Youtube视频链接:https://www.youtube.com/watch?v=aWgtRKfrtMY
2015年讲过一次,主要集中在chaos monkey上,这次是2016年在Re:Invent上的演讲,增加了不少内容。没有过多地去说一些技术,focus在technical thinking, strategy & culture 三个方面。
演讲者是Dave Hahn。Senior Engineer in Netflix's Operations and Reliability Engineering team. 类似我们的SRE团队,因此内容中更多的是operation(deploy、monitor)和reliability相关的内容。
Netflix当前是什么,需要什么样的技术
- big:
- 高峰期有100k 台EC2实例
- 每天有20%业务是AutoScaling进行弹性伸缩
- ELB Traffic > 50 Gbps / Per Region
- 网络流量 Peak Time > 37% internet traffic of USA
- fast:在大体量的同时仍能带来非常多的创新
- 推出了Airplane, car等渠道的版本
- 媒体:1 billion hours streamed
于是回到了一个问题:技术和文化如何保障又大又快?
principle of chaos
估计是之前有3-4次因受到AWS故障影响损失惨重,三四年前Netflix已经搞出了ChaosMonkey来模拟各种故障,ChaosMonkey内容网上很多,可以直接参考。
关于Chaos Principle,提到四个点:
1. hypothesize: focus on what the system produce
对所有系统行为都能够以黑盒进行量化,而不是内部属性和设计(这个主要是从SRE视角出发的观察)。 例如当故障或某一个状态发生到恢复期间,系统的吞吐量,错误率,延时分布等。通过Chaos Monkey等线上实验反复论证“系统黑盒”是否符合预期,而不是开发号称的理论上、设施上Metric应该达到多少等等。
Chaos Engineering系列:
| 类型 | 范围 | 目标 | 工程方法(推测) |
|---|---|---|---|
| Chaos Monkey | Region 内 | 当有大量实例Fail情况下,如何保证服务不受到影响 | lots of instance fail should not affect the service |
| Chaos Kang(KingKang) | Region 间 | 当Region down情况下,不影响所有的流量(如何保证影响可控,并且可以快速从其他Region切换) | Region间准实时复制 |
| Chaos Chap(Chaplin) | 微服务级 | microservice之间的故障不影响相互影响 | 设置合理Timeout,松耦合设计 |
2. Vary Real-world Events
考虑现实中的情况,对可能发生的状况根据影响面、以及发生频率制定优先级。例如在分布式系统设计时,我们经常会各种硬件的MTR,以配置最合理的参数和策略在软件层提供服务,例如:
- 磁盘:年故障率在千分之四,3-Copy是否能在一个5000台规模,保证同时坏盘的概率效率一定的数量级,数据拷贝策略应该在多少时间内完成数据恢复。当过保之后,故障率是否会上升
- 机器:未过保机器故障率在万分之这个量级,如何通过调度将业务放在多个AZ
- AZ:因为有多条线路和电源,AZ不可服务概率更小,但可能会发生某些网络链路,或者机架的不可用
除此之外,我们还要考虑用户的影响,例如热门的活动,大流量的脉冲(例如双十一等)的行为是怎么样的。任何可能影响系统稳定性的内部和外部因素,都要考虑到chaos实验中。
3. Run Experiments in Production
从刚才两点可以看到,系统会根据环境、以及用户流量模式引起变化。我们也没办法去提前预测,规模,因此最好的方法还是从线上引流进行实验。在Netflix,Chaos试验是直接在生产环境上做的。
4. Automate Experiments to Run Continuously
有了数据、实验、环境,接下来就是执行。作者认为手动的故障演练是不可持续的,因此,netflix将这些作为常态,通过自动化手段来驱动、分析实验结果。
关于Chaos Engineering,netflix发起了一个网站和Google Group讨论:
- Chaos Engineering:http://principlesofchaos.org/
- Google Group:https://groups.google.com/forum/#!forum/chaos-community
Intuition(来自什么,understand the operating and system)
现实中的问题:过多的监控项,太多并且无异议。Netflix根据SRE需求,搞了一套可视化框架:Vizceral,visual framework. to understand the complicated microservice,以下是一些截图:
Global Traffic
在Chaos Kang(Kingkang)中提到,Netflix可以容忍Region级dang当机不影响所有的用户,并且能快速恢复,将Region级流量进行负载均衡。
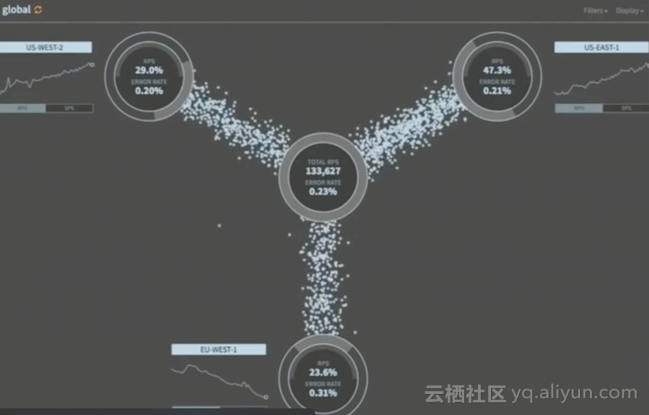
Region内Traffic
通过流量图,显示Microservice之间的流量,以及如何相互影响。
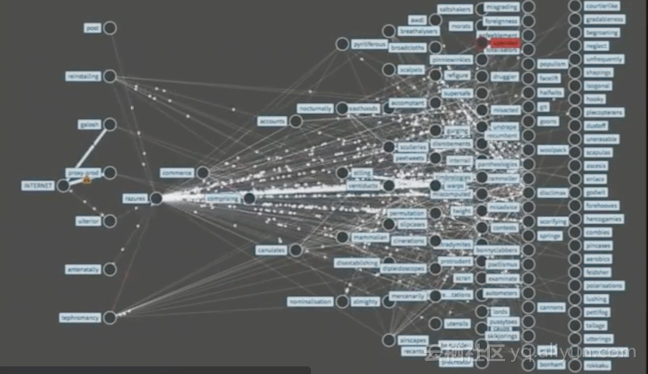
Vizeral已开源,可以参考 http://netflix.github.io/
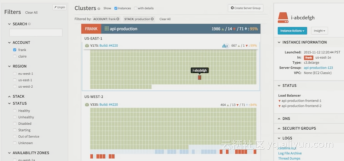
Deployment
Spinner:enable veolicty
传统的做法是很多自动化工具连接而成,非常细小琐碎。Spinner是Netflix统一部署系统。
Cluster Management视图:Resize,Clone,ELB Managment
Deck视图:发布、测试、版本管理
Poly(Lots of things)
Lots of language
netflix认为hire people to solve problem (by their own way),而不是限制他们去按部就班开发,所以所有的开发语言都欢迎。

Lots of system

Enable choice & option
因为历史原因,架构一直在演化:从一开始IDC到EC2、到Container。通过Titian + Spinnaker将Container + EC2 很好融合起来,并非直接一次迁移到Microservice。
last not least
- Partnership:Use more Amazon Service
- Enable Focus: use aws
- Culture
- Values
- Context not control
比较务虚,自行理解吧