随着大数据平台型产品方向的深入应用实践和Docker开源社区的逐渐成熟,业界有不少的大数据研发团队开始拥抱Docker。简单来说,Docker会让Hadoop平台部署更加简单快捷、让研发和测试团队集成交付更加敏捷高效、让产线环境的运维更加有质量保障,而这背后的业务场景和具体的实践方法有哪些?在Docker容器服务逐步走向完善的过程中,大数据平台产品Docker模式的应用又是如何解决的?正是本文所着重阐述的。
实践中发现问题
场景一
在大数据平台型产品的开发过程中,经常要跟许多模块打交道,包括Hadoop、HBase、Hive、Spark、Sqoop、Solr、Zookeeper……等多达几十个开源组件,为了不影响团队成员间的工作任务协同,开发人员其实非常需要自己有一套独立的集群环境,以便反复测试自己负责的模块,可真实的企业开发环境往往只有一两个大的虚拟集群,这可怎么办?难道要给每个开发人员都配几台独立的物理机器?

场景二
针对每一次新版本的发布,产品测试组都需要反复的重装整个平台以便发现问题,而正如本文前面所阐述的那样,大数据平台所依赖的组件繁多,不同组件模块依赖的底层库也不尽相同,经常会出现各种依赖冲突问题,而一旦安装完成,就很难再让Linux系统恢复到一个非常干净的状态,通过Remove、UnInstall、rpm -e等手动方式卸载,往往需要花费很长的时间,那如何才能快速地恢复大数据平台集群的系统环境?

场景三
当测试人员在测试大数据平台过程中发现了一个Bug,需要保存现场,这里面包括相关的大数据组件配置、进程状态、运行日志、还有一些中间数据,可是,平台集群服务器节点数量很多,针对每个进程的配置目录和日志文件,都相对较独立,一般都需要专业的开发工程师或者运维工程师进入相关服务器节点,按照不同组件的个性化配置信息,手工方式收集所需的各个条目信息,然后打包汇集到日志中心服务器进行统一分析,而目前业界并没有一款能够自动分布式收集故障相关的日志系统,但测试工作还要继续,怎么办?

场景四
如何把一个部署好的大数据平台快速地迁移到其它地方?
你得注意以下几点:
- 如果是关键业务系统,数据不能丢;
- 如果是迁移物理机,机器可能会坏;
- 如果是不间断实时在线业务,要保证快速平稳切换。

传统解决方案的缺陷
想要解决这些问题,第一个想到的方案当然是用虚拟机,而笔者经历的团队,之前也确实用的就是虚拟机,但这种方式并不能完美的解决以上问题,比如:
- 虽然虚拟机也可以完成系统环境的迁移,但这并不是它所擅长的,不够灵活,很笨重。
- 虚拟机的快照可以保存当前的状态,但要恢复回去,就得把当前正在运行的虚拟机关闭,所以并不适合频繁保存当前状态的业务场景。
- 虽然可以给每个人都分配几个虚拟机用,但它是一个完整的系统,本身需要较多的资源,底层物理机的资源很快就被用完了,所以我们需要寻找其它方式来弥补这些不足。
Docker技术的引入
Docker 项目的目标是实现轻量级的操作系统虚拟化解决方案,换句话说,它可以让我们把一台物理机虚拟成多台来使用,而且它还可以保存修改、完整迁移到其它地方、性能损耗小等等好处,能够很好解决我们之前遇到的问题。
那为什么不用虚拟机方案?
简单来说,因为它比虚拟机更轻便,启动一个Docker容器只要几秒种的时间,在一台物理机上可以创建几百上千个容器,而虚拟机做不到。
下面是虚拟机与Docker两种方案的实现原理:
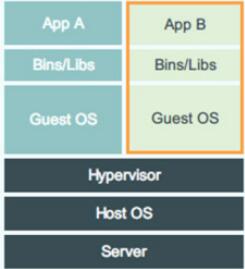
VM设计图
虚拟机实现资源隔离的方法是利用独立的OS,并利用Hypervisor虚拟化CPU、内存、IO设备等实现的。例如,为了虚拟CPU,Hypervisor会为每个虚拟的CPU创建一个数据结构,模拟CPU的全部寄存器的值,在适当的时候跟踪并修改这些值。需要指出的是在大多数情况下,虚拟机软件代码是直接跑在硬件上的,而不需要Hypervisor介入。只有在一些权限高的请求下,Guest OS需要运行内核态修改CPU的寄存器数据,Hypervisor会介入,修改并维护虚拟的CPU状态。
Hypervisor虚拟化内存的方法是创建一个shadow page table。正常的情况下,一个page table可以用来实现从虚拟内存到物理内存的翻译。在虚拟化的情况下,由于所谓的物理内存仍然是虚拟的,因此shadow page table就要做到:虚拟内存->虚拟的物理内存->真正的物理内存。
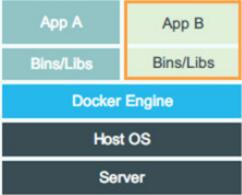
Docker设计图
对比虚拟机实现资源和环境隔离的方案,docker就显得简练很多。docker Engine可以简单看成对Linux的NameSpace、Cgroup、镜像管理文件系统操作的封装。docker并没有和虚拟机一样利用一个完全独立的Guest OS实现环境隔离,它利用的是目前Linux内核本身支持的容器方式实现资源和环境隔离。简单的说,docker利用namespace实现系统环境的隔离;利用Cgroup实现资源限制;利用镜像实现根目录环境的隔离。
当新建一个容器时,docker不需要和虚拟机一样重新加载操作系统内核。我们知道,引导、加载操作系统内核是一个比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,这个新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了这个过程,因此新建一个docker容器只需要几秒钟。另外,现代操作系统是复杂的系统,在一台物理机上新增加一个操作系统的资源开销是比较大的,因此,docker对比虚拟机在资源消耗上也占有比较大的优势。事实上,在一台物理机上我们可以很容易建立成百上千的容器,而只能建立几个虚拟机。
可见容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统方式则是在硬件层面实现。当然,一些容器核心模块依赖于高版本内核,存在部分版本兼容问题。
如何基于Docker实现大数据平台的敏捷部署与运维?
第一步:搭建基础的Docker环境
在实践过程中,部署一套可用的大数据平台Docker环境,必需做好以下前提工作:
- 搭建私有镜像仓库,用来统一存放构建好的镜像文件
- 搭建一个安装包仓库,用来存放我们发布的各种版本的大数据组件安装包
- 配置多个物理机上的Dcoker容器可以相互通信,可参考官方给出的方案
第二步:为大数据平台定制基础镜像
1.既然要在Docker容器内安装我们的大数据平台,那就需要一个统一的Linux系统做为我们的Dcoker容器,像Ubuntu、CentOS等发行商都会发布自己的Docker基础镜像到Docker Hub上,如果Docker Hub上恰好没有你需要的镜像,也可以自己制作。
2.比如用CentOS6.8做为我们的基础镜像,那么请先把它pull下来

3.然后我们用这个镜像创建一个容器,并在里面配置一些我们大数据平台依赖的参数,比如ntpd、httpd服务等等,最终生成我们平台专属的基础镜像。
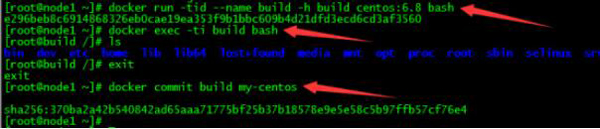
4.这是很关键的一步,有了它以后,所有人员可以随时创建一个自己需要的Linux环境出来,以便在其内进行产品的研究和实验,且每个人的环境互不相干,当容器内的环境被破坏后,可以删掉再创建,这样一来,场景一和场景二所遇到的问题也就迎刃而解。
第三步:将已经部署好的集群做成镜像
我们可以把已经部署了集群的容器保存成多种镜像,如:只包含了Hadoop的集群、同时包含Hadoop、Zookeeper、Hbase的集群,或安装了所有组件的集群等等,然后上传到私有仓库,其它人需要的时候,直接启动自已需要的集群就可以了,因为免去了部暑与配置等步骤,因而大幅度提高了工作效率,也提高了产品迭代速度。
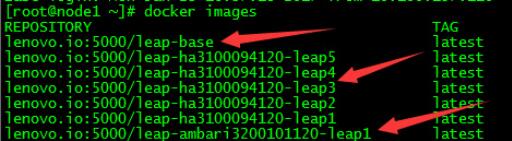
上图是已经做好的镜像,图中共三种类型的镜像:
- 第一个箭头指基础镜像
- 第二个箭头指的是已经安装了大数据平台的镜像,因为是分布式,所以有五个
- 第三个是单节点版的大数据集群,所以只有一个镜像
第四步:镜像的修改与保存
Docker提供了commit功能可以将一个正在运行的容器保存起来,假如在测试过程中遇到一个Bug并且需要先保存下来,执行一条简单的命令即可,如:
- # docker commit container_name image:v2
在以后需要复现的时候用这个镜像创建容器即可,像下面这样
- # docker run -tid –name c1 image:v2 bash
但注意,并不是所有状态都能被保存下来,它只保存文件层面的状态,不能保存内存中的状态,所以再次启动容器的时候,容器内的所有服务都已经变成了停止状态,需要再手动启动一次,这样就导致有些类型的Bug不能复现。
不过欣慰的是,Docker官方打算在后面的版本中加入checkpiont功能,它可以保存容器中的所有状态,这样就可以完整地复现Bug,这个新功能的用法就像下面这样:
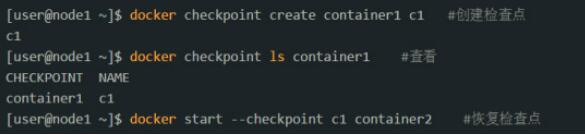
这个功能对很多人来说,绝对是个好消息!
第五步:脚本化部署、监视、删除
当然了,每个人都不应该把过多的精力放在怎么使用Docker的问题上,这样会为团队带来额外的工作量,最简单的办法当然是把所有重复性的工作脚本化,向每个人提供最简便的使用接口,只需要一条简单的命令就可以创建自己想要的集群环境,当不需要的时候一条命令即可删除,这样即降低了学习成本又解决了容器管理问题。
根据笔者的实践经验,脚本化的实现应该着重考虑几个方面:
- 多种类型集群的创建
- 记录每个集群的所属者,容器所属的物理机,创建时间等等
- 可实时查看所有容器的运行状态,物理机资源使用情况
- 删除指定的集群
结语
现在已经有很多开源的Docker容器管理框架,但需求总是复杂多变的,并不能适用所有的场景。比如笔者所负责的大数据平台就需要为每个容器做端口映射、内含大数据组件的镜像在启动后还需做Hostname与IP映射等,总之,目前开源容器框架的易用性还有很大的改进空间,都存在一些手动配置的工作。
关于容器服务,在具体的实践过程中,一定还会遇到很多问题,比如服务发现和编排。当下在应用层面虽还算不上特别的成熟,但已经使原本部署与配置很复杂的大数据平台变得简单快速,让一部分研发团队的产品迭代得到加速。当然,不管是大数据平台产品,还是Docker开源社区本身,都还在不断的完善中。
本文作者:佚名
来源:51CTO