Emacs之魂(一):开篇
Emacs之魂(二):一分钟学会人界用法
Emacs之魂(三):列表,引用和求值策略
Emacs之魂(四):标识符,符号和变量
Emacs之魂(五):变量的“指针”语义
Emacs之魂(六):宏与元编程
Emacs之魂(七):变量捕获与卫生宏
Emacs之魂(八):反引用与嵌套反引用
Emacs之魂(九):读取器宏
1. 语义学
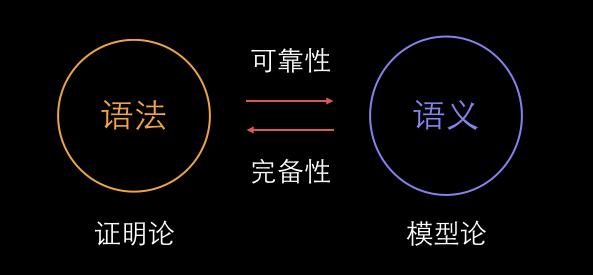
在计算理论中,形式语义学是关注计算模式和程序设计语言含义的严格的数学研究领域。
语言的形式语义是用数学模型去表达该语言描述的可能计算来给出的。
提供程序设计语言形式语义的方法很多,其中主要类别有:
操作语义(operational Semantics),指称语义(denotational semantics),
公理语义(axiomatic semantics),代数语义)(algebraic semantics)。
1.1 操作语义
将语言成分所对应的计算机系统的操作,作为该语言成分的语义,这样的建模方式称为操作语义学,
语言的操作语义应该是标准的,不应该依附于一个特定的计算机系统,
因此,人们使用抽象的机器和抽象的解释程序来定义语言的操作语义。
操作语义学的基本思想来源于编译器和解释器,编译器或者解释器描述了程序语言的具体实现。
操作语义最早被用于定义Algol 68的语义,
1964年Peter Landin使用了SECD machine这种抽象机器,定义了表达式的操作语义。
1980年,Gordon Plotkin提出了结构操作语义(structured operational semantics),它在更一般的数学结构上用归约关系(reduction relation)建立了语义的解释系统,
这种语义学具有结构化的特征,语言中复合成分的语义是由其子成分的语义复合而成的,
结构操作语义,对软件工程中结构化编程具有重要的指导意义。
1.2 指称语义

人们用程序设计语言编程,计算机系统用于加工数据,
不同的计算机系统有不同的结构,因此对同一条命令的执行过程可能不同,但是最终结果应该是相同的。
指称语义学认为语言成分的含义是语言成分本身固有的,与计算机系统无关,
所以,不应该将语言成分的执行过程看做它的语义,语言成分的语义应该是它的执行结果。
这种将最终结果看做语言成分语义的建模方式,称为指称语义学,这个最终结果称为该语言成分的指称。
语言成分的指称一般是一个数学对象,如整数,集合等等。
指称语义学是Christopher Strachey于1964年提出的,
后来Dana Scott创建了论域理论(domain theory)为指称语义学奠定了数学基础。
指称语义学方法在定义语言的语义时,先确定语言成分的指称,然后给出语言成分与其指称之间的映射关系,
而且确定复合语言成分指称的过程是语法制导的(syntax-directed),也称为结构化的(structural),
即语言成分的指称只依赖于它的子成分的指称。
1.3 公理语义

公理语义在定义语义的时候,采用了数学中的公理化方法,
语言的公理语义构成了一个由“公理”和“定理”组成的逻辑证明系统,
它认为语言的语义,是由这个证明系统所能反映出来的一切性质。
操作语义可以看做公理语义的一种有向形式。
1967年,Robert W. Floyd提出了论证一个程序是否具有某种性质的数学方法,
1969年,Tony Hoare第一次用公理系统(Hoare logic)定义了一类程序设计语言的语义。
Hoare logic使用带有前置条件和后置条件的归纳命题(inductive proposition),作为描述语义的形式化工具。
1.4 代数语义
指称语义的研究方法建立在递归函数论基础之上,公理语义的研究方法建立在谓词逻辑基础之上,
代数语义学用代数方法研究计算机语言的语义,它建立在抽象代数的基础之上。
代数语义学描述了程序中不同种类(sort)的数学对象(object),以及这些对象之间的运算,它们构成了一种代数结构,
代数语义学,通过分析这种代数结构的性质,来描述程序的语义。
代数语义学源于人们对抽象数据类型(abstract data type)的研究,
泛代数(universal algebra)是一个用于研究抽象数据类型的数学框架。
在泛代数中,抽象数据类型的语法由代数项(algebraic term)描述,公理语义用项之间的等式集(a set of equations)描述,而指称语义对应于一个Σ代数,操作语义通过给等式设定方向来表示。
2. Lisp的Pointer semantics
2.1 Conceptual pointer
Lisp语言提供了一个简洁的计算模型,是因为它在语义上的简洁性,
Lisp语言中所有的值都可以“看做”指针,所有的内存都可以“看做”在堆(heap)中分配。
(defvar foo 5)
Lisp会在堆中为x分配内存,让它包含一个指针,指向另一块初始化为5的内存,
即,Lisp中的值总是可以“看做”指向堆内存的指针。
我们可以用下图表示:
+-------+
foo | *---+--->5
+-------+
Lisp语言的具体实现中,会采用不同的策略避免频繁分配内存的开销,
但是在语言层面对用户是不可见的。
2.2 pointer semantics & value semantics
和C语言不同的是,Lisp用户不用显式的释放内存,这使得心智负担大大降低了,
Lisp用户不用对指针解引用(dereference),因为默认每次都会这么做。
例如,算术加法函数+,接受两个指针作为参数,
它会在进行加法操作之前,自动对参数进行解引用,并且返回一个指向加法结果的指针。
(+ 1 2)
当我们对上述表达式求值的时候,加法函数会得到两个指针,分别指向1和2,
求值结果会返回一个指向3的指针。
大部分编程语言除了具有pointer semantics之外,还具有value semantics。
例如,它们会把1,2看做值,1和2的每次出现,都是不同的一份拷贝。
Lisp语言只有pointer semantics,1和2的每次出现都表示对唯一的数字对象的不同引用。
由于效率方面的考虑,具体实现可以做出任何调整,只要不影响pointer semantics。
人们常说Lisp,Smalltalk,Java等这些语言没有指针,其实不太合理,
而是应该说,所有的东西都是指针。(pointer semantics
把所有东西都实现为一个指针,代价是高昂的,
我们必须把所有的指针,以及它指向的对象,全都分配在堆中。
还必须使用额外的操作访问这些内存。
幸运的是,Lisp的具体实现中,并不会这样表示它们,会对多种情况进行优化。
例如,变量中会直接保存数字的二进制形式,而不是一个指向堆内存的指针。
使用标签(tag)与那些具有相同二进制模式的指针进行区分。
2.3 例子
在Lisp语言中,一个pair(又称为cons cell),是一个在堆中分配的对象,
它包含两个字段,每个字段都可以包含任意种类的值,
例如,数字,字符,布尔值,或者一个指向其他堆内存的指针。
由于历史原因,第一个字段称为car,第二个字段称为cdr,
pair可以通过cons函数来创建。
(cons 22 15)
以上表达式创建了一个pair,它包含了两个字段,
其中car字段为22,cdr字段为15。
我们可以用下图来表示:
+-----------+
header| <PAIR-ID> |
+===========+
car| *-----+----->22
+-----------+
cdr| *-----+----->15
+-----------+
其中,header用于保存类型信息,用于表明在堆中分配了什么类型的对象,Lisp用户不必关心header的值。car字段包含了一个指针,指向了22,cdr字段包含了另外一个指针,指向了15。
(defvar foo
(cons 22 15))
假设我们定义了一个全局变量,让它的值为一个pair,于是我们可以用下图来表示:
+---------+
+---------+ header| <PAIR> |
foo | *----+------------->+=========+
+---------+ car| *----+---->22
+---------+
cdr| *----+---->15
+---------+
变量foo指向了一个pair,pair中的两个字段分别指向了22和15。
使用car函数和cdr函数可以得到pair中保存的两个字段的值,
(car foo)
> 22
(cdr foo)
> 15
参考
形式语义学引论 - 周巢尘
程序设计语言理论基础
Syntax and Semantics of Programming Languages
An Introduction to Scheme and its Implementation