原理
NFS允许用户像访问本地文件系统一样访问远程文件系统,而将NFS引入HDFS后,用户可像读写本地文件一样读写HDFS上的文件,大大简化了HDFS使用,这是通过引入一个NFS gateway服务实现的,该服务能将NFS协议转换为HDFS访问协议,具体如下图所示。
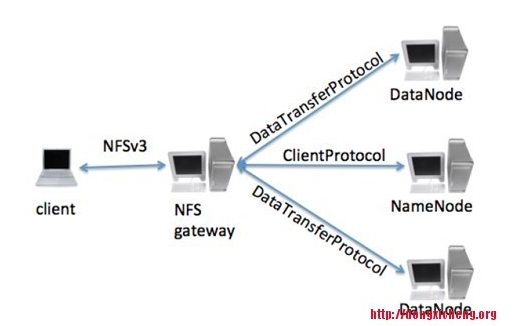
Portmap和Nfs3进程是成功启动hdfs nfs网关后才有的进程
HDFS NFS Gateway安装配置详解
http://blog.csdn.net/rzliuwei/article/details/38388279
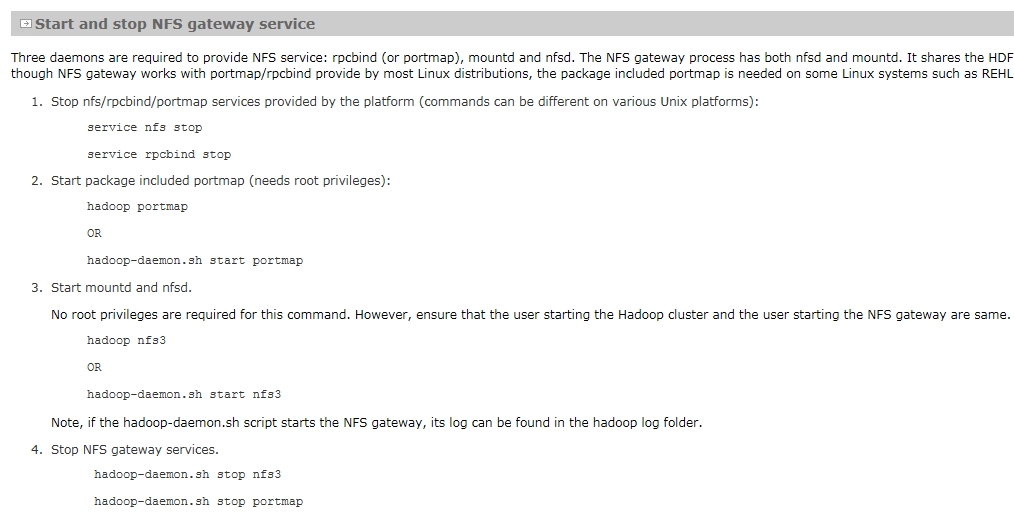
启动NFS Gateway 服务
官网链接
http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-hdfs/HdfsNfsGateway.html
验证服务
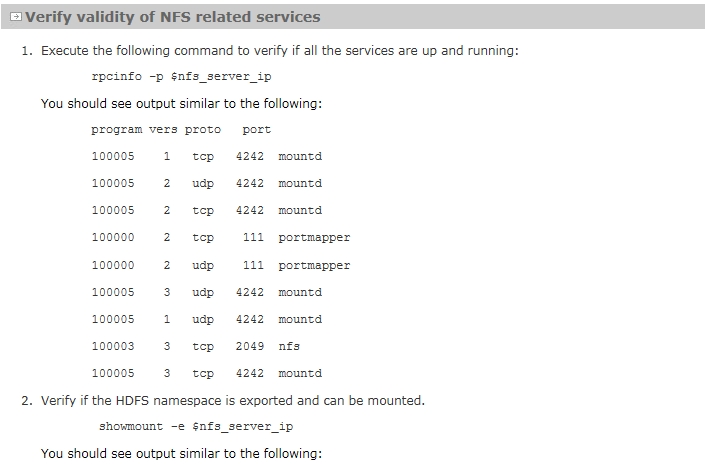

如果不是可以查看/etc/exports文件

挂载HDFS
挂载HDFS文件系统到本地的/mnt/hdfs目录下
在NFS GATEWAY主机上输入
sudo mount -t nfs -o vers=3,proto=tcp,nolock 192.168.1.105:/ /mnt/hdfs
May 8 15:53:18 cdh1 rpc.mountd[3689]: refused mount request from 192.168.1.105 for / (/): unmatched host
如果报错因为机器默认没有打开NFSv3,修改/etc/sysconfig/nfs文件
把RPCNFSDARGS="-N 4"前面的#去掉(4兼容2和3),修改重启所有服务。

查看报错详细信息:
cat /var/log/messages|grep mount
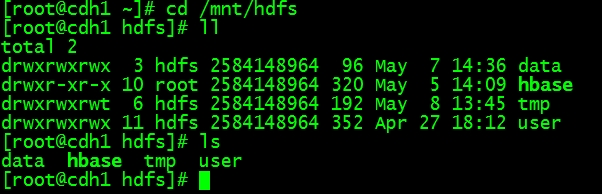
成功挂载后如下所示,可以看到HDFS文件系统已挂载到本地目录
创建目录

可以看到HDFS系统上对应目录已创建成功
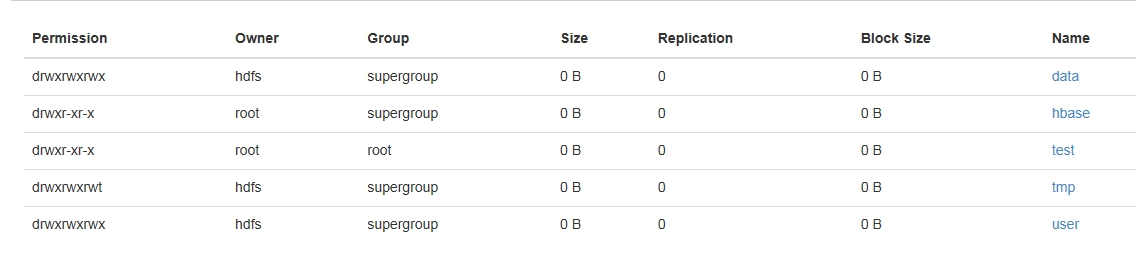
从本地上传文件到HDFS
文件大小为500m,测试性能
time cp /opt/cloudera-manager-el6-cm5.3.3_x86_64.tar.gz /mnt/hdfs/test

我的环境上耗时大概48s,10M/s的速度,还可以
解挂HDFS
报错umount.nfs: /mnt/hdfs: device is busy

fuser -m /mnt/hdfs,查看此文件系统正在被哪些进程访问

yum -y install lsof
查看此文件系统中正在被使用的文件,可以看到/data目录被正在使用

kill -9 15355 杀死访问进程就可以,输入umount /mnt/hdfs解挂成功。
补充:
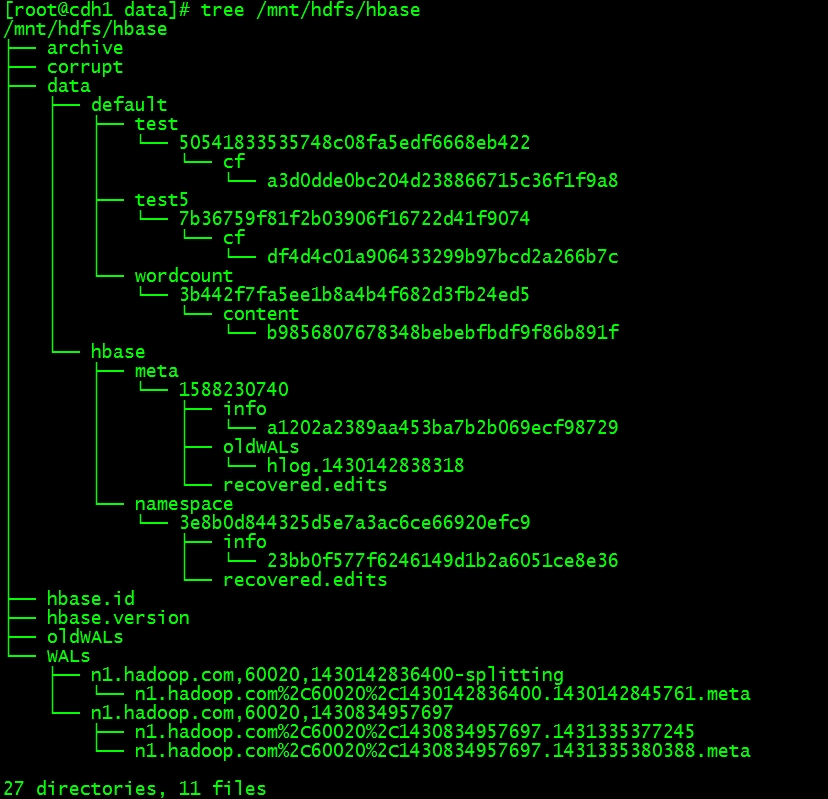
linux下好用的命令:tree
安装tree包
yum -y install tree
安装后键入 tree /mnt/hdfs/hbase,目录结构以树形的方式显示是不是很直观
本文出自 “点滴积累” 博客,请务必保留此出处http://tianxingzhe.blog.51cto.com/3390077/1650182