简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block,不足一64M的就以实际文件大小为block存在DataNode中。然后将block按键值对(形如:Block1: host2,host1,host3)存储在HDFS上,并将键值对的映射存到NameNode的内存中。一个键值对的映射大约为150个字节(如果存储1亿个文件,则NameNode需要20G空间),如果小文件太多,则会在NameNode中产生相应多的键值对映射,那NameNode内存的负担会很重。而且处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
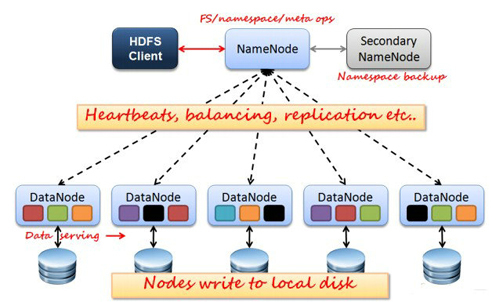
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是HDFS的管理员。管理数据块映射;处理客户端的读写请求;负责维护元信息;配置副本策略;管理HDFS的名称空间等
SecondaryNameNode:负责元信息和日志的合并;合并fsimage和fsedits然后再发给namenode。
PS:NameNode和SecondaryNameNode两者没有关系,更加不是备份,NameNode挂掉的时候SecondaryNameNode并不能顶替他的工作。
然而,由于NameNode单点问题,在Hadoop2中NameNode以集群的方式部署主要表现为HDFS Feration和HA,从而省去了SecondaryNode的存在,关于Hadoop2.x的改进移步hadoop1.x 与hadoop2.x 架构变化分析
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)是在NameNode启动时对整个文件系统的快照
edits:启动后NameNode对元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
NameNode的重启会花费很长时间,因为有很多在edit logs中的改动要合并到fsimage文件上。
如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
那么其实可以在NameNode中起一个程序定时进行新的fsimage=edits+fsimage的更新,但是有一个更好的方法是SecondaryNameNode。
SecondaryNameNode的职责是合并NameNode的edit logs到fsimage文件中,减少NameNode下一次重启过程
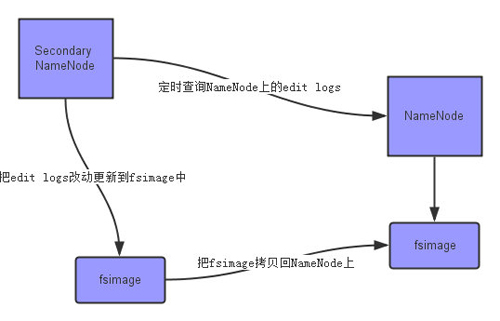
上面的图片展示了Secondary NameNode是怎么工作的。
- 首先,它定时到NameNode去获取edit logs,并更新到自己的fsimage上。
- 一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
- NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量和下一次重启过程。
工作原理
写操作:
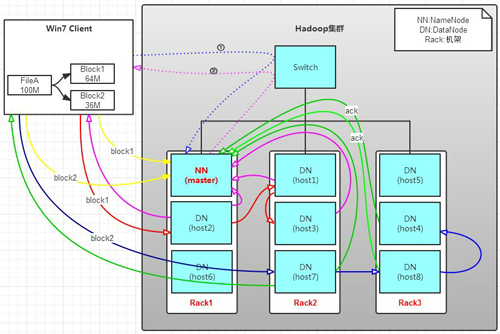
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息(即键值对的映射)。并返回可用的DataNode,如粉色虚线②------>。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量带宽。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
读操作:
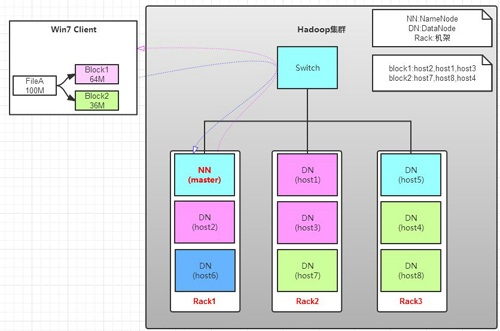
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息(键值对的映射),返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优先读取本机架上的数据。
HDFS中常用到的命令
1、hadoop fs
- hadoop fs -ls /
- hadoop fs -lsr
- hadoop fs -mkdir /user/hadoop
- hadoop fs -put a.txt /user/hadoop/
- hadoop fs -get /user/hadoop/a.txt /
- hadoop fs -cp src dst
- hadoop fs -mv src dst
- hadoop fs -cat /user/hadoop/a.txt
- hadoop fs -rm /user/hadoop/a.txt
- hadoop fs -rmr /user/hadoop/a.txt
- hadoop fs -text /user/hadoop/a.txt
- hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。
- hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。
2、hadoop fsadmin?
- hadoop dfsadmin -report
- hadoop dfsadmin -safemode enter | leave | get | wait
- hadoop dfsadmin -setBalancerBandwidth 1000
3、hadoop fsck
4、start-balancer.sh
注意,看了hdfs的布局,以及作用,这里需要考虑几个问题:
1、既然NameNode,存储小文件不太合适,那小文件如何处理?
至少有两种场景下会产生大量的小文件:
(1)这些小文件都是一个大逻辑文件的一部分。由于HDFS在2.x版本开始支持对文件的append,所以在此之前保存无边界文件(例如,log文件)(译者注:持续产生的文件,例如日志每天都会生成)一种常用的方式就是将这些数据以块的形式写入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。
(2)文件本身就是很小。设想一下,我们有一个很大的图片语料库,每一个图片都是一个独一的文件,并且没有一种很好的方法来将这些文件合并为一个大的文件。
(1)第一种情况
对于第一种情况,文件是许多记录(Records)组成的,那么可以通过调用HDFS的sync()方法(和append方法结合使用),每隔一定时间生成一个大文件。或者,可以通过写一个程序来来合并这些小文件(可以看一下Nathan Marz关于Consolidator一种小工具的文章)。
(2)第二种情况
对于第二种情况,就需要某种形式的容器通过某种方式来对这些文件进行分组。Hadoop提供了一些选择:
HAR File
Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出现就是为了缓解大量小文件消耗NameNode内存的问题。HAR文件是通过在HDFS上构建一个分层文件系统来工作。HAR文件通过hadoop archive命令来创建,而这个命令实 际上是运行了一个MapReduce作业来将小文件打包成少量的HDFS文件(译者注:将小文件进行合并几个大文件)。对于client端来说,使用HAR文件没有任何的改变:所有的原始文件都可见以及可访问(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中文件数却减少了。
读取HAR中的文件不如读取HDFS中的文件更有效,并且实际上可能较慢,因为每个HAR文件访问需要读取两个索引文件以及还要读取数据文件本身(如下图)。尽管HAR文件可以用作MapReduce的输入,但是没有特殊的魔法允许MapReduce直接操作HAR在HDFS块上的所有文件(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考虑通过创建一种input format,充分利用HAR文件的局部性优势,但是目前还没有这种input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565(https://issues.apache.org/jira/browse/HADOOP-4565)的改进,但始终还是需要每个小文件的寻找。我们非常有兴趣看到这个与SequenceFile进行对比。 在目前看来,HARs可能最好仅用于存储文档(At the current time HARs are probably best used purely for archival purposes.)
2、NameNode在内存中存储了meta等信息,那么内存的瓶颈如何解决?
3、Secondary是NameNode的冷备份,那么SecondaryNamenode和Namenode不应该放到一台设备上,因为Namenode宕掉之后,SecondaryNamenode一般也就死了,那讲SecondaryNameNode放到其他机器上,如何配置?
4、NameNode宕机后,如何利用secondaryNameNode上面的备份的数据,恢复Namenode?
5、设备宕机,那么,文件的replication备份数目,就会小于配置值,那么该怎么办?
本文作者:佚名
来源:51CTO