
"parameter": {
"partition": "pt=history",
"truncate": true,
"datasource": "odps_first",
"column": [
"uid",
"name",
"age",
"sex",
"created_at",
"updated_at"
],
"table": "odps_test_history"
}
},
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": "1",
"mbps": "1"
}
}
},
"type": "job",
"version": "1.0"
}
2. 创建最终目标表
执行ODPS_SQL复制odps_test_history表并命名为odps_test作为最终目标表。
-- 创建目标表
CREATE TABLE odps_test LIKE odps_test_history;
3. 根据数据的时间进行动态分区
执行ODPS_SQL将数据导入到最终目标表中。
--- 将历史表中的数据根据数据的创建的时间插入目标表对应的分区中
INSERT OVERWRITE TABLE odps_test PARTITION (pt)
SELECT uid, name, age, sex, created_at, updated_at, TO_CHAR(FROM_UNIXTIME(created_at), 'yyyymmdd') AS pt
FROM odps_test_history;
4. 简单验证数据
执行ODPS SQL,如两个数一样则说明导入成功,如不一样,请重试。
-- 验证数据总数
SELECT COUNT(*) FROM odps_test_history;
SELECT COUNT(*) FROM odps_test;
5. 删除历史临时表
如确认数据无误,则可以删除临时表。当然你也可以不删除,以便出了错只需将此时间节点内的数据导入即可,避免从头导入的过程。
--- 删除历史表
ALTER TABLE odps_test_history DROP IF EXISTS PARTITION ( pt='history' );
6. 更改同步脚本
更新同步脚本,并将任务进行提交,之前的第一步操作的暂停记得勾掉。
更改后的同步脚本如下,请注意蓝色部分:
7. 完成
如果执行到这一步基本上就完成了,隔天就会在你在设定时间内运行,你也可以去运维中心中查看你的任务情况。
下面附上”不会变化的数据“数据同步的全部流程图: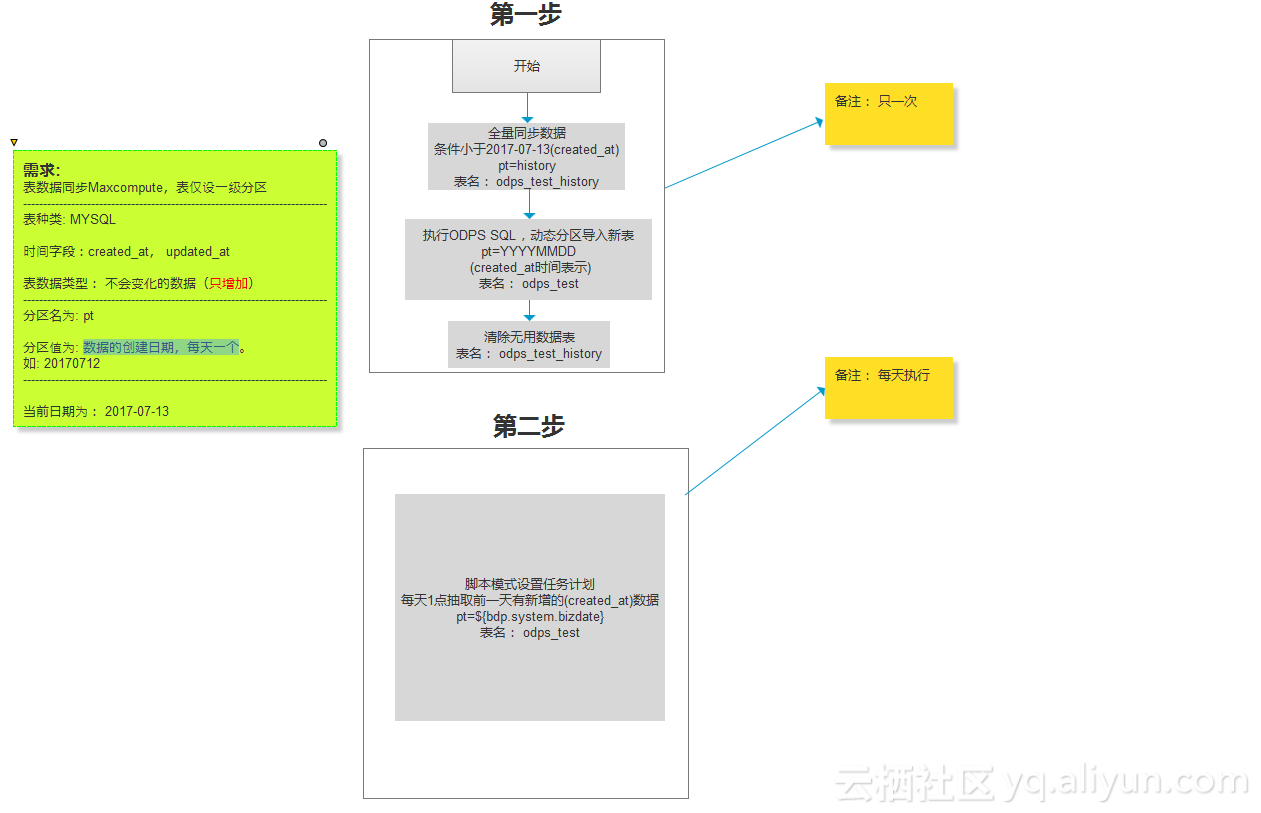
3.5.2 同步会变化的数据
注意事项:
A. 为方便演示,继续使用test表来作为演示表。
B. 同步会变化的数据与不会变化的数据,前面5个步骤一样是一样,在此不进行复述。
1. 手动全量同步
参考同步不会变化的数据
2.创建最终目标表
参考同步不会变化的数据
3. 根据数据的时间进行动态分区
参考同步不会变化的数据
4. 简单验证数据
参考同步不会变化的数据
5. 删除临时表
参考同步不会变化的数据
6. 创建增量表
执行ODPS SQL,创建一张增量表
--- 创建增量表
CREATE TABLE odps_test_inc LIKE odps_test;
7. 更改同步脚本
更改后的同步脚本如下,请注意蓝色部分:
因为太长不好截图,所以脚本模式这里的where的参数值使用:
FROM_UNIXTIME ( created_at,'%Y%m%d')=${bdp.system.bizdate} OR FROM_UNIXTIME(updated_at, '%Y%m%d') = ${bdp.system.bizdate}
如果想效率更高一点可使用下方语句,当字段created_at有索引时可以命中:
(created_at >= UNIX_TIMESTAMP('${bdp.system.bizdate}000000') AND created_at <= UNIX_TIMESTAMP('${bdp.system.bizdate}235959')) OR (updated_at >= UNIX_TIMESTAMP('${bdp.system.bizdate}000000') AND updated_at <= UNIX_TIMESTAMP('${bdp.system.bizdate}235959'))
8. 创建合并数据(ODPS_SQL)任务
在数据开发->任务开发中创建一个节点任务,任务名称使用_merge结尾
并输入以下内容:
--- 合并数据并根据数据的创建时间更新到指定分区中
INSERT OVERWRITE TABLE odps_test PARTITION (pt)
SELECT
CASE WHEN b.id IS NOT NULL THEN b.uid ELSE a.uid END AS uid,
CASE WHEN b.id IS NOT NULL THEN b.name ELSE a.name END AS name,
CASE WHEN b.id IS NOT NULL THEN b.age ELSE a.age END AS age,
CASE WHEN b.id IS NOT NULL THEN b.sex ELSE a.sex END AS sex,
CASE WHEN b.id IS NOT NULL THEN b.created_at ELSE a.created_at END AS created_at,
CASE WHEN b.id IS NOT NULL THEN b.updated_at ELSE a.updated_at END AS updated_at,
CASE WHEN b.id IS NOT NULL THEN TO_CHAR(FROM_UNIXTIME(b.created_at), 'yyyymmdd') ELSE TO_CHAR(FROM_UNIXTIME(a.created_at), 'yyyymmdd') END AS pt
FROM
odps_test a
FULL OUTER JOIN odps_test_inc b
ON a.id = b.id ;
--- 删除无用数据(如想观察每日数据变化不进行删除,上面一行的SQL需要加上条件: pt='${bdp.system.bizdate}')
ALTER TABLE odps_test_inc DROP IF EXISTS PARTITION ( pt='${bdp.system.bizdate}');
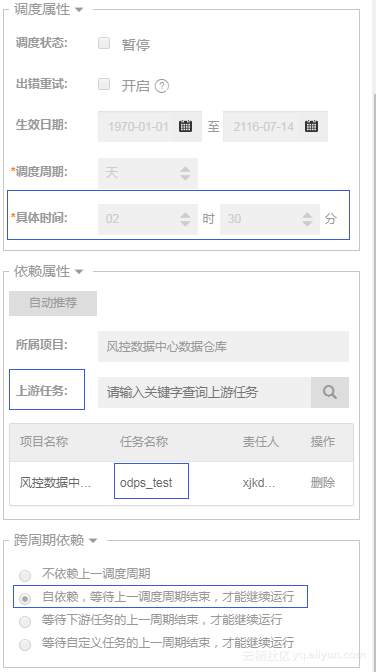
9. 设置调度依赖
将合并数据的任务的上游任务设置为每日增量同步数据那个任务,并提交即可。
注: odps_test是就是同步数据的脚本模式的任务名称。
10. 完成
如果执行到这一步基本上就完成了,隔天就会在你在设定时间内运行,你也可以去运维中心中查看你的任务情况。
下面附上”会变化的数据“数据同步的全部流程图: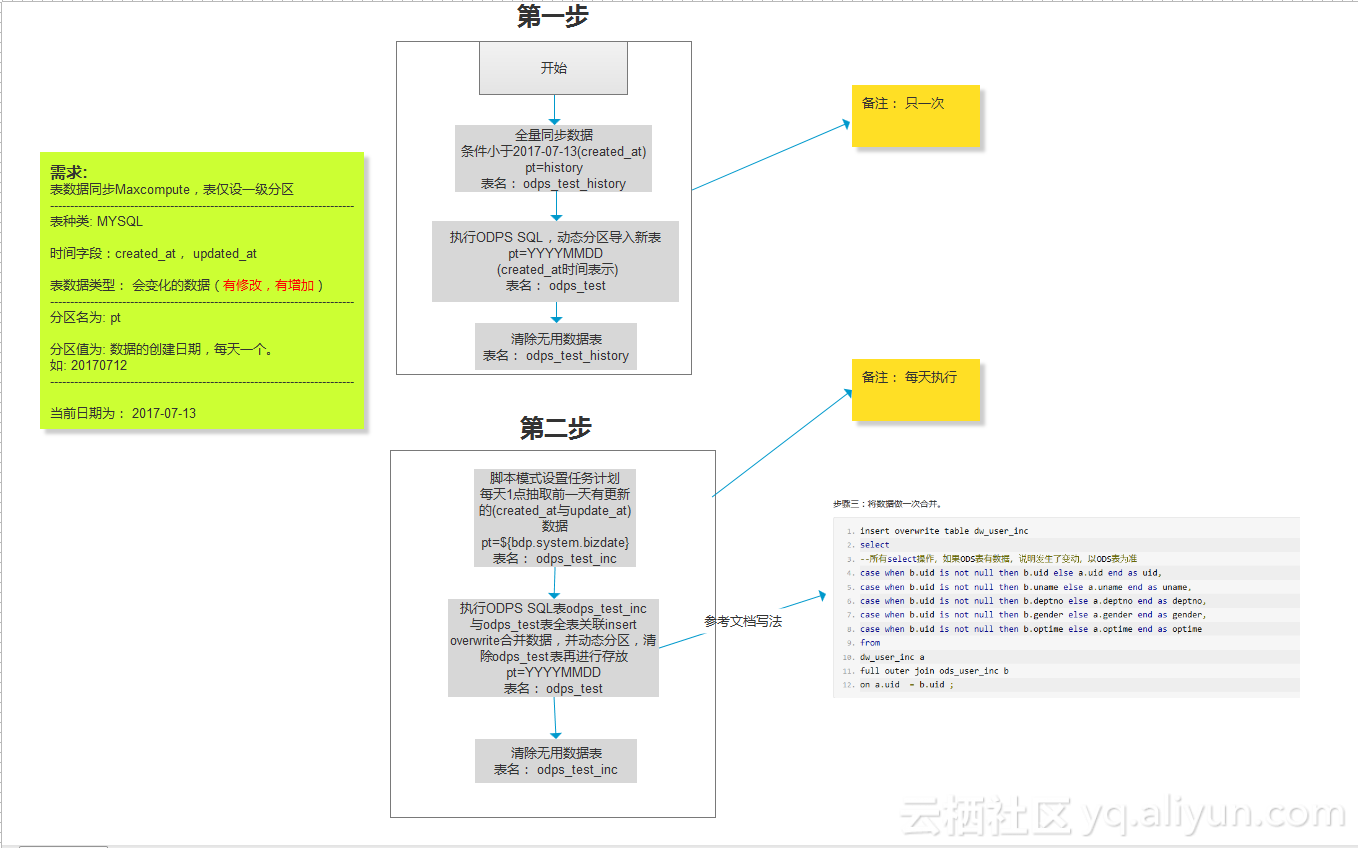
四、数据迁移
4.1 脚本模式下mongodb同步MaxCompute,时间字段值存的unix时间戳如何筛选?
这个问题我之前也有提交过工单,工单内容如下:
我们在测试使用数据同步更新,使用query参数过滤数据,按文档中所描述,语法参照MongoDB查询语法
https://help.aliyun.com/knowledge_detail/50354.html?spm=a2c1i.8282367.0.0.OPStre因为我们mongodb表中表示数据"最后更新时间"的字段为updated_at,其存放的内容为unix时间戳。
mongodb中将日期格式化成unix时间戳的方法是:ISODate("2012-10-15T21:26:17+0800").valueOf() / 1000根据该写法,那在脚本模式中的写法将是:
"query": "{'updated_at':{'$gte':ISODate('${last_day}T00:00:00.424+0800').valueOf() / 1000}}",但是我们运行后,程序报错无法运行了,报错信息为说是格式的问题,解析不了。
报错信息如下:
2017-06-23 20:46:32.647 [job-37098472] ERROR JobContainer - Exception when job run
org.bson.json.JsonParseException: Invalid JSON input. Position: 62. Character: '.'.当mongodb中字段为unix时间戳时,如果使用query参数进行过滤?
我们花了时间查看文档依旧没有得到答案,所以前来请教一下。
最终MaxCompute技术人员给的解决方案如下:
- dataworks 里面配置shell + datax, 在shell 里面讲dataworks的调度时间参数yyyy-mm-dd格式 转换为 unix时间戳格式, 时间戳传递给datax,再由datax发给mongodb server 做数据过滤查询。
- 在mongodb server 表里面添加时间列,时间列的值具体是你原来整数unix时间戳列生成的, 这个只需要操作修改一次。
4.2 脚本模式下mongodb同步MaxCompute,同步速度如何优化?
因为各种原因我们一开始是拿MongoDB进行的测试,为此专门找DBA挑一张较小的数据表( 约3GB左右)进行。按照文档中描述,使用脚本模式根据文档进行了配置,确实很挺简单的,所以进行任务测试,任务如期正常运行,但经过观察发现数据同步的速度逐步下降,最让人无法忍受的只有10KB/S,该表同步了20多个小时都没同步完,最后任务自行中止了。经过询问相关技术人员,可能由于Mongodb同步数据的底层实现还存在一些问题导致同步速度过慢导致的。为此只能选择替代方案,主要集中在“基于Kettle的MaxCompute插件”及“基于Tunnel SDK开发”,经过比对后考虑到开发速度及同步速度,最终选择暂时采用Kettle来进行mongodb的导入工作。
如下为导入速度对比结果: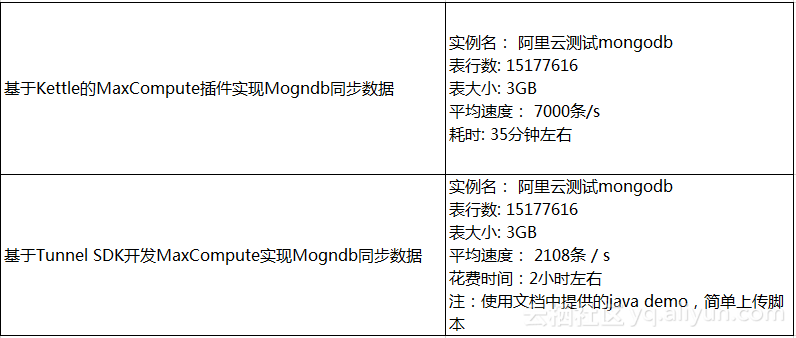
4.3 基于Kettle的MaxCompute插件同步mongodb遇到的问题
以下为我的同事在使用中的经验总结,在此我一并提一下:
MaxCompute的kettle插件的问题(个人只用过Aliyun MaxCompute Output,没有用过Aliyun MaxCompute Input,因此只对Output部分做评价):
1. 没有提供更新的功能,只能插入,做增量更新的时候会很棘手。
2. 没有提供输出流,无法记录日志。
3. 不支持从上一步获取变量的功能,对于想要使用变量替换的操作很麻烦。
4. EndPoint、AccessId等配置不支持从配置文件读取,十分不灵活。
5. 文档太少,没有提供对MongoDB等数据库的帮助文档。
4.4 Mysql全库同步工具时间字段是unix时间戳没办法用。
因为我们有大量的Mysql数据表需要导入,发现有个整库迁移的工具可以使用,刚发现时就怦然心动,然而经过实测后大失所望,因为该工具日期字段的值必须是yyyymmdd格式,像我们使用UNIX时间戳压根没法用。
另外该功能不支持表字段指定,如果某些数据表字段过于敏感想不进行同步,也不能设置。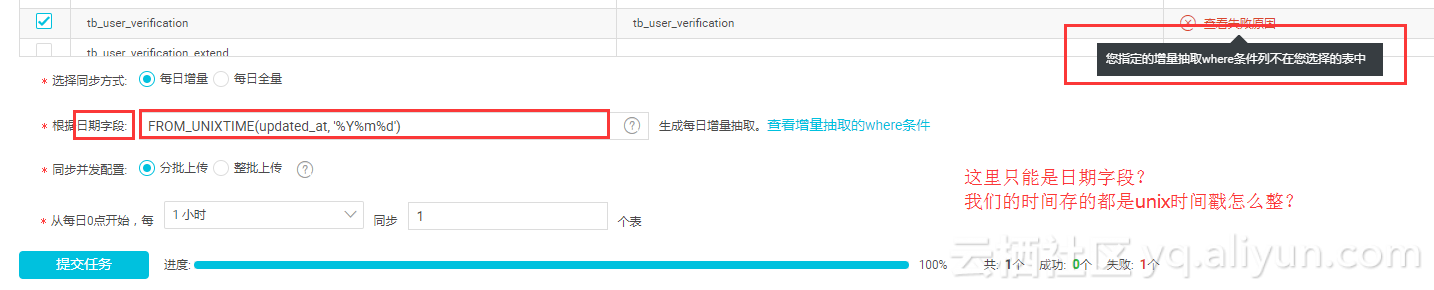
4.4 大数据开发套件中“数据表管理”如果表数量过多就不便于查找,且数据表分类只有一级。
如果左侧能提供一个树形菜单将多级分类列出,点击就能查看对应分类下的表就方便多了。
五、感谢
接触一件新事务时遇到了困难,并且自己无法解决时,难免会感到彷徨无助,有种挫败感。
万幸的是我在钉钉上找到了组织,非常感谢阿里云MaxCompute项目组的@数加·祎休(yī xiū)、@一斅、@彭敏、@李珍珍等工作人员的鼎力支持,在我们提交问题后,不厌其烦及时并且认真的回答解决我们的问题,祝你们工作顺利,事事顺心。