GPU线程及调度
本节主要讲述OpenCL中的Workgroup如何在硬件设备中被调度执行。同时也会讲一下同一个Workgroup中的workitem,如果它们执行的指令发生diverage(就是执行指令不一致)对性能的影响。学习OpenCL并行编程,不仅仅是对OpenCL Spec本身了解,更重要的是了解OpenCL硬件设备的特性,现阶段来说,主要是了解GPU的的架构特性,这样才能针对硬件特性优化算法。现在OpenCL的Spec是1.1,随着硬件的发展,相信OpenCL会支持更多的并行计算特性,基于OpenCL的并行计算才刚刚起步。
1、Workgroup到硬件线程
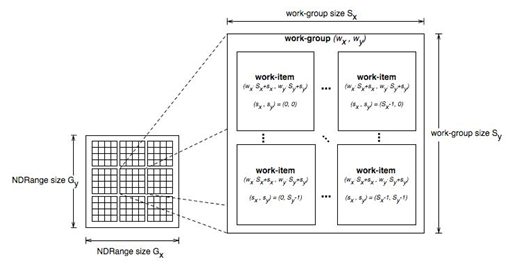
在OpenCL中,Kernel函数被workgroup中的workitem(线程,我可能混用这两个概念)执行。在硬件层次,workgroup被映射到硬件的cu(compute unit)单元来执行具体计算,而cu一般由更多的SIMT(单指令,线程)pe(processing elements)组成。这些pe执行具体的workitem计算,它们执行同样的指令,但操作的数据不一样,用simd的方式完成最终的计算。
由于硬件的限制,比如cu中pe数量的限制,实际上workgroup中线程并不是同时执行的,而是有一个调度单位,同一个workgroup中的线程,按照调度单位分组,然后一组一组调度硬件上去执行。这个调度单位在nv的硬件上称作warp,在AMD的硬件上称作wavefront,或者简称为wave。

上图显示了workgroup中,线程被划分为不同wave的分组情况。wave中的线程同步执行相同的指令,但每个线程都有自己的register状态,可以执行不同的控制分支。比如一个控制语句
if(A)
{
… //分支A
}
else
{
… //分支B
}
假设wave中的64个线程中,奇数线程执行分支A,偶数线程执行分支B,由于wave中的线程必须执行相同的指令,所以这条控制语句被拆分为两次执行[编译阶段进行了分支预测],第一次分支A的奇数线程执行,偶数线程进行空操作,第二次偶数线程执行,奇数线程空操作。硬件系统有一个64位mask寄存器,第一次是它为01…0101,第二次会进行反转操作10…1010,根据mask寄存器的置位情况,来选择执行不同的线程。可见对于分支多的kernel函数,如果不同线程的执行发生diverage的情况太多,会影响程序的性能。
2、AMD wave调度
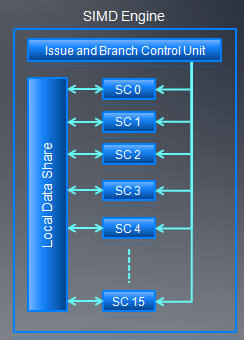
AMD GPU的线程调度单位是wave,每个wave的大小是64。指令发射单元发射5路的VLIW指令,每个stream core(SC)执行一条VLIW指令,16个stream core在一个时钟周期执行16条VLIW指令。每个时钟周期,1/4wave被完成,整个wave完成需要四个连续的时钟周期。
另外还有以下几点值得我们了解:
- 发生RAW hazard情况下,整个wave必须stall 4个时钟周期,这时,如果其它的wave可以利用,ALU会执行其它的wave以便隐藏时延,8个时钟周期后,如果先前等待wave已经准备好了,ALU会继续执行这个wave。
- 两个wave能够完全隐藏RAW时延。第一个wave执行时候,第二个wave在调度等待数据,第一个wave执行完时,第二个wave可以立即开始执行。
3、NV warp调度
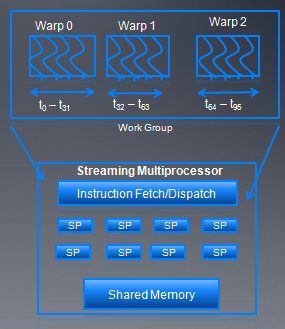
work group以32个线程为单位,分成不同warp,这些warp被SM调度执行。每次warp中一半的线程被发射执行,而且这些线程能够交错执行。可以用的warp数量依赖于每个block的资源情况。除了大小不一样外,wave和warp在硬件特性上很相似。
4、Occupancy开销
在每个cu中,同时激活的wave数量是受限制的,这和每个线程使用register和local memory大小有关,因为对于每个cu,register和local memory总量是一定的。
我们用术语Occupancy来衡量一个cu中active wave的数量。如果同时激活的wave越多,能更好的隐藏时延,在后面性能优化的章节中,我们还会更具体讨论Occupancy。
5、控制流和分支预测(prediction)
前面我说了if else的分支执行情况,当一个wave中不同线程出现diverage的时候,会通过mask来控制线程的执行路径。这种预测(prediction)的方式基于下面的考虑:
- 分支的代码都比较短
- 这种prediction的方式比条件指令更高效。
- 在编译阶段,编译器能够用predition替换switch或者if else。
prediction 可以定义为:根据判断条件,条件码被设置为true或者false。
例如上面的代码就是可预测的,
Predicate = True for threads 0,2,4….
Predicate = False for threads 1,3,5….
下面在看一个控制流diverage的例子
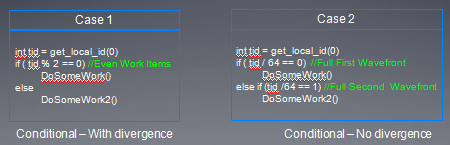
- 在case1中,所有奇数线程执行DoSomeWork2(),所有偶数线程执行DoSomeWorks,但是在每个wave中,if和else代码指令都要被发射。
- 在case2中,第一个wave执行if,其它的wave执行else,这种情况下,每个wave中,if和else代码只被发射一个。

在prediction下,指令执行时间是if,else两个代码快执行时间之和。
6、Warp voting
warp voting是一个warp内的线程之间隐式同步的机制。
比如一个warp内线程同时写Local meory某个地址,在线程并发执行时候,warp voting机制可以保证它们的前后顺序正确。更详细的warp voting大家可以参考cuda的资料。>
在OpenCL编程中,由于各种硬件设备不同,导致我们必须针对不同的硬件进行优化,这也是OpenCL编程的一个挑战,比如warp和wave数量的不同,使得我们在设计workgroup大小时候,必须针对自己的平台进行优化,如果选择32,对于AMD GPU,可能一个wave中32线程是空操作,而如果选择64,对nv GPU来说,可能会出现资源竞争的情况加剧,比如register以及local meomory的分配等等。这儿还不说混合CPU device的情况,OpenCL并行编程的道路还很漫长,期待新的OpenCL架构的出现。