
本文简述了软件复杂度问题及应对策略:抽象和组合;展示了抽象和组合在函数式编程中的应用;并展示了Redux/React在解决前端状态管理的复杂度方面对上述理论的实践。这其中包括了一段有趣的Redux推导。
软件复杂度及其应对策略
软件复杂度
软件的首要技术使命是管理复杂度。——代码大全
在软件开发过程中,随着需求的变化和系统规模的增大,我们的项目不可避免地会趋于复杂。如何对软件复杂度及其增长速率进行有效控制,便成为一个日益突出的问题。下面介绍两种控制复杂度的有效策略。
对应策略
抽象
世界的复杂、多变和人脑处理问题能力的有限性,要求我们在认识世界时对其做简化,提取出一般化和共性的概念,形成理论和模型,然后反过来指导我们改造世界。而一般化的过程即抽象的过程,抽象思维使我们忽略不同事物的细节差异,抓住它们的本质,并提出解决本质问题的普适策略。
例如,范畴论将世界抽象为对象和对象之间的联系,Linux 将所有I/O接口都抽象为文件,Redux将所有事件抽象为action。
组合
组合是另一种处理复杂事物的有效策略。通过简单概念的组合可以构造出复杂的概念;通过将复杂任务拆分为多个低耦合度的简单的子任务,我们可以对各子任务分而治之;各子任务解决后,将它们重新组合起来,整个任务便得以解决。
软件开发的过程,本质上也是人们认识和改造世界的一种活动,所以也可以借助抽象和组合来处理复杂的任务。
抽象与组合在函数式编程中的应用
函数式编程是相对于命令式编程而言的。命令式编程依赖数据的变化来管理状态变化,而函数式编程为克服数据变化带来的状态管理的复杂性,限制数据为不可变的,其选择使用流式操作来进行状态管理。而流式操作以函数为基本的操作单元,通过对函数的抽象和组合来完成整个任务。下面对抽象和组合在函数式编程中的应用进行详细的讲解。
高阶函数的抽象
一种功能强大的语言,需要能为公共的模式命名,建立抽象,然后直接在抽象的层次上工作。
如果函数只能以数值或对象为参数,将会严重限制人们建立抽象的能力。经常会有一些同样的设计模式能用于若干不同的过程。为了将这种模式描述为相应的概念,就需要构造出这样的函数,使其以函数作为参数,或者将函数作为返回值。这类能操作函数的函数称为高阶函数。
在进行序列操作时,我们抽象出了三类基本操作:map、filter 和 reduce 。可以通过向这三个抽象出来的高阶函数注入具体的函数,生成处理具体问题的函数;进一步,通过组合这些生成的具体的函数,几乎可以解决所有序列相关的问题。以 map 为例,其定义了一大类相似序列的操作:对序列中每个元素进行转换。至于如何转换,需要向 map 传入一个具体的转换函数进行具体化。这些抽象出来的高阶函数相当于具有某类功能的通用型机器,而传入的具体函数相当于特殊零件,通用机器配上具体零件就可以应用于属于该大类下的各种具体场景了。
map 的重要性不仅体现在它代表了一种公共的模式,还体现在它建立了一种处理序列的高层抽象。迭代操作将人们的注意力吸引到对于序列中逐个元素的处理上,引入 map 抑制了对这种细节层面上的关注,强调的是从源序列到目标序列的变换。这两种定义形式之间的差异,并不在于计算机会执行不同的计算过程,而在于我们对同一种操作的不同思考方式。从作用上看,map 帮我们建立了一层抽象屏障,将序列转换的函数实现,与如何提取序列中元素以及组合结果的细节隔离开。这种抽象也提供了新的灵活性,使我们有可能在保持从序列到序列的变换操作框架的同时,改变序列实现的底层细节。
例如,我们有一个序列:
- const list = [9, 5, 2, 7]
若对序列中的每个元素加 1:
- map(a => a + 1, list) //=> [10, 6, 3, 8]
若对序列中的每个元素平方:
- map(a => a * a, list) //=> [81, 25, 4, 49]
我们只需向 map 传入具体的转换函数,map 便会自动将函数映射到序列的的每个元素。
高阶函数的组合
高阶函数使我们可以显式地使用程序设计元素描述过程(函数)的抽象,并能像操作其它元素一样去操作它们。这让我们可以对函数进行组合,将多个简单子函数组合成一个处理复杂任务的函数。下面对高阶函数的组合进行举例说明。
现有一份某公司雇员某月的考核表,我们想统计所有到店餐饮部开发人员该月完成的任务总数,假设员工七月绩效结构如下:
- [{
- name: 'Pony',
- level: 'p2.1',
- segment: '到餐'
- tasks: 16,
- month: '201707',
- type: 'RD',
- ...
- }, {
- name: 'Jack',
- level: 'p2.2',
- segment: '外卖'
- tasks: 29,
- month: '201707',
- type: 'QA',
- ...
- }
- ...
- ]
我们可以这样做:
- const totalTaskCount = compose(
- reduce(sum, 0), // 4. 计算所有 RD 任务总和
- map(person => person.tasks), // 3. 提取每个 RD 的任务数
- filter(person => person.type === 'RD'), // 2. 筛选出到餐部门中的RD
- filter(person => person.segment === '到餐') // 1. 筛选出到餐部门的员工
- )
上述代码中,compose 是用来做函数组合的,上一个函数的输出作为下一个函数的输入。类似于流水线及组成流水线的工作台。每个被组合的函数相当于流水线上的工作台,每个工作台对传过来的工件进行加工、筛选等操作,然后输出给下一个工作台进行处理。
compose 调用顺序为从右向左(自下而上),Ramda 提供了另一个与之对应的API:pipe,其调用顺序为从左向右。compose意为组合,pipe意为管道、流,其实流是一种纵向的函数组合。
计算到餐RD完成任务总数示意图如下所示:
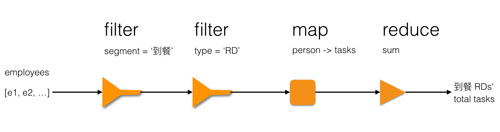
通过上节map示例和本节的计算到餐RD完成任务总数的示例,我们可以看到利用高阶函数进行抽象和组合的强大和简洁之处。这种通用模式(模块)+ "具体函数"组合的模式,显示了通用模块的普适性和处理具体问题时的灵活性。
上面讲了很多高阶函数的优势和实践,然而一门语言如何才能支持高阶函数呢?
通常,程序设计语言总会对基本元素的可能使用方式进行限制。带有最少限制的元素被称为一等公民,包括的 "权利或者特权" 如下所示:
- 可以使用变量命名;
- 可以提供给函数作为参数;
- 可以由函数作为结果返回;
- 可以包含在数据结构中;
幸运的是在JavaScript中,函数被看作是一等公民,也即我们可以在JavaScript中像使用普通对象一样使用高阶函数进行编程。
流式操作
由上述过程我们得到了一种新的模式——数据流。信号处理工程师可以很自然地用流过一些级联的处理模块信号的方式来描述这一过程。例如我们输入公司全员月度考核信息作为信号,首先会流过两个过滤器,将所有不符合要求的数据过滤掉,这样得到的信号又通过一个映射,这是一个 "转换装置",它将完整的员工对象转换为对应的任务信息。这一映射的输出被馈入一个累加器,该装置用 sum 将所有的元素组合起来,以初始的0开始。
要组织好这些过程,最关键的是将注意力集中在处理过程中从一个步骤流向下一个步骤的"信号"。如果我们用序列来表示这些信号,就可以利用序列操作实现每步处理。
或许因为序列操作模式非常具有一般化的性质,于是人们发明了一门专门处理序列的语言Lisp(LISt Processor)……
将程序表示为针对序列的操作,这样做的价值就在于能帮助我们得到模块化的程序设计,也就是说,得到由一些比较独立的片段的组合构成的设计。通过提供一个标准部件的库,并使这些部件都有着一些能以各种灵活方式相互连接的约定接口,将能进一步推动人们去做模块化的设计。
用流式操作进行状态管理
在前面,我们已经看到了组合和抽象在克服大型系统复杂性方面所起的作用。但还需要一些能够在整体架构层面帮助我们构造起模块化的大型系统的策略。
目前有两种比较流行的组织策略:面向对象和流式操作。
面向对象组织策略将注意力集中在对象上,将一个大型系统看成一大批对象,它们的状态和行为可能随着时间的进展而不断变化。流式操作组织策略将注意力集中在流过系统的信息流上,很像电子工程师观察一个信号处理系统。
在利用面向对象模式模拟真实世界中的现象时,我们用具有局部状态的计算对象去模拟真实世界里具有局部状态的对象;用计算机里面随着时间的变化去表示真实世界里随着时间的变化;在计算机里,被模拟对象随着时间的变化是通过对那些模拟对象中局部变量的赋值实现的。
我们必须让相应的模型随着时间变化,以便去模拟真实世界中的现象吗?答案是否定的。如果以数学函数的方式考虑这些问题,我们可以将一个量 x 随时间而变化的行为,描述为一个时间的函数 x(t)。如果我们集中关注的是一个个时刻的 x,可以将它看做一个变化着的量。如果关注的是这些值的整个时间史,那么就不需要强调其中的变化——这一函数本身并没有变化。
如果用离散的步长去度量时间,就可以用一个(可能无穷的)序列来模拟变化,以这种序列表示被模拟系统随着时间变化的历史。为此,我们需要引进一种称为流的新数据结构。从抽象的角度看,一个流也是一个序列(无穷序列)。
流处理使我们可以模拟一些包含状态的系统,但却不需要赋值或者变动数据,能避免由于引进了赋值而带来的内在缺陷。
例如在前端开发中,一般会用对象模型(DOM)来模拟和直接操控网页,随着与用户不断交互,网页的局部状态不断被修改,其中的行为也会随时间不断变化。随着时间的累积,我们页面状态管理变得愈加复杂,以致于最终我们可能自己也不知道网页当前的状态和行为。
为了克服对象模型随时间变化带来的状态管理困境,我们引入了 Redux,也就是上面提到的流处理模式,将页面状态 state 看作时间的函数 state = state(t) -> state = stateF(t),因为状态的变化是离散的,所以我们也可以写成 stateF(n) 。通过提取 state 并显式地增加时间维度,我们将网页的对象模型转变为流处理模型,用 [state] 序列表示网页随着时间变化的状态。
由于 state 可以看做整个时间轴上的无穷(具有延时)序列,并且我们在之前已经构造起了对序列进行操作的功能强大的抽象机制,所以可以利用这些序列操作函数处理 state ,这里我们用到的是 reduce 。
函数式编程在Redux/React中的应用
从reduce到Redux
reduce
reduce 是对列表的迭代操作的抽象,map 和 filter 都可以基于 reduce 进行实现。Redux借鉴了reduce 的思想,是 reduce 在时间流处理上的一种特殊应用。接下来我们展示Redux是怎样由 reduce 一步步推导出来的。
首先看一下 reduce 的类型签名:
- reduce :: ((a, b) -> a) -> a -> [b] -> a
- reduce :: (reducer, initialValue, list) -> result
- reducer :: (a, b) -> a
- initialValue :: a
- list :: [b]
- result :: a
上述类型签名采用的是Hindley-Milner 类型系统,接触过Haskell的的同学对此会比较熟悉。其中 :: 左侧部分为函数或参数名称,右侧为该函数或参数的类型。
reduce 接受三个参数:累积器 reducer ,累积初始值 initialValue,待累积列表 list 。我们迭代遍历列表的元素,利用累积器reducer 对累积值和列表当前元素进行累积操作,reducer 输出新累积值作为下次累积操作的输入。依次循环迭代,直到遍历结束,将此时的累积值作为 reduce 最终累积结果输出。
reduce 在某些编程语言中也被称为 foldl。中文翻译有时也被称为折叠、归约等。如果将列表看做是一把展开的扇子,列表中的每个元素看做每根扇骨,则 reduce 的过程也即扇子从左到右不断折叠(归约、累积)的过程。当扇子完全合上,一次折叠也即完成。当然,折叠顺序也可以从右向左进行,即为 reduceRight 或foldr。
reduce 代码实现如下:
- const reduce = (reducer, initialValue, list) => {
- let acc = initialValue;
- let val;
- for(let i = 0; i < list.length; i++) {
- val = list[i];
- acc = reducer(acc, val);
- }
- return acc;
- };
例如,我们想对一个数字列表 [2, 3, 4] 进行累加操作(初始值为 1 ),可以表示为:
reduce((a, b) => a + b, 1, [2, 3, 4])
示意图如下所示:
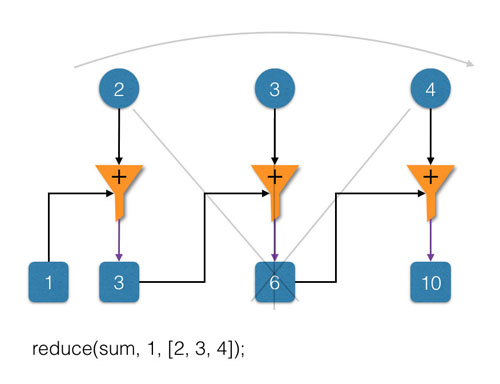
介绍完 reduce 的基本概念,接下来展示如何由 reduce 一步步推导出 Redux,以及 Redux 各部分与reduce 的对应关系。
Redux
首先定义 Redux 的类型签名:
- redux :: ((state, action) -> state) -> initialState -> [action] -> state
- redux :: (reducer, initialState, stream) -> result
- reducer :: (state, action) -> state
- initialState :: state
- list :: [action]
- result :: state
将 reduce 参数的名称变换一下,便得到Redux的类型签名。从类型签名看,Redux参数包含 reducer 函数,state初始值 initialState ,和一个以 action 为元素的时间流列表 stream :: [action];返回值为最终的状态 state。
Redux初步实现
下面看一下Redux的初步实现:
- const redux = (reducer, initialState, stream) => {
- let state = initialState;
- let action;
- for(let i = 0; i < stream.length; i++) {
- action = stream[i];
- state = reducer(state, action);
- }
- return state;
- }
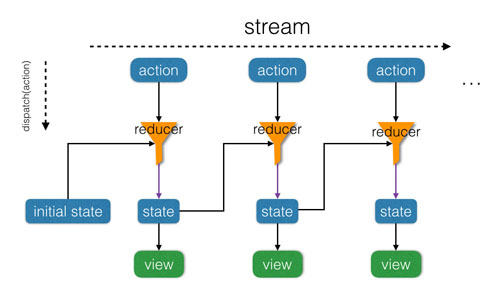
首先设置Redux state 的初始值 initialState,stream 代表基于时间的事件流列表,action = stream[i] 代表事件流上某个时间点发生的一次 action。每次 for 循环,我们将当前的状态 state 和action 传给 reducer 函数,根据本次 action 对当前 state 进行更新,产生新的 state。新的state 作为下次 action 发生时的 state 参与状态更新。
Redux基本原理其实已经讲完了,Redux的各个概念如:reducer 函数、state、 stream :: [action] 也是和 reduce 一一对应的。不同之处在于,redux 中的列表 stream,是一个随时间不断生成的无限长的action 动作列表,而 reduce 中的列表是一个普通的 list。
等一下,上述Redux实现貌似缺了些什么……
是的,在Redux中,状态的改变和获取是通过两个函数来操作的:dispatch、getState,接下来我们将这两个函数添加进去。
Redux优化实现
- const redux = (reducer, initialState, stream) => {
- let currentState = initialState;
- let action;
- const dispatch = action => {
- currentState = reducer(currentState, action);
- };
- const getState = () => currentState;
- for(i = 0; i < stream.length; i++) {
- action = stream[i];
- dispatch(action);
- }
- return state; // the end of the world :)
- }
这样我们就可以通过 dispatch(action) 来更新当前的状态,通过 getState 也可以拿到当前的状态。
但是还是感觉不太对?
在上述实现中,stream 并不是现实中的事件流,只是普通的列表而已,dispatch 和 getState 接口也并没有暴露给外部,同时在Redux最后还有一个 return state ,既然说过 stream 是一个无限长的列表,那return state 貌似没有什么意义。
好吧,上述两次Redux代码实现,其实都是对Redux原理的说明,下面我们来真正实现一个现实中可运行的最小Redux代码片段。
Redux可用的最小实现
- const redux = (reducer, initialState) => {
- let currentState = initialState;
- const dispatch = action => {
- currentState = reducer(currentState, action);
- };
- const getState = () => currentState;
- return ({
- dispatch,
- getState,
- });
- };
- const store = redux(reducer, initialState);
- const action = { type, payload };
- store.dispatch(action);
- store.getState();
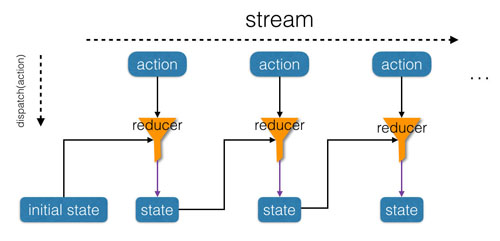
Yes! 我们将 stream 从Redux函数中抽离出来,或者说是从电脑屏幕上抽取到现实世界中了。
我们首先使用 reducer 和 initialState 初始化 redux 为 store;然后现实中每次事件发生时,我们通过store.dispatch(action) 更新store中状态;同时通过 store.getState() 来获取 store 的当前状态。
等等,这怎么听着像是面向对象的编程方式,对象中包含私有变量:currentState 和操作私有变量的方法:dispatch 和 getState,伪代码如下所示:
- const store = {
- private currentState: initialState,
- public dispatch: (action) => { currentState = reducer(currentState, action)},
- public getState: () => currentState,
- }
是的,从这个角度讲,我们确实是用了函数式的过程实现了一个面向对象的概念。
如果你再仔细看的话,我们用闭包(编程领域的闭包,与集合意义上的闭包不同)实现的这个对象,虽然最后的Redux实现返回的是形式为 { dispatch, getState } store 对象,但 dispatch 和 getState 捕获了Redux内部创建的 currentState,因此形成了闭包。
Redux的运作过程如下所示:
Redux 和 reduce 的联系与区别
我们来总结一下 Redux 和 reduce 的联系与区别。
相同点:
- reduce和Redux都是对数据流进行fold(折叠、归约);
- 两者都包含一个累积器(reducer)((a, b) -> a VS (state, action) -> state )和初始值(initialValue VS initialState ),两者都接受一个抽象意义上的列表(list VS stream )。
不同点:
- reduce:接收一个有限长度的普通列表作为参数,对列表中的元素从前往后依次累积,并输出最终的累积结果。
- Redux:由于基于时间的事件流是一个无限长的抽象列表,我们无法显式地将事件流作为参数传给Redux,也无法返回最终的累积结果(事件流无限长)。所以我们将事件流抽离出来,通过 dispatch 主动地向 reducer 累积器 push action,通过getState 观察当前的累积值(中间的累积过程)。
- 从冷、热信号的角度看,reduce 的输入相当于冷信号,累积器需要主动拉取(pull)输入列表中的元素进行累积;而Redux的输入(事件流)相当于热信号,需要外部主动调用 dispatch(action) 将当前元素push给累积器。
由上可知,Redux将所有的事件都抽象为 action,无论是用户点击、Ajax请求还是页面刷新,只要有新的事件发生,我们就会 dispatch 一个 action 给 reducer,并结合上一次的状态计算出本次状态。抽象出来的统一的事件接口,简化了处理事件的复杂度。
Redux还规范了事件流——单向事件流,事件 action 只能由 dispatch 函数派发,并且只能通过 reducer更新系统(网页)的状态 state,然后等待下一次事件。这种单向事件流机制能够进一步简化事件管理的复杂度,并且有较好的扩展性,可以在事件流动过程中插入 middleware,比如日志记录、thunk、异步处理等,进而大大增强事件处理的灵活性。
Redux 的增强:Transduce与Redux Middleware
transduce 作为增强版的 reduce,是在 Clojure 中首次引入的。transduce 相当于 compose 和 reduce的组合,相对于 reduce 改进之处为:列表中的每个元素在放入累积器之前,先对其进行一系列的处理。这样做的好处是能同时降低代码的时间复杂度和空间复杂度。
假设有一个长度为n的列表,传统列表处理的做法是先用 compose 组合一系列列表处理函数对列表进行转换处理,最后对处理好的列表进行归约(reduce)。假设我们组合了 m 个列表处理函数,加上最后一次reduce,时间复杂度为 n * (m + 1);而使用 transduce 只需要一次循环,所以时间复杂度为 n 。由于compose 的每个处理函数都会产生中间结果,且这些中间结果有时会占用很大的内存,而 transduce 边转换边累积,没有中间结果产生,所以空间复杂度也得到了有效的控制。

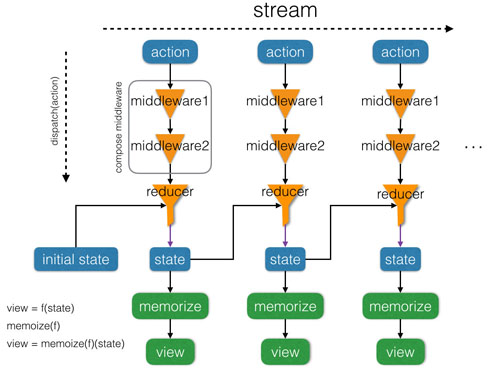
我们也可以对Redux进行类似地增强优化,每次 dispatch(action) 时,我们先根据 action 进行一系列操作,最后传给 reducer 函数进行真正的状态更新。这就是上文提到的Redux middleware。Redux是一个功能和扩展性非常强的状态管理库,而围绕Redux产生的一系列优秀的middlewares让Redux/React 形成了一个强大的前端生态系统。个人认为Redux/React自身良好的架构、先进的理念,加上一系列优秀的第三方插件的支持,是React/Redux成功的关键所在。
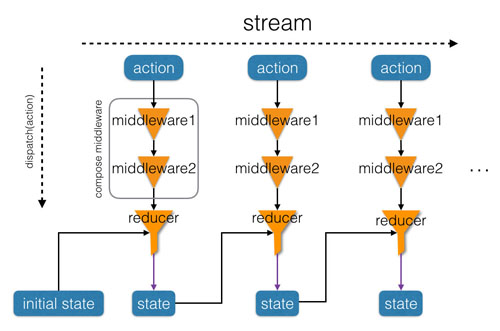
纯函数在React中的应用
Redux可以用作React的数据管理(数据源),React接受Redux输出的state,然后将其转换为浏览器中的具体页面展示出来:
view = React(state)
由上可知,我们可以将React看作输入为state,输出为view的“纯”函数。下面讲解纯函数的概念、优点,及其在React中的应用。
纯函数的定义:相同的输入,永远会得到相同的输出,并且没有副作用。
纯函数的运算既不受外部环境和内部不确定性因素的影响,也不会影响外部环境。输出只与输入有关。
由此可得纯函数的一些优点:可缓存、引用透明、可等式推导、可预测、单测友好、易于并发操作等。
其实函数式编程中的纯函数指的是数学意义上的函数,数学中函数定义为:
函数是不同数值之间的特殊关系:每一个输入值返回且只返回一个输出值。
从集合的角度讲,函数分为三部分:定义域和值域,以及定义域到值域的映射。函数调用(运算)的过程即定义域到值域映射的过程。
如果忽略中间的计算过程,从对象的角度看,函数可以看做是键值对映射,输入参数为键,输出参数为键对应的值。如果一段代码可以替换为其执行结果,而且是在不改变整个程序行为的前提下替换的,我们就说这段代码是引用透明的。
由于纯函数相同的输入总是返回相同的输出,我们认为纯函数是引用透明的。
纯函数的缓存便是引用透明的一个典型应用,我们将被调用过的参数及其输出结果作为键值对缓存起来,当下次调用该函数时,先查看该参数是否被缓存过,如果是,则直接取出缓存中该键对应的值作为调用结果返回。
缓存技术在做耗时较长的函数调用时比较有用,比如GPU在做大型3D游戏画面渲染时,会对计算时间较长的渲染做缓存,从而增强画面的流畅度。网页中的DOM操作也是非常耗时的,而React组件本身也是纯函数,所以React对 state 可以进行缓存,如果state没有变化,就还用之前的网页,页面不需要重新渲染。
带有缓存的最终 React-Redux 框架如下所示:
总结
我们从产生软件复杂度的原因出发,从方法层面上讲了控制代码复杂度的两种基本方式:抽象和组合,利用处理列表的高阶函数(map、filter、reduce、compose)对抽象和组合进行了举例解释。
然后从整体架构层面上讲了应对复杂度的策略:面向对象和流式处理,分析了两者的基本理念,以及流式处理在状态管理方面的优势,引申出基于时间的抽象事件流。
然后我们展示了如何从列表处理方法 reduce 推导出可用的事件流处理框架Redux,并将 reduce 的加强版transduce 与Redux的 middleware 做了类比。
最后讲了纯函数在 react/redux 框架中的应用:将页面渲染抽象为纯函数,利用纯函数进行缓存等。
贯穿文章始终的是抽象、组合、函数式编程以及流式处理。希望通过本文让大家对软件开发的一些基本理念及其应用有所了解。从 reduce 推导出Redux的过程非常有趣,感兴趣的同学可以多看一下。
原文发布时间为:2017-10-17
本文作者:增迪
本文来自合作伙伴“51CTO”,了解相关信息可以关注。