容器内日志收集方案示例
ELK(Elasticsearch+Logstash+Kibana)是流行的一体化日志方案,提供日志收集、处理、存储、搜索、展示等全方位功能。
基于docker部署ELK非常方便,有各种现成的image可用,比如http://elk-docker.readthedocs.org/
但因为容器的隔离性,收集容器内的日志很不方便。本文的方案可以让用户通过简单的配置实现这一功能。
原理
本方案借助docker的Volume功能。在host机器上开辟一个固定目录D;产生日志的容器将日志文件所在目录mount到D目录下的子目录中;收集日志的容器再把目录D mount到自己容器内。
这样日志收集容器就能访问到所有日志文件了。如下图所示:
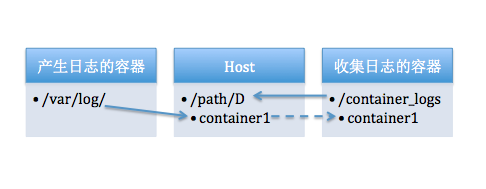
另外,为了收集容器的stdout、stderr日志,还需要将host的/var/lib/docker/目录mount到日志收集容器中,可以收集到json日志。
部署方法
可以通过下面这个容器编排文件实现一键部署。
#elk包含了Elasticsearch+Logstash+Kibana三个应用
elk:
image: registry.aliyuncs.com/testhub/elk:0.1
ports:
- '5601:5601'
- '9200:9200'
- '5000:5000'
restart: always
labels:
#aliyun.logs标示需要收集的目录,没有该标识的容器不会收集日志。多个目录之间用分号;分隔,目录与文件pattern之间用冒号:分隔,不带pattern则收集目录下所有文件。
#下面这行表示收集/var/log/elasticsearch目录下所有文件,/var/log/test/目录下所有.txt文件。
aliyun.logs: /var/log/elasticsearch;/var/log/test/:*.txt
#aliyun.logs里出现的每一个目录,都要有相应的volume。
#host目录必须是/container_logs/开头。
volumes:
- /container_logs/elasticsearch/:/var/log/elasticsearch/
- /container_logs/elktest/:/var/log/test/
logstash-forwarder:
image: registry.aliyuncs.com/testhub/logstash-forwarder:0.2
restart: always
links:
- elk:logstash
labels:
#aliyun.global: true是阿里云扩展的功能,有该标识的容器每个host上有且仅有一个
aliyun.global: 'true'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /container_logs/:/container_logs/
- /var/lib/docker/:/var/lib/docker/
部署教程
在这之前,需要先创建一个集群。可以在容器服务控制台http://cs.console.aliyun.com/ 完成。
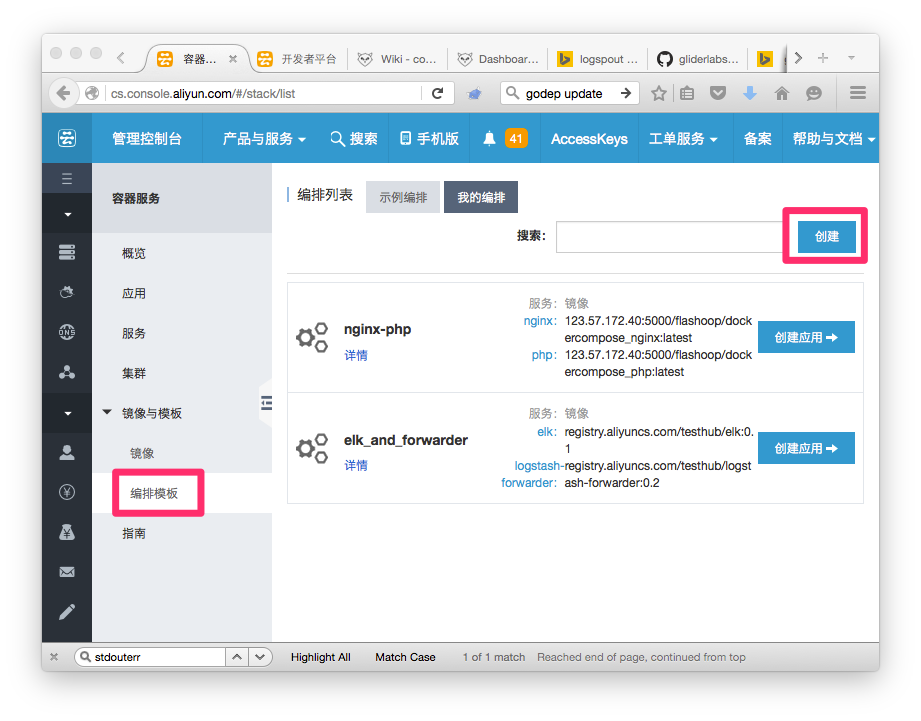
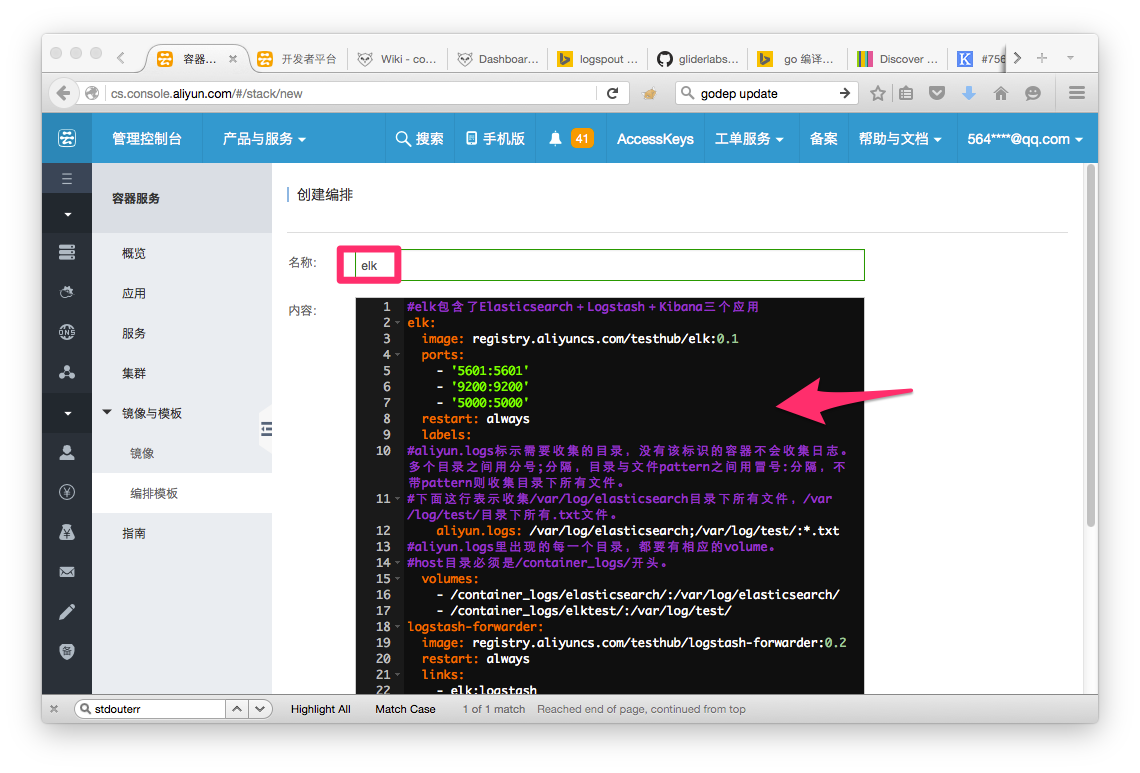
1. 创建编排文件
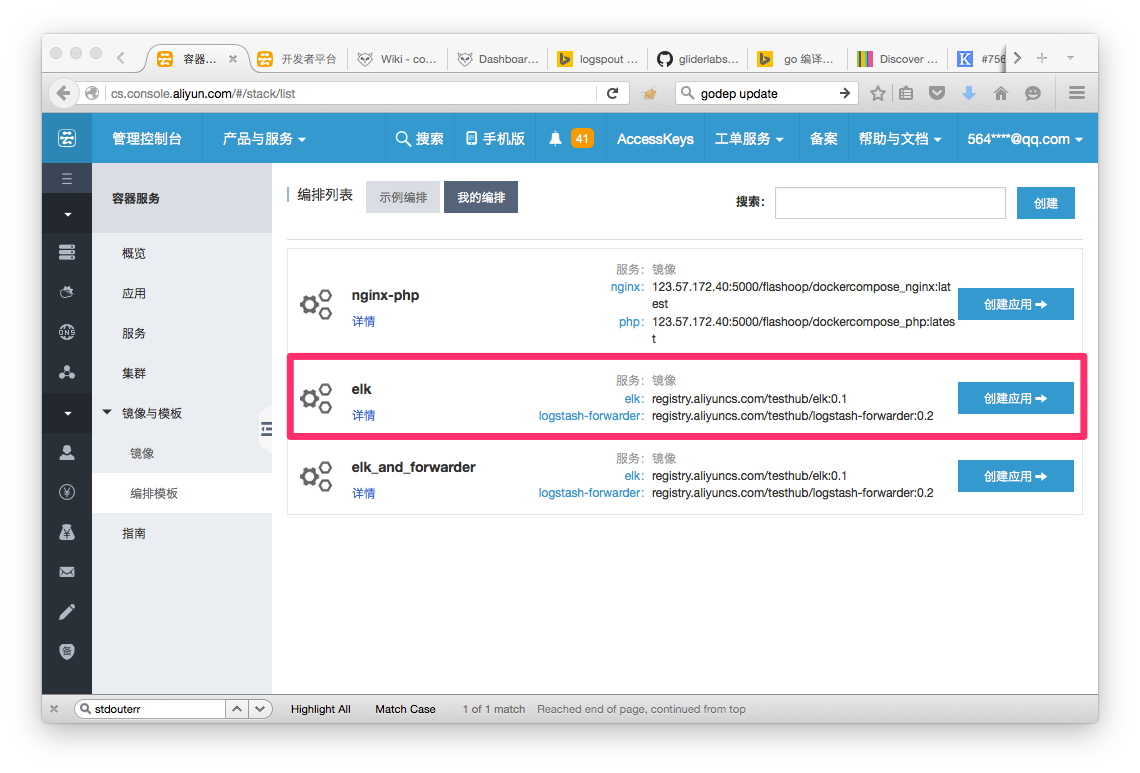
2. 用编排文件创建应用
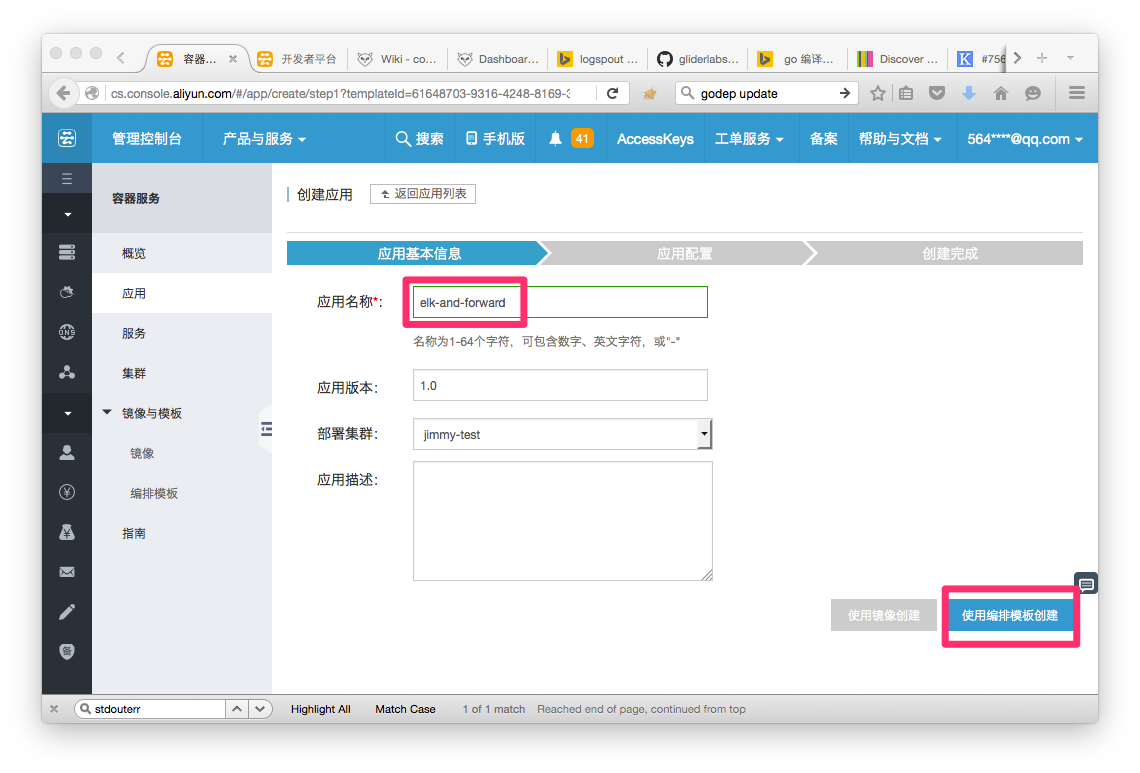
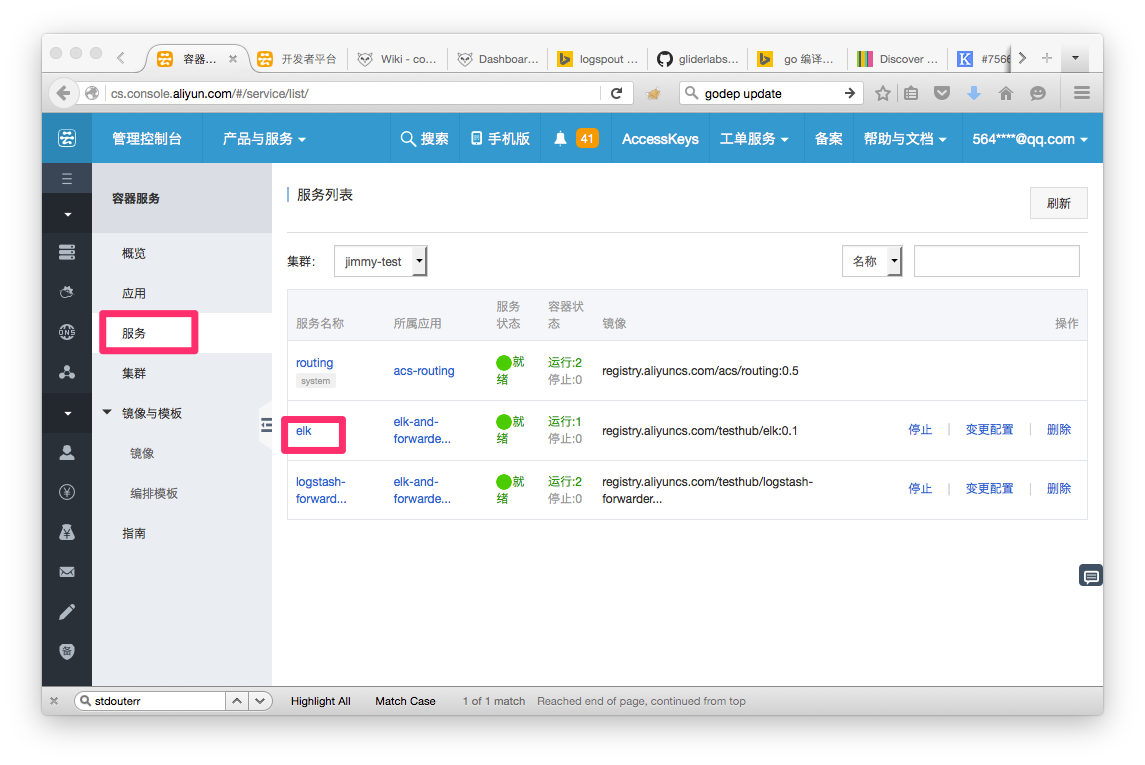
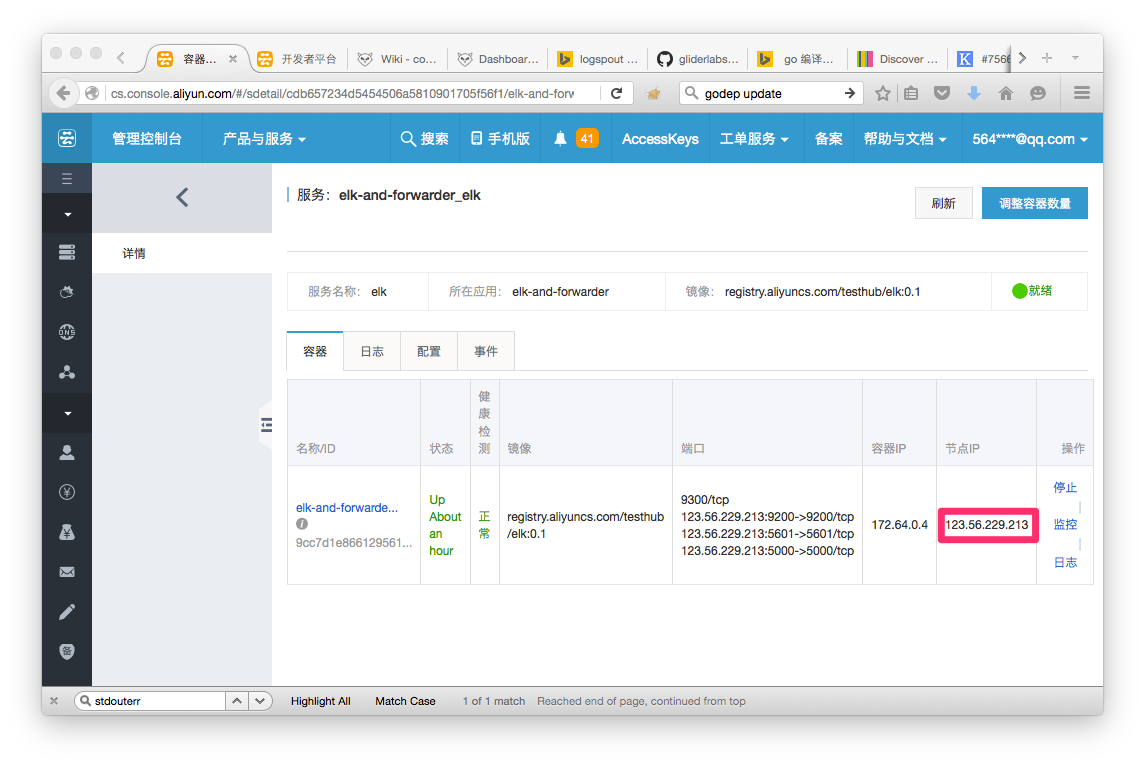
3. 查看状态,找到elk服务的节点IP
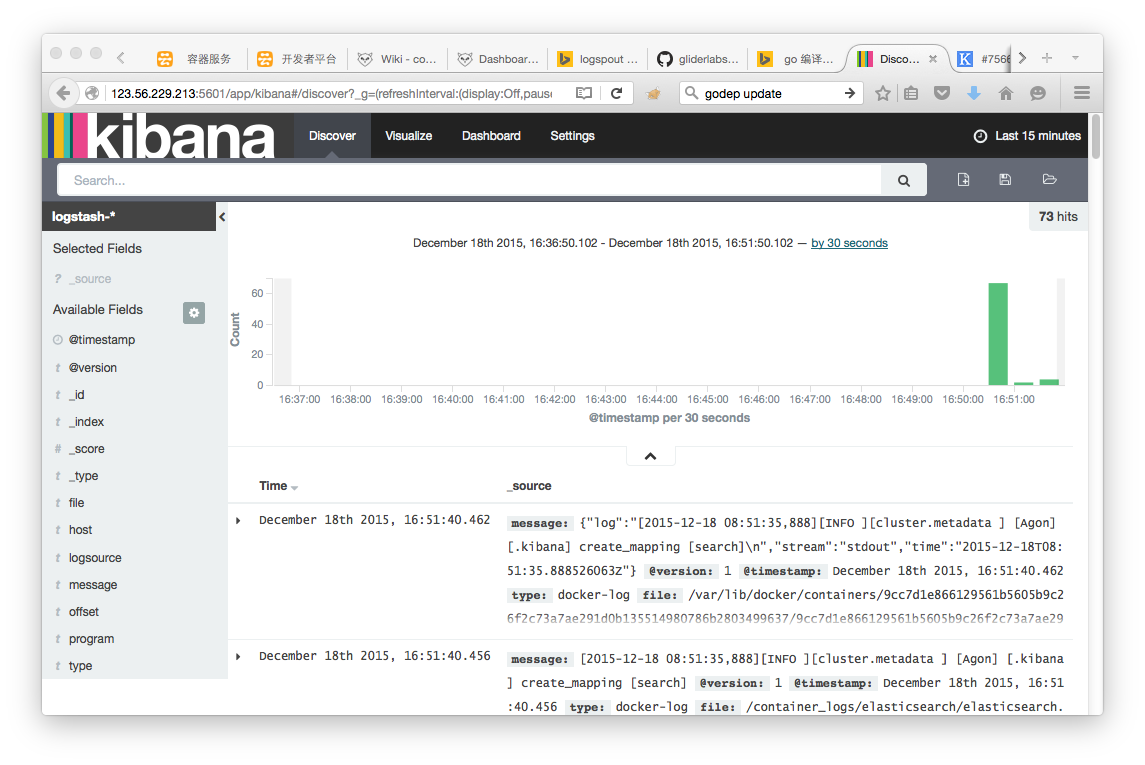
4. 访问http://节点IP:5601/,开始搜索日志
时间: 2024-11-08 20:18:19