推荐:28款GitHub最流行的开源机器学习项目(一):TensorFlow排榜首
15. XGBoost
XGBoot是设计为高效、灵活、可移植的优化分布式梯度 Boosting库。它实现了 Gradient Boosting 框架下的机器学习算法。XGBoost通过提供并行树Boosting(也被称为GBDT、GBM),以一种快速且准确的方式解决了许多数据科学问题。相同的代码可以运行在大型分布式环境如Hadoop、SGE、MP上。它类似于梯度上升框架,但是更加高效。它兼具线性模型求解器和树学习算法。
XGBoot至少比现有的梯度上升实现有至少10倍的提升,同时还提供了多种目标函数,包括回归、分类和排序。由于它在预测性能上的强大,XGBoot成为很多比赛的理想选择,其还具有做交叉验证和发现关键变量的额外功能。
值得注意的是:XGBoost仅适用于数值型向量,因此在使用时需要将所有其他形式的数据转换为数值型向量;在优化模型时,这个算法还有非常多的参数需要调整。
开发语言:C++
开源许可:Apache-2.0 license
GitHub项目地址:https://github.com/dmlc/xgboost
16. GoLearn
GoLearn 是Go 语言中“功能齐全”的机器学习库,简单性及自定义性是其开发目标。
在安装 GoLearn 时,数据作为实例被加载,然后可以在其上操作矩阵,并将操作值传递给估计值。GoLearn 实现了Fit/Predict的Scikit-Learn界面,因此用户可轻松地通过反复试验置换出估计值。此外,GoLearn还包括用于数据的辅助功能,例如交叉验证、训练以及爆裂测试。
开发语言:Go
GitHub项目地址: https://github.com/sjwhitworth/golearn
17. ML_for_Hackers
ML_for_Hackers 是针对黑客机器学习的代码库,该库包含了所有针对黑客的机器学习的代码示例(2012)。该代码可能和文中出现的并不完全相同,因为自出版以来,可能又添加了附加的注释和修改部分。
所有代码均为R语言,依靠众多的R程序包,涉及主题包括分类(Classification)、排行(Ranking)、以及回归(Regression)的所有常见的任务和主成分分析(PCA)和多维尺度(Multi-dimenstional Scaling)等统计方法。
开发语言:R
开源许可:Simplified BSD License
GitHub项目地址: https://github.com/johnmyleswhite/ML_for_Hackers
18. H2O-2
H2O使得Hadoop能够做数学运算!它可以通过大数据衡量统计数据、机器学习和数学。H2O是可扩展的,用户可以在核心区域使用简单的数学模型构建模块。H2O保留着与R、Excel 和JSON等相类似的熟悉的界面,使得大数据爱好者及专家们可通过使用一系列由简单到高级的算法来对数据集进行探索、变换、建模及评分。采集数据很简单,但判决难度却很大,而H2O却通过更快捷、更优化的预测模型,能够更加简单迅速地从数据中获得深刻见解。
0xdata H2O的算法是面向业务流程——欺诈或趋势预测。Hadoop专家可以使用Java与H2O相互作用,但框架还提供了对Python、R以及Scala的捆绑。
开发语言:Java
GitHub项目地址: https://github.com/h2oai/h2o-2
19. neon
neon 是 Nervana 基于 Python 语言的深度学习框架,在诸多常见的深层神经网络中都能够获得较高的性能,比如AlexNet、VGG 或者GoogLeNet。在设计 neon 时,开发者充分考虑了如下功能:
- 支持常用的模型及实例,例如 Convnets、 MLPs、 RNNs、LSTMs、Autoencoders 等,其中许多预训练的实现都可以在模型库中发现;
- 与麦克斯韦GPU中fp16 和 fp32(基准) 的nervanagpu 内核紧密集成;
- 在Titan X(1 GPU ~ 32 hrs上可完整运行)的AlexNet上为3s/macrobatch(3072图像);
- 快速影像字幕模型(速度比基于 NeuralTalk 的CPU 快200倍)。
- 支持基本自动微分;
- 框架可视化;
- 可交换式硬盘后端:一次编写代码,然后配置到 CPU、GPU、或者 Nervana 硬盘。
在 Nervana中,neon被用来解决客户在多个域间存在的各种问题。
开发语言:Python
开源许可:Apache-2.0 license
GitHub项目地址: https://github.com/NervanaSystems/neon
20. Oryx 2
开源项目Oryx提供了简单且实时的大规模机器学习、预测分析的基础设施。它可实现一些常用于商业应用的算法类:协作式过滤/推荐、分类/回归、集群等。此外,Oryx 可利用 Apache Hadoop 在大规模数据流中建立模型,还可以通过HTTP REST API 为这些模型提供实时查询,同时随着新的数据不断流入,可以近似地自动更新模型。这种包括了计算层和服务层的双重设计,能够分别实现一个Lambda 架构。模型在PMML格式交换。
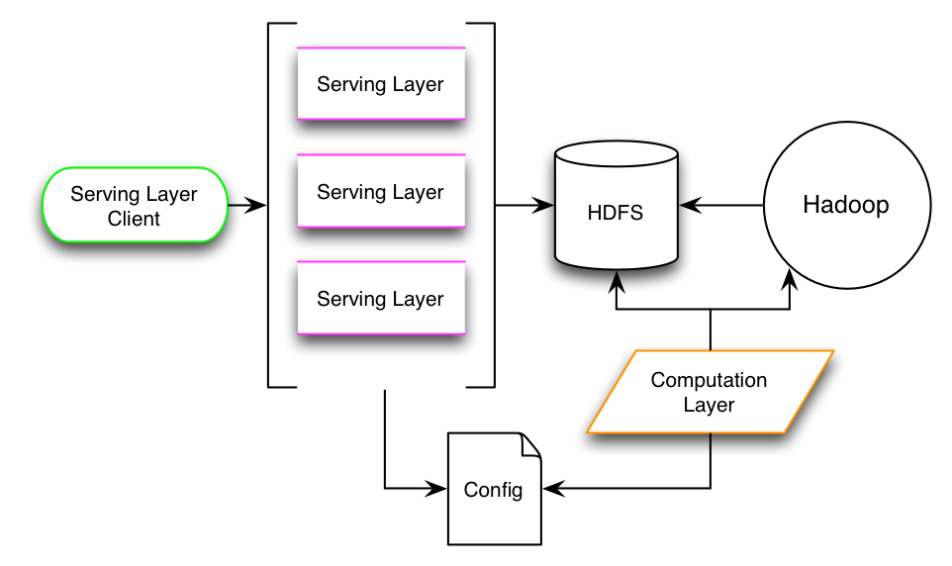
Oryx本质上只做两件事:建模和为模型服务,这就是计算层和服务层两个独立的部分各自的职责。计算层是离线、批量的过程,可从输入数据中建立机器学习模型,它的经营收益在于“代”,即可利用某一点处输入值的快照建模,结果就是随着连续输入的累加,随时间生成一系列输出;服务层也是一个基于Java长期运行的服务器进程,它公开了REST API。使用者可从浏览器中访问,也可利用任何能够发送HTTP请求的语言或工具进行访问。
Oryx的定位不是机器学习算法的程序库,Owen关注的重点有四个:回归、分类、集群和协作式过滤(也就是推荐)。其中推荐系统非常热门,Owen正在与几个Cloudera的客户合作,帮他们使用Oryx部署推荐系统。
开发语言:Java
GitHub项目地址: https://github.com/cloudera/oryx
21. Shogun
Shogun是一个机器学习工具箱,由Soeren Sonnenburg 和Gunnar Raetsch(创建,其重点是大尺度上的内核学习方法,特别是支持向量机(SVM,Support Vector Machines)的学习工具箱。它提供了一个通用的连接到几个不同的SVM实现方式中的SVM对象接口,目前发展最先进的LIBSVM和SVMlight 也位于其中,每个SVM都可以与各种内核相结合。工具箱不仅为常用的内核程序(如线性、多项式、高斯和S型核函数)提供了高效的实现途径,还自带了一些近期的字符串内核函数,例如局部性的改进、Fischer、TOP、Spectrum、加权度内核与移位,后来有效的LINADD优化内核函数也已经实现。
此外,Shogun还提供了使用自定义预计算内核工作的自由,其中一个重要特征就是可以通过多个子内核的加权线性组合来构造的组合核,每个子内核无需工作在同一个域中。通过使用多内核学习可知最优子内核的加权。
目前Shogun可以解决SVM 2类的分类和回归问题。此外Shogun也添加了了像线性判别分析(LDA)、线性规划(LPM)、(内核)感知等大量线性方法和一些用于训练隐马尔可夫模型的算法。
开发语言:C/C++、Python
许可协议:GPLv3
GitHub项目地址: https://github.com/shogun-toolbox/shogun
22. HLearn
HLearn是由Haskell语言编写的高性能机器学习库,目前它对任意维度空间有着最快最近邻的实现算法。
HLearn同样也是一个研究型项目。该项目的研究目标是为机器学习发掘“最佳可能”的接口。这就涉及到了两个相互冲突的要求:该库应该像由C/C++/Fortran/Assembly开发的底层库那样运行快速;同时也应该像由Python/R/Matlab开发的高级库那样灵活多变。Julia在这个方向上取得了惊人的进步,但是 HLearn“野心”更大。更值得注意的是,HLearn的目标是比低级语言速度更快,比高级语言更加灵活。
为了实现这一目标,HLearn采用了与标准学习库完全不同的接口。在HLearn中H代表着三个不同的概念,这三个概念也是HLearn设计的基本要求:
- H代表Haskell。机器学习是从数据中预测函数,所以功能性编程语言适应机器学习是完全说的通的。但功能性编程语言并没广泛应用于机器学习,这是因为它们固来缺乏支持学习算法的快速数值计算能力。HLearn通过采用Haskell中的SubHask库获得了快速数值计算能力;
- H同时代表着Homomorphisms。Homomorphisms是抽象代数的基本概念,HLearn将该代数结构用于学习系统中;
- H还代表着History monad。在开发新的学习算法过程中,最为困难的任务之一就是调试优化过程。在此之前,是没有办法减轻调试过程的工作量的,但History monad正在试图解决该问题。它可以让你在整个线程优化代码的过程中无需修改原代码。此外,使用该技术时没有增加其他的运行开销。
开发语言:Haskell
GitHub项目地址:https://github.com/mikeizbicki/HLearn
23. MLPNeuralNet
MLPNeuralNet是一个针对iOS和Mac OS系统的快速多层感知神经网络库,可通过已训练的神经网络预测新实例。它利用了向量运算和硬盘加速功能(如果可用),其建立在苹果公司的加速框架之上。
若你已经用Matlab(Python或R)设计了一个预测模型,并希望在iOS应用程序加以应用。在这种情况下,正好需要MLP NeuralNet,而MLP NeuralNet只能加载和运行前向传播方式的模型。MLP NeuralNet 有如下几个特点:
- 分类、多类分类以及回归输出;
- 向量化实现形式;
- 双精度;
- 多重隐含层数或空(此时相当于逻辑学/线性回归)。
开发语言:Objective-C
许可协议:BSD license
GitHub项目地址: https://github.com/nikolaypavlov/MLPNeuralNet
24. Apache Mahout
Mahout 是Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。Apache Mahout项目的目标是建立一个能够快速创建可扩展、高性能机器学习应用的环境。
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和 CF 方面。Mahout 的主要特性包括:
- Taste CF,Taste是Sean Owen在SourceForge上发起的一个针对CF的开源项目,并在2008年被赠予Mahout;
- 一些支持 Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift;
- Distributed Naive Bayes 和 Complementary Naive Bayes 分类实现;
- 针对进化编程的分布式适用性功能;
- Matrix 和矢量库。
使用 Mahout 还可实现内容分类。Mahout 目前支持两种根据贝氏统计来实现内容分类的方法:第一种方法是使用简单的支持 Map-Reduce 的 Naive Bayes 分类器;第二种方法是 Complementary Naive Bayes,它会尝试纠正Naive Bayes方法中的一些问题,同时仍然能够维持简单性和速度。
开发语言:Java
许可协议:Apache
GitHub项目地址: https://github.com/apache/mahout
25. Seldon Server
Seldon是一个开放式的预测平台,提供内容建议和一般的功能性预测。它在Kubernetes集群内运行,因此可以调配到Kubernetes范围内的任一地址:内部部署或云部署(例如,AWS、谷歌云平台、Azure)。另外,它还可以衡量大型企业安装的需求。
开发语言:Java
GitHub项目地址: https://github.com/SeldonIO/seldon-server
26. Datumbox - Framework
Datumbox机器学习框架是用Java编写的一个开源框架,该框架的涵盖大量的机器学习算法和统计方法,并能够处理大尺寸的数据集。
Datumbox API提供了海量的分类器和自然语言处理服务,能够被应用在很多领域的应用,包括了情感分析、话题分类、语言检测、主观分析、垃圾邮件检测、阅读评估、关键词和文本提取等等。目前,Datumbox所有的机器学习服务都能够通过API获取,该框架能够让用户迅速地开发自己的智能应用。目前,基于GPL3.0的Datumbox机器学习框架已经开源并且可以从GitHub上进行下载。
Datumbox的机器学习平台很大程度上已经能够取代普通的智能应用。它具有如下几个显著的优点:
- 强大并且开源。Datumbox API使用了强大的开源机器学习框架Datumbox,使用其高度精确的算法能够迅速地构建创新的应用;
- 易于使用。平台API十分易于使用,它使用了REST&JSON的技术,对于所有的分类器;
- 迅速使用。Datumbox去掉了那些很花时间的复杂机器学习训练模型。用户能够通过平台直接使用分类器。
Datumbox主要可以应用在四个方面:一个是社交媒体的监视,评估用户观点能够通过机器学习解决,Datumbox能够帮助用户构建自己的社交媒体监视工具;第二是搜索引擎优化,其中非常有效的方法就是文档中重要术语的定位和优化;第三点是质量评估,在在线通讯中,评估用户产生内容的质量对于去除垃圾邮件是非常重要的,Datumbox能够自动的评分并且审核这些内容;最后是文本分析,自然语言处理和文本分析工具推动了网上大量应用的产生,平台API能够很轻松地帮助用户进行这些分析。
开发语言:Java
许可协议:Apache License 2.0
GitHub项目地址: https://github.com/datumbox/datumbox-framework
27. Jubatus
Jubatus库是一个运行在分布式环境中的在线机器学习框架,即面向大数据数据流的开源框架。它和Storm有些类似,但能够提供更多的功能,主要功能如下:
- 在线机器学习库:包括分类、聚合和推荐;
- Fv_converter: 数据预处理(用自然语言);
- 在线机器学习框架,支持容错。
Jubatus认为未来的数据分析平台应该同时向三个方向展开:处理更大的数据,深层次的分析和实时处理。于是Jubatus将在线机器学习,分布式计算和随机算法等的优势结合在一起用于机器学习,并支持分类、回归、推荐等基本元素。根据其设计目的,Jubatus有如下的特点:
- 可扩展:支持可扩展的机器学习处理。在普通硬件集群上处理数据速度高达100000条/秒;
+实时计算:实时分析数据和更新模型; - 深层次的数据分析:支持各种分析计算:分类、回归、统计、推荐等。
如果有基于流数据的机器学习方面的需求,Jubatus值得关注。
开发语言:C/C++
许可协议:LGPL
GitHub项目地址: https://github.com/jubatus/jubatus
28. Decider
Decider 是另一个 Ruby 机器学习库,兼具灵活性和可扩展性。Decider内置了对纯文本和URI、填充词汇、停止词删除、字格等的支持,以上这些都可以很容易地在选项中组合。Decider 可支持Ruby中任何可用的存储机制。如果你喜欢,可以保存到数据库中,实现分布式分类。
Decider有几个基准,也兼作集成测试。这些都是定期运行并用于查明CPU和RAM的瓶颈。Decider可以进行大量数学运算,计算相当密集,所以对速度的要求比较高。这是经常使用Ruby1.9和JRuby测试其计算速度。此外,用户的数据集应该完全在内存中,否则将会遇到麻烦。
开发语言:Ruby
GitHub项目地址: https://github.com/danielsdeleo/Decider
以上为"28款GitHub最流行的开源机器学习项目"系列全部内容,更多精彩敬请期待。
编译自:https://github.com/showcases/machine-learning
译者:刘崇鑫 校对:王殿进