Programming pipeline & shading language
大家好,今天想给大家介绍一下可编程渲染管线和着色器语言的相关基础知识,使想上手SHADER编程的童鞋们可以快速揭开SHADER语言的神秘面纱
由于时间有限,我决定只讲三个主要方面的内容,其过程中肯定会有不详细之处,还请见谅,就算是抛砖引玉,给大家一个简单的入门引路。
本章内容总共分为三个部分 一、3D渲染管线工作流程 二、可编程管线 三、着色器语言
3D渲染管线作为整个工作流程的基础,是不可或缺的基本知识。因此,作一定的讲解是有必要的。 但作为一个回顾内容,就不会对具体的内容进行讲解,比如如何进行坐标系变换,如何进行光栅化等等。 我们仅关注的是整个工作的过程。
甚至,我们更关心的不是整个工作过程中的细节,而是我们所必须要关注的几大流程。 如下图
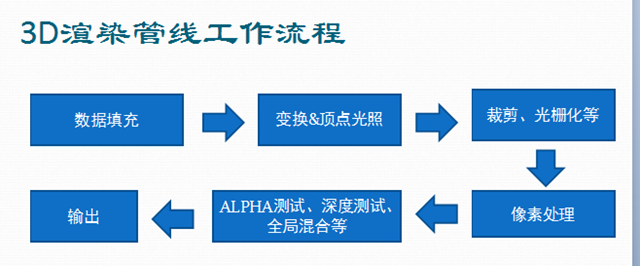
数据填充
当我们想实现一次渲染效果的时候,数据的提交(填充)是不可缺少的。 因此,工作流程的第一步就是要处理输入的数据。
而我们最直接的接触3D渲染流程的时机,也就是数据填充时,更确切的说,就是那一堆set数据的API。
数据填充允许我们提交我们想要的数据,比如顶点数据(如位置,法线,颜色,纹理坐标等)。常量(如世界矩阵,观察矩阵,投影矩阵,纹理因子等等)。

变换&顶点光照
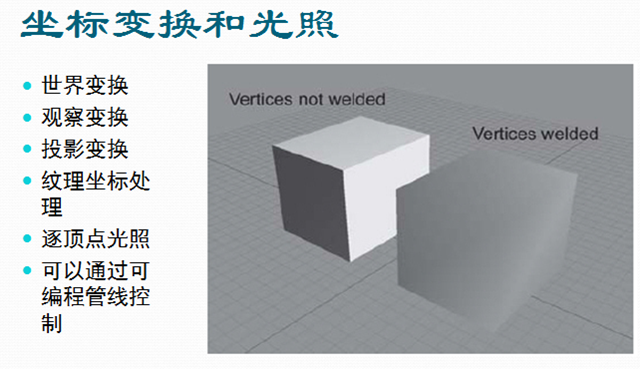
在这个阶段,顶点会经过世界变换,观察变换,投影变换。 通常情况下,在顶点经过观察变换后,便开始做一些光照计算。 这一阶段也是可编程管线所提供的顶点处理阶段。也就是说,我们可以通过着色器程序来控制这一阶段的结果。 在着色器程序中,我们可以任意地处理想要的数据,比如进行纹理坐标缩放,旋转,随机偏移等等。
裁剪&光栅化
当经过坐标变换和光照后,顶点已经被投影为2D坐标+深度信息。 一些不可见的顶点会被裁剪掉,比如那些处于背面的点。 同时,剩下的顶点会被插值计算,以形成由像素构成的图元。 所有的信息都会被插值,如纹理坐标,法线,颜色等。

像素处理
像素处理阶段是一个最耗时,但是也是最能够使你的渲染效果品质更高的地方,像素最终的样子会在此决定,你可以进行纹理映射,纹理混合,模糊,扩散等效果。
这也是可编程管线中可以使用SHADER控制的另一个处理过程,

像素的一些额外处理和输出
当像素经过像素处理阶段后,并不能都有机会输出到屏幕上,因为它们还要经过深度(也有一些比较优化的渲染管线将深度测试提到了像素处理前)和模板测试,ALPHA测试,经过这些测试后, 还要进行一次ALPHA混合,这次与目标缓冲区的混合,就能够实现半透明效果。 虚拟世界中的五光十色就是因为这个半透明效果而生动。

可编程管线
正如上面所说,在3D渲染流程中,我们能够用着色器语言控制的就是“顶点变换和光照” 以及 “像素处理”阶段。 在我们讲如何控制之前我大概介绍一下GPU中用于处理着色器的最基本的帮手 - 寄存器。

GPU中的寄存器与CPU中的普通寄存器有一点不同, GPU中的每一个寄存器都是一个四维向量寄存器,即一个寄存器拥有4个浮点分量。 通常我们用
(x,y,z,w)或者(r,g,b,a)来表示。
输入寄存器
输入寄存器是GPU用来接受数据的寄存器,当我们将渲染数据填充到GPU时,其实就是将这些数据填充到这些输入寄存器上。
比如,当我们将一个顶点的位置和法线提交后,GPU在处理这个顶点时,其对应的寄存器就会拥有这个顶点相应的值。
顶点处理阶段和像素处理阶段用到的输入寄存器是不同的。输入寄存器决定了对应的处理阶段能够做的事情。
比如,我们提交了一个三角形的顶点和纹理坐标信息,并且我们提交了一张纹理,用来对这个三角形做纹理映射。 但是,我们是不能在顶点处理阶段就对其纹理做处理的。 因为我们不能在顶点处理时访问纹理数据(如果真要这样,那就只能够使用顶点纹理了,这个内容超出了本次介绍的范围,固不再多说)。
常量寄存器
常量寄存器用来向着色器传递我们所需要控制的常量信息,比如,世界矩阵,观察矩阵,投影矩阵,纹理矩阵等。 以及我们可以设置一些值,比如当前时间,用来实时偏移一个顶点的纹理坐标,使其纹理呈移动的效果。 又或者通过这个值,动态改变顶点的位置,使其出现波动效果。 这些就是常量寄存器可以干的事。
同样,常量顶点处理阶段和像素处理阶段使用的常量寄存器也是不同的。不过,这种情况在SM 4.0以后得到改善,并且有一个趋势,就是顶点处理和像素处理阶段界线不再那么明显。 他们可以共用寄存器,共用一些缓存。 但在你没有完全掌握它们的特点以前,还是老老实实记住这个特性吧。
临时寄存器
临时寄存器使我们能够在着色器处理的过程中存放一些临时的值,若你是用高级着色语言编写着色程序,那你是感觉不到临时寄存器存在的,因为你仅仅是声明了一个临时变量。 但确实,这就是临时寄存器的功劳。 它才是真正的幕后黑手。
纹理采样寄存器
纹理寄存器用于存放你所提交的纹理,并且提供纹理采样功能。 如临近点采样,双线性采样,三线性采样等。 这些都肯定你的指示来做相应的工作。 它主要是辅助你完成纹理映射工作。
输出寄存器
输出寄存器就是你着色程序能够输出的内容,输出内容通过输出寄存器传递出来。 顶点处理程序的输出有两种, 一种是输出到帧缓冲,另一种是输出给像素处理程序,最典型的就是纹理坐标数据, 当顶点处理程序拿到输入寄存器传递过来的纹理坐标值后,经过一些处理,又输出。 而真正需要使用这个信息的,就是像素处理程序。
常见的有 位置,纹理坐标,颜色等。
着色器语言
下面,我们来看一下着色器语言吧。

着色器程序就如上面讲的那样,分为了顶点着色程序和像素着色程序。 你可能会发现,这里多了一个几何着色程序,这个是后来新加入的兄弟,传统的着色程序不能增加删除顶点。 但是,它可以。 有兴趣的童鞋中以继续去了解。
着色器语言有高级语言和低级语言两种。 低级语言采用的是汇编那种助记符方式。
如 dp4 r0,v0,c0 这样的,表示将v0,c0点乘,并放入临时寄存器r0中。
而高级语言则是C风格的,很符合人们的编程习惯。 与传统的编程语言发展规律是相同的。
如 float temp = dot(dir,normal);
而常见的着色器语言中,低级语言如D3D中的LLSL,以及Adobe新出的Statge3D协同工作的AGAL.
高级语言如 CG,HLSL,GLSL应该很熟了吧。
CG是NVIDIA公司出的语言,它可以在D3D和OPENGL中工作,但需要使用NVIDIA对应的SDK。
HLSL是D3D协同工作的高级着色器语言。
GLSL是OPENGL协同工作的高级着色器语言。
着色器代码示例
说了这么多,我们来看看一个简单的例子吧。 HLSL版
我打上了注释,就不再叙述
![]()
//VERTEX SHADER
float4x4 matViewProjection; //世界-观察-投影矩阵
struct VS_INPUT //输入结构,这个结构中的内容,表示我们SHADER所关心的内容,同时,程序在进行数据填充时,应该保证这些关注的数据被提交
{
float4 Position : POSITION0; //位置
float2 Texcoord : TEXCOORD0; //纹理信息
};
struct VS_OUTPUT //输出结构,这个结构中的内容,表示此SHADER的输出
{
float4 Position : POSITION0; //位置信息,已经经过坐标系变换
float2 Texcoord : TEXCOORD0; //纹理信息
};
VS_OUTPUT vs_main( VS_INPUT Input ) //顶点程序的入口函数
{
VS_OUTPUT Output; //声明一个结构体
Output.Position = mul( Input.Position, matViewProjection ); //做矩阵变换
Output.Texcoord = Input.Texcoord; //直接输出纹理信息, 如果你想对它做点手脚,是很容易的。 这就是FFP中纹理矩阵所做的事情。
return( Output );
}
//PIXEL SHADER 它就相对简单多了
sampler2D baseMap; //纹理
struct PS_INPUT //输入结构,与VS中的输入结构类似,但此输入结构均来自于VS的输出。
{
float2 Texcoord : TEXCOORD0; //表示我们只需要用到纹理坐标信息
};
float4 ps_main( PS_INPUT Input ) : COLOR0 //出口函数。 COLOR0表示我们输出的float4是用作颜色输出, 也可以定义类似 PS_OUTPUT的结构
{
return tex2D( baseMap, Input.Texcoord ); //很简单,就是取得对应纹理坐标处的像素值,输出, 你可以在此做一些事情,比如调得更亮,或者拿另一张纹理采样,与它混合。 混合的公式就由你自己定了,你想写得多复杂都可以。 理论是如此。
}
//========== 感兴趣的朋友可以看看上面的SHADER对应的低级版本==========
// VS
// Generated by Microsoft (R) HLSL Shader Compiler 9.22.949.2248
//
// Parameters:
//
// float4x4 matViewProjection;
//
//
// Registers:
//
// Name Reg Size
// ----------------- ----- ----
// matViewProjection c0 4
//
vs_2_0
dcl_position v0
dcl_texcoord v1
dp4 oPos.x, v0, c0
dp4 oPos.y, v0, c1
dp4 oPos.z, v0, c2
dp4 oPos.w, v0, c3
mov oT0.xy, v1
// approximately 5 instruction slots used
//PS
//
// Generated by Microsoft (R) HLSL Shader Compiler 9.22.949.2248
//
// Parameters:
//
// sampler2D baseMap;
//
//
// Registers:
//
// Name Reg Size
// ------------ ----- ----
// baseMap s0 1
//
ps_2_0
dcl t0.xy
dcl_2d s0
texld r0, t0, s0
mov oC0, r0
// approximately 2 instruction slots used (1 texture, 1 arithmetic)
![]()
Let it go
说到这里,差不多要结束了。但还是再多说两句。
由于硬件条件的限制 VS和PS中对指令条数和可使用的寄存器个数都有限制,虽然随着硬件的发展,这个限制已经可以被忽略了。比如SM 4.0就已经将这个限制放宽到很大。
但当我们在写着色程序时,除了追求效果外,还要追求效率。因此,节约使用资源将会提升效率, 一个很好我评判标准就是你的SHADER所使用的指令数
如上面低级语言版本中 VS,PS都有如下内容
// approximately 5 instruction slots used
// approximately 2 instruction slots used (1 texture, 1 arithmetic)
因此,它将能够很直观地评估出你SHADER的效率。 但真正的结果,还是要实际测试。 由于硬件的不同,可能还存在兼容性上的问题。
祝各位一路顺风。
PS:上面的SHADER代码取自 RenderDonkey 这个软件 在ATI官网上可以下载。
或者,直接点这里http://developer.amd.com/archive/gpu/rendermonkey/pages/default.aspx
作者:码瘾少年·麒麟子
出处:http://www.cnblogs.com/geniusalex/
蛮牛专栏:麒麟子
简介:09年入行,喜欢游戏和编程,对3D游戏和引擎尤其感兴趣。
版权声明:本文版权归作者和博客园共有,欢迎转载。转载必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载:http://www.cnblogs.com/geniusalex/archive/2012/07/20/2601847.html