研究生期间分布式课程的小结吧。。。。
中间件在分布式系统中的地位和角色
为了使种类各异的计算机和网络都呈现为单个的系统,分布式系统常常通过一个“软件层”组织起来,该层在逻辑上位于由用户和应用程序组成的高层与由操作系统组成的低层之间,这样的分布式系统又称为中间件。中间件层延伸到了多台机器上,且为每个应用程序提供了相同的接口。它的重要的目的是提供一定程度的透明性,也就是一定程度上向应用程序隐藏数据处理的分布性。中间件集分布式操作系统与网络操作系统的优点于一身,既能够具有网络操作系统的可扩展性和开放性,又能够具有分布式操作系统的透明性和与之相关的易用性。
分布式系统进程通信,rpc基本原理步骤
- 客户过程以正常方式调用客户存根
- 客户存根生成一个消息,然后调用本地操作系统
- 客户端操作系统将消息发送给远程操作系统,并阻塞客户过程
- 远程操作系统将消息交给服务器存根
- 服务器存根将参数提取出来,然后调用服务器
- 服务器执行要求的操作,操作完成后将结果返回给服务器存根
- 服务器存根将结果打成消息包,然后调用本地操作系统
- 服务器操作系统将消息发送回客户端操作系统
- 客户端操作系统将消息交给客户存根
- 客户存根将结果从消息中提取出来,返回给调用进程
移动agent特点
自主性;反应性;主动/面向目标;推理/学习/自适应能力;可移动性;社会性。
命名服务(优缺点)
移动实体定位
- 广播和多播
- 转发指针
- 给实体指定一个起始位置
- 创建一颗搜索树
并发,petri网建模
哲学家进餐

图解:
h-hunger k-thinking f –fork/chopstick e-eating
- 圆圈:hi,ki,ei,fi为库所
h:表示为哲学家饥饿状态库所 : k表示为哲学家思考状态的库所 e:表示为哲学家吃饭状态的库所 f:表示筷子处于备用状态的库所 - 黑色实心点为token。初始状态时:f0-f4中的是筷子,k0-k4中的是哲学家
- 方框为变迁
初始状态:筷子备用状态,处于f0-f4库所中。哲学家是思考状态,处于k0-k4中。
以哲学家0为例
- T1 变迁1(感到饥饿):哲学家在思考中感到饿了,从库所k0经过T1到达库所h0。哲学家从思考状态进入饥饿状态。
- T2变迁2(获得筷子):哲学家和筷子分别从h0,f4,f0库所经过T2迁移到库所e0。哲学家从饥饿状态进入吃饭状态。
- T3变迁3(释放筷子):吃完饭后,哲学家经过T3迁移到k0库所中,从吃饭状态转入思考状态。两只筷子经过T3,分别迁移到库所f0,f4,从使用状态进入备用状态。
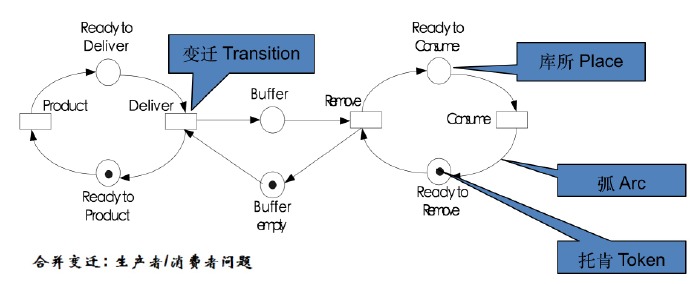
生产者消费者

移动mogent通信失效(本地和异地)的解决方案
- 分析
- 无论本地通信还是异地通信,其通信模型是一致的
- 通信失效本质上都是因为在路由信件和实际信件传输过程中,目标agent发生了物理位置的变化,而这种变化是随机的,不可预计的。
- 结论
- 通信失效现象并不是mogent系统特有的现象.它是一个因agent的移动而带来的可能会出现在任意一个移动agent系统中的普遍现象
- 其它系统的处理
- Aglets:未见
- Mole:
- 将失效信件扔弃;
- 扔弃的同时回送错误信息
- 将失效信件就地保存,待被通信agent在回送时交付
- 根本原因:
- 移动:随机改变位置信息
- 通信:要求位置信息“暂时”不变
- 通信和移动所共享的“位置”信息未进行同步控制是造成通信失效的根本原因
- 从OS进程互斥考虑,接收者的“位置”在通信失效问题中具有决定性的意义,当通信和移动相矛盾时,该“位置”就成为了一个必须互斥使用的“资源”
- “位置”的互斥 =》 “状态”的互斥
- 在一个能够避免通信失效的移动agent系统中,必须且只要做到以下三条 :
- 准确纪录agent的状态信息
- 只能向一个处于“静止态”的agent发送信件
- 信件发送过程中必须限制接收者从“静止态”向“移动态”的状态转换
同步:逻辑时间算法,向量时间戳(将每个时间的向量时间戳标出)
Lamport算法:不能反应因果关系。
向量时钟 :要求能计算出每个进程中的事件,标出向量的时间戳,不同事件之间的向量时间的大小关系,依赖关系与并发关系。
逻辑时钟
- 为了同步逻辑时钟,Lamport定义了一个称作 “先发生” (happens-before) 的关系。表达式ab读作 “a在b之前发生”,意思是所有进程一致认为事件a先发生,然后事件b才发生。这种先发生关系有两种情况。
- 如果a和b是同一个进程中的两个事件,且a在之前发生,则ab为真。
- 如果a是一个进程发送消息的事件,而b为另一个进程接收消息的事件,则ab也为真。消息不可能在发送之前被修改,也不能在发送的同时被接收,这是因为消息需要一定时间才能到达接收端。
- Lamport逻辑时间钟具有传递性和并发性;
- 对这个算法稍作补充就可以满足全局时间的需要。即在每两个事件之间,时钟必须至少滴答一次。如果一个进程以相当快的速度发送或者接受两个消息,那么它的时钟必须在这之间至少滴答一次。
- 在某些情况下还需要一个附加条件,即两个事件不会精确地同时发生。为了达到这个目标,我们可以将事件发生所在的进程号附加在时间的低位后,并用小数点分开。这样,如果进程1和进程2中的事件都发生在时刻40,那么前者记为40.1后者记为40.2。
- 使用这种方法,我们现在有了一个为分布式系统中的所有事件分配时间的方法,它遵循下面的规则:
- 若同一进程中a在b之前发生,则C(a)<C(b)。
- 若a和b分别代表发送一个消息和接收该消息的事件,则C(a)<C(b)。
- 对于所有不同的事件a和b,C(a) ≠ C(b)。
- 这个算法为我们提供了一种对系统中所有事件进行完全排序的方法。许多其他的分布式算法都需要这种排序以避免混淆,所以文献中广泛引用此算法。
- 使用Lamport时间戳后,只通过比较事件a和b各自的时间值C(a)和C(b),无法说明它们之间的关系。换句话所,C(a)<C(b)不能说明事件a就是在事件b之前发生。还需要另外一些信息。即 Lamport时间戳不能捕捉因果关系(causality)。
向量事件戳
为什么采用向量时间戳可以表示事件因果关系?
- 因果关系可以通过向量时间戳来捕获。分配给事件a的向量时间戳VT(a)具有下列性质:如果对某一事件b,有VT(a)<VT(b),那么认为事件a在因果关系上处于事件b之前。向量时间戳的创建是通过让每个进程P维护一个向量V来完成的,该向量具有下面两个性质:
- Vi[i]是到目前为止进程Pi发生的事件的数量。
- 如果Vi[j]=k,那么进程Pi知道进程Pj中已经发生了k个事件
- 第一个性质是通过在进程Pi中的新事件发生时递增Vi[i]来维护的。
- 第二个性质时通过在所发送的消息中携带向量来维护的。当进程Pi发送消息m时,它将自己的当前向量作为时间戳vt一起发送。
- 使用这种方式,接收者可以得知进程Pi中已经发生的事件数。
- 更重要的是,接收者可以得知进程Pi发送消息m之前其他进程已经发生了多少个事件。换句话说,消息m的时间戳vt告诉接收者其他进程中有多少事件发生在它之前,并且消息m可能在因果关系上依赖于这些事件。
- 当进程Pj接收到消息m时,它调整自己的向量,将每项Vj[k] 设置为max{Vj[k],vt[k]}。该向量现在反映了进程Pj必须接收的消息数,该消息数目至少是在发送消息m之前见到的消息。此后将Vj[i]项增1,这表示接收消息m的事件是来自于进程Pi的下一个事件。
只在不违背因果关系限制时,才能使用向量时间戳来传递消息。我们来再次考虑一下电子公告板的例子。当进程Pi张贴一篇文章时,它将该文章作为消息a广播出去,并且在该消息上附加一个时间戳vt(a),其值等于V。当另一个进程Pj接收到a时,它将调整自己的向量,以使Vj[i]=vt(a)[i]。 - 现在假设进程Pj张贴了一个该文章的回复。回复是通过该进程广播一个消息r实现的,消息r携带值等于Vj的时间戳vt(r)。注意vt(r)[i]> vt(a)[i]。假设通信是可靠的,包含文章的消息a和包含回复的消息r最终都到达了另一个进程Pk。因为我们没有对消息的顺序关系做出假设,所以消息r可能在消息a之前到达进程Pk。进程Pk接收到消息r时检查时间戳,并决定推迟提交消息r,直到因果关系上位于r之前的消息都接收到了才提交。消息r只有下列条件满足时才得到交付:
vt(r)[j]=vk[j]+1;
对于所有满足i¹j的i和j,vt(r)[i]< Vk[i]
第一个条件说明r是进程Pk正在等待的下一条来自进程Pj的消息。
第二个条件说明当进程Pj发送消息r时,进程Pk只看到被进程Pj看到的消息。这意味着进程Pk已经看到了消息。

一致性模型,要能写出以客户为中心的四个模型(条件描述)以数据为中心的三种类别(了解))
- 每一个以客户为中心的一致性模型是单调读的一致性模型。如果数据存储满足以下条件,那么称该数据存储提供单调读一致性(monotonic-read consistency):
- 如果一个进程读取数据x的值,那么该进程对执行任何后续读操作将总是得到第一次读取的那个值或更新的值。
也就是说,单调读一致性保证,如果一个进程已经在t时刻看到x的值,那么以后他不再会看到较老的版本的x的值。
- 在很多情况下,写操作以正确的顺序传播到数据存储的所有拷贝是非常重要的。这种性质被描述为单调写一致性。单调写一致性(monotonic-write consistency)的数据存储应该满足以下条件:
- 一个进程对数据项x执行的写操作必须在该进程对x执行任何后续写操作之前完成。
- 下面介绍一种与单调写一致性有密切关系的以客户为中心的一致性模型。如果数据存储满足以下条件,那么称该数据存储提供写后读一致性(read-your-writes consistency)。
- 一个进程对数据项x执行一次写操作的结果总是会被该进程对x执行的后续读操作看见。
也就是说,一个写操作总是在同一进程执行的后续读操作之前完成,而不管这个后续的读操作发生在什么位置。
- 最后一种以客户为中心的一致性模型是这样的模型,即更新是作为前一个读操作的结果传播的。如果数据存储满足以下条件,那么称该数据存储提供读后写一致性(writes-follow-reads consistency)。
- 同一个进程对数据项x执行的读操作之后的写操作,保证发生在与x读取值相同或比之更新的值上。
也就是说,进程对数据项上x所执行的任何后续的写操作都会在x的拷贝上执行,而该拷贝是用该进程最近读取的值更新的。
代码迁移(基础、分类)
分布式系统中的代码迁移是以进程迁移(process migration)的形式进行的,在这种形式下整个进程被从一台机器搬到另一台机器上去。其基本的思想是:如果把进程由负载较重的机器上转移到负载较轻的机器上去,就可以提升系统的整体性能。(迁移的是计算程序本身,而非数据)
分类
- 弱可迁移性:在这种模型中,可以只传输代码段以及某些初始化数据。弱可移动性的典型特征是,传输过来的程序总是以初始状态重新开始执行的。
- 强可移动性(strong mobility):它还可以迁移执行段。强可移动性的典型特征是,可以先停止运行中的进程,然后将它搬到另一台机器上去,再从刚才中断的位置继续执行。
分类(主动方):
- 发送者启动(sender-initiated)迁移:在这种模型中,代码当前驻留在哪台机器上或者正在哪台机器上执行,就由该机器来启动迁移。一般来说,在向计算服务器上载程序时进行的就是发送者启动的迁移。
- 接收者启动(receiver-initiated)迁移:代码迁移的主动权掌握在目标机器手中。Java小程序是这种迁移的一个例子。

事务提交:2pc\3pc
- 两阶段提交协议(2PC):考虑一个分布式事务中有很多进程作为参与者,每个进程都运行在不同的机器上。假定没有故障发生,协议就由以下两个阶段组成,每个阶段又由两步组成。
- 协调者向所有的参与者发送一个Vote_Request消息。
- 当参与者接收到Vote_Request消息时,就向协调者返回一个Vote_Commit消息通知协调者它已经准备好本地提交事务中属于它的部分,否则就返回一个Vote_Abort消息。
- 协调者收集来自参与者的所有选票。如果所有的参与者都表决要提交事务,那么协调者就进行提交。在这种情况下它向所有的参与者发送一个Global_Commit消息。但是,如果有一个参与者表决要取消事务,那么协调者就决定取消事务并多播一个Global_Abort消息。
- 每个提交表决的参与者都等待协调者的最后反应。如果参与者接收到一个Global_Commit消息,那么它就在本地提交事务,否则接收到一个Global_Abort消息时,就在本地取消事务。

- The finite state machine for the coordinator in 2PC.(协调者)
- The finite state machine for a participant.(参与者)
两阶段提交的一个问题在于当协调者崩溃时,参与者不能做出最后的决定。因此参与者可能在协调者恢复之前保持阻塞。三阶段提交协议(3PC),避免了在出现故障停机时的阻塞过程。
- 三阶段提交(3PC)
3PC的本质在于协调者和每个参与者都满足以下两个条件:
- 没有一个可以直接转换到Commit或者Abort状态的单独状态。
- 没有一个这样的状态:它不能做出最后决定,而且可以从它直接转换到Commit状态。
三阶段提交协议(3PC)的基本原理为:在2PC的参与者投票和协调者决策之间增加了“预提交”阶段。协调者在接收到所有参与者的提交票后发送一个全局预提交命令,当参与者接收到全局预提交命令之后,它就得知其他的参与者都投了提交票,从而确定自己在稍后肯定会执行提交操作,除非它失败了。每个参与者都对全局预提交发出确认消息,协调者一旦接收到所有参与者的确认消息就再发出“全局性提交”。3PC协议在站点失败,甚至是所有的站点都失败的情况下也不会带来阻塞。
它们各自的状态机如图所示。(a 协调者,b 参与者)


- 二者比较:
与2PC相比,3PC的主要不同点在于以下情况:崩溃的参与者可能恢复到了Commit状态而所有参与者还处于Ready状态。在这种情况下,其余的可能操作进程不能做出最后的决定,不得不在崩溃的进程恢复之前阻塞。在3PC中,只要有可操作的进程处于Ready状态,就没有崩溃的进程可以恢复到Init、Abort或Precommit之外的状态。因此存活进程总是可以做出的最后决定。
复制和一致性(四个经典模型(不带同步变量的))
- 严格一致性
条件定义:对于数据项x的任何读操作将返回最近一次对x进行的写操作的结果所对应的值。
严格一致性中存在的问题是它依赖于绝对的全局时间(注意由于技术的限制,我们需要处理同一时间间隔内所发生的多个操作)
(a)严格的一致性存储; (b) 非严格的一致性存储总之,当数据存储是严格一致的时候,对于所有的进程来说,所有写
操作是瞬间可见的,系统维持着一个绝对的全局时间顺序。(如果一
个数据项被改变了,那么无论数据项改变之后多久执行读操作,无论
哪些进程执行读操作,无论这些进程的位置如何,所有在该数据项上
执行的后续读操作都将得到新数值。同样,如果执行了读操作,那么
无论多快地执行下一个写操作,该读操作都将得到当前的值。 ) - 顺序一致性
条件定义:
任何执行结果都是相同的,就好像所有进程对数据存储的读、写操作 时按照某种序列顺序执行的,并且每个进程的操作按照程序所制定的 顺序出现在这个序列中。
(a) 顺序一致的数据存储; (b)非顺序一致的数据存储 - 线性一致性
条件定义:当数据存储上的每个操作都具有时间戳并满足以下条件时,称这个数据存储是可线性化的。任何执行结果都是相同的,就好像所有进程对数据存储的读、写操作是按某种顺序执行的,并且每个进程的操作按照顺序所执行的顺序出现在这个顺序中。另外,如果tsop1(x)<tsop2(y),那么在这个顺序中,操作OP1(x)出现在操作OP2之前。 (注意,可线性化的数据存储也是顺序一致的。它们的区别在于:线性化是根据一系列同步时钟确定序列顺序的。在实际应用中,线性化主要用于开发算法的形式验证。关于根据时间戳维护顺序的附加限制使得线性化的实现比顺序一致性的实现开销更大。Tsop(x)---时间戳)。
- 因果一致性
因果关系理解:考虑一个存储器的实例。假设进程P1对变量x执行了写操作。然后进程P2先读取x,然后对y执行写操作。这里,对x的读操作和对y的写操作具有潜在的因果关系,因为y的计算可能依赖于P2所读取的x值。没有因果关系的操作被称为并发的。
条件定义:所有进程必须以相同的顺序看到具有潜在因果关系的写操作。不同机器上的进程可以以不同的顺序被看到并发的写操作。
实现因果一致性要求跟踪哪些进程看到了哪些写操作。这意味着必须构建和维护一张记录哪些操作依赖于哪些操作的依赖关系图。一种实现方法是使用上一章所讨论的向量时间戳。


分布式系统算法(选举算法(欺负算法)、互斥算法(集中式带协调者的、分布式不带协调者的、recut、令牌环(不一定考)))
选举算法
欺负算法
1.1 当任何一个进程发现协调者不再响应请求时,它就发起一个选举。进程P按如下过程主持一次选举:
- 1.1.1 P向所有编号比它大的进程发送一个election消息;
- 1.1.2 如果无人响应,P获胜成为协调者;
- 1.1.3 如果有编号比它大的进程响应,则响应者接管选举工作。P的工作完成。


- (a) 进程4主持一个选举;
- (b) 进程5和6进行响应,告诉进程4停止选举;
- (c) 进程5和6此时各自主持一个选举;
- (d) 进程6通知进程5停止选举;
- (e) 进程6获胜,并通知每个进程。
互斥算法
集中式算法
只有一个协调者,无论何时一个进程要进入临界区,它都要向协调者发送一个请求消息,说明它想要进入哪个临界区并请求允许。如果当前没有其他进程在该临界区内,协调者就发送允许进入的应答消息。
- (a) 进程1请求协调者允许它进入一个临界区。请求得到了批准;
- (b) 进程2也请求进入同一个临界区。协调者不应答;进程2进入等待队列
- (c) 进程1在退出临界区时通知协调者,协调者然后做出应答。协调者再通知等待队列中的排在最前面的进程2进入临界区
- 优点:没有进程会处于永远等待状态(不会出现饿死的情况);易于实现,每使用一次临界区只需3条消息(请求、允许和释放);不仅能用于管理临界区,也可以用于更一般的资源分配。
- 缺点:协调者是一个单个故障点,所以如果它崩溃了,整个系统就可能瘫痪。在一般情况下,如果进程在发出请求之后被阻塞,那么请求者就不能区分“拒绝进入”和协调者已经崩溃这两种情况,因为上述两种情况都没有消息返回。此外,在规模较大的系统中,单个协调者会成为性能的瓶颈。
分布式算法
该算法的工作过程如下:当一个进程想进入一个临界区时,它构造一个消息,其中包含它要进入的临界区的名字、它的进程号和当前时间。然后它将消息发送给所有其他的进程,理论上讲也包括它自己。
当一个进程接收到来自另一个进程的请求消息时,它根据自己与消息中的临界区相关的状态来决定它要采取的动作。可以分为三种情况:
- 2.1 若接收者不再临界区也不想进入临界区,它就向发送者发送一个OK消息。
- 2.2 若接收者已经在临界区,它不进行应答,而是将该请求放入队列中。
- 2.3 如果接收者想进入临界区但尚未进入时,它将对收到的消息的时间戳和包含在它发送给其余进程的消息中的时间戳进行比较。时间戳最早的那个进程获胜。如果收到的消息的时间戳比较早,那么接收者向发送者发回一个OK消息。如果它自己的消息的时间戳比较早,那么接收者将接收到的请求放入队列中,并且不发送任何消息。
在发送了请求进入临界区的请求消息后,进程进行等待,直到其他所有进程都发回允许进入消息为止。一旦得到所有进程的允许,它就可以进入临界区了。当它退出临界区时,它向其他队列中的所有进程发送OK消息,并将它们从队列中删除。

- (a) 两个进程同时希望进入同一个临界区;
- (b) 进程0具有最早的时间戳,所以它获胜;
- (c) 当进程0退出临界区时,它发送一个OK消息,所以进程2现在可以进入临界区
- 优点:不会发生死锁或者饿死现象;最大的优点是不存在单个故障点。
- 缺点:单个故障点被n个故障点所取代;要求更多网络通信的算法;要么必须使用组通信原语,要么每个进程都必须自己维护组成员的清单,清单中包括进入组的进程、离开组的进程以及崩溃的进程。
令牌环
当环初始化时,进程0得到一个令牌token。该令牌绕着环运行,用点对点发送消息的方式把它从进程k传递到进程k+1(以环大小为模)。进程从它邻近的进程得到令牌后,检查自己是否要进入临界区。如果自己要进入临界区,那么它就进入临界区,做它要做的工作,然后离开临界区。在该进程退出临界区后,它沿着环继续传递令牌。不允许使用同一个令牌进入另一个临界区。如果一个进程得到了邻近进程传来的令牌,但是它并不想进入临界区,那么它只是将令牌沿环往下传递。
- 优点:不会发生饿死现象,那么最差的情况是等待其他所有进程都进入这个临界区然后再从中退出后它再进去。
- 缺点:如果令牌丢失了,那么它必须重新生成令牌,检测令牌丢失是很困难的;如果有进程崩溃,该算法也会出现麻烦,但是恢复起来比其他算法容易。