11.17 基于聚类规则项的多任务聚类方法
多任务学习方法能够对交通路网中的多个节点同时进行分析,这满足了交通的网络性特点所提出的要求。进一步的,异质的多任务学习方法又对应了交通中关联关系的异质性特点。图 2 给出了我国山西省高速交通路网的交通流分配情况,可以看出,交通路网中异质的车流常常存在局部集中的特点,如果将这些车流集中的局部区域标记出来,则可以得到图中的聚类模式。假设当前要学习的任务是高速路网中出口流量的预测问题,那么图 2(a) 则表示出了这些预测任务的聚类模式示意图,图中红色的虚线圆圈可以看作出口的聚类,其意义在于同一个类簇中的出口预测任务是高度相关的,那么相应的基于任务聚类的多任务学习方法便可以应用于交通流分析。然而,将目前已有的多任务聚类方法直接应用于交通场景并不恰当,因为目前的基于任务聚类的多任务学习方法都需要在学习之前先指定任务类簇的数目,但这一数目在真实交通问题中是未知的,例如图 2(a) 中虚线圆圈的个数。本章针对现有基于任务聚类的多任务学习方法的不足,提出了一种基于聚类规则项的多任务聚类方法 (CRMTL, Clustered Regularization based Multi-Task Learning)。该方法采用一种新颖的聚类规则项,其优点在于不需要事先指定任务聚类的个数,而是从数据中自主地学习出聚类结构。该模型的目标函数形式如下: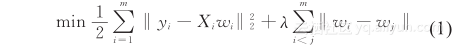
其中,y i 和 X i 分别为第 i 个任务 ( 共 m 个任务 ) 的输入和输出;W 为模型参数,w i 为矩阵 W 的第 i 列;λ 为规则项系数。式 (1) 中的第一项为损失函数;第二项为聚类规则项,该规则项对任意两个任务列向量的差值添加第二范式,其作用是迫使任意两个任务 i 和 j 尽可能的相似,从而将相似的任务聚类。λ控制了聚类的强度,当 λ 越大时,聚类的个数越少。上述聚类规则项的优点是不需要事先给定任务聚类的数目,而是通过规则项对任务列向量进行约束,从数据中自主地学习出任务聚类模式。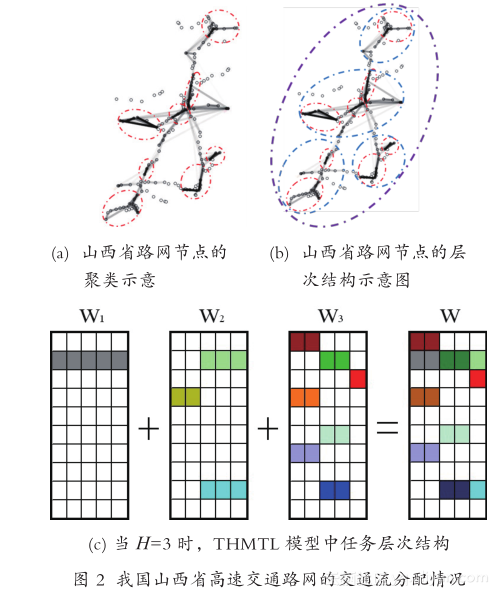
注意,式 (1) 中的聚类规则项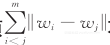 不同于特征学习中的特征聚类规则项 Fused Lasso [3] 。Fused Lasso 规则项用于对特征进行聚类,其特点是对任意两个标量做差,然后取所有差值的绝对值的和作为规则项。而式 (1) 中的聚类规则项是对任意两个向量做差,然后取所有差值向量的第二范式的求和作为规则项。求解基于向量差值的规则项要比求解基于标量差值的规则项更困难[4] 。
不同于特征学习中的特征聚类规则项 Fused Lasso [3] 。Fused Lasso 规则项用于对特征进行聚类,其特点是对任意两个标量做差,然后取所有差值的绝对值的和作为规则项。而式 (1) 中的聚类规则项是对任意两个向量做差,然后取所有差值向量的第二范式的求和作为规则项。求解基于向量差值的规则项要比求解基于标量差值的规则项更困难[4] 。
命题 1 式 (1) 中的目标函数为凸函数 (Convex),其中的聚类规则项为非光滑 (Non-Smooth) 函数。
命题 1 给出了 CRMTL 模型目标函数的求解性质。虽然式 (1) 中的优化问题为凸函数优化问题,然而聚类规则项却为非光滑的函数。这使得式 (1)的梯度无法直接求得,因此基于梯度的优化方法无法直接使用。在机器学习方法中,常用的处理非光滑函数的方法为次梯度 (Sub-Gradient) 法[5] ,然而该方法的计算非常耗时。因此,求解 CRMTL 模型较为困难。本文提出了一种针对 CRMTL 的高效光滑近似优化算法 ( 详细内容请参看全文 )。