1.1 大数据分析以及 Hadoop 和 Spark 在其中承担的角色
传统的数据分析使用关系型数据库管理系统(Relational Database Management System,RDBMS)的数据库来创建数据仓库和数据集市,以便使用商业智能工具进行分析。RDBMS 数据库采用的是写时模式(Schema-on-Write)的方法,而这种方法有许多缺点。
传统数据仓库的设计思想是用于提取、转换和加载(Extract, Transform, and Load,ETL)数据,据此回答与用户需求直接相关的一组预先定义的问题。这些预先定义的问题是利用 SQL 查询来回答的。一旦数据以易于访问的(consumable)格式进行转换和加载,用户就可以通过各种工具和应用程序访问它,从而生成报告和仪表板。但是,以易于访问的格式创建数据需要几个步骤,如下所示:
(1)确定预先定义的问题。
(2)从数据源系统识别和收集数据。
(3)创建 ETL 流水线,把数据以易于访问的格式加载到分析型数据库里。
如果有了新的问题,系统就需要识别和添加新的数据源并创建新的ETL流水线。这涉及数据库中的模式更改,实施工作通常会持续1~6个月。这是一个很重大的约束,迫使数据分析人员只能在预定义的范围内进行操作。
将数据转换为易于访问的格式通常会导致丢失原始/原子数据,而这些数据可能含有我们正在寻找的答案的结论或线索。
处理结构化和非结构化数据是传统数据仓库系统中的另一个挑战。有效地存储和处理大型二进制图像或视频也总是有挑战性的。
大数据分析是不使用关系数据库的;相反,它通常借助Hive和HBase在Hadoop平台上使用读取模式(Schema-on-Read,SOR)方法 。这种方法有许多优点。图1-2比较了 Schema-on-Write和Schema-on-Read 的场景。
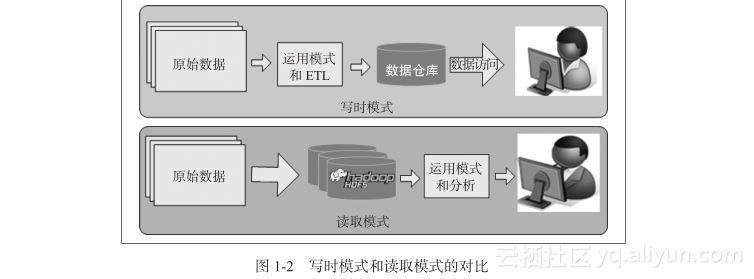
读取模式方法为系统带来了灵活性和可重用性。读取模式的范例强调以原始的、未修改的格式存储数据,并且通常在读取或处理数据时,会根据需要将某个模式应用于数据。这种方法让存储数据的数量和类型具有更大的灵活性。同一组原始数据可以应用多个模式,以提出各种问题。如果需要回答新问题,只需获取新数据并将其存储在HDFS的一个新目录中,就可以开始回答新问题了。
这种方法还为使用多种方法和工具访问数据提供了巨大的灵活性。例如,可以使用 SQL分析工具或Spark中的复杂Python或R脚本来分析同一组原始数据。由于我们并不会把数据存储在ETL所需的多个层中,因此可以降低存储成本和数据转移成本。非结构化和结构化的数据源都可以和结构化的数据源一起进行分析。
1.1.1 典型大数据分析项目的生命周期
使用大数据平台(如 Hadoop)进行大数据分析的生命周期与传统的数据分析项目类似。不过,大数据分析有个根本的格局转变,那就是使用读取模式方法进行数据分析。
一个大数据分析项目涉及的活动如图1-3所示。

1. 识别问题和结果
首先要明确项目的业务问题和期望的结果,以便确定需要哪些数据,可以进行哪些分析。业务问题的一些示例是公司销售额下降、客户访问了网站但没有购买产品、客户放弃了购物车、支持电话热线呼叫量的突然增加等。而项目成果的一些示例是把购买率提高 10%、将购物车放弃率降低50%、在下一季度让支持电话量减少50%的同时保持客户满意度。
2. 识别必要的数据
要确定数据的质量、数量、格式和来源。数据源可以是数据仓库(OLAP)、应用程序数据库(OLTP)、来自服务器的日志文件、来自互联网的文档,以及从传感器和网络集线器生成的数据。要识别所有内部和外部数据源的需求。此外,要确定数据匿名化和重新进行身份信息处理的要求,以删除或掩盖个人身份信息(personally identifiable information,PII)。
3. 数据收集
我们可以使用Sqoop工具从关系数据库收集数据,并使用Flume来对数据进行流式传输。我们还可以考虑使用Apache Kafka来实现可靠的中间存储。在设计和收集数据的时候,还要考虑容错的情况。
4. 预处理数据和ETL
我们得到的数据会有不同的格式,也可能有数据质量问题。预处理步骤的作用是把数据转换为所需的格式,或清理不一致、无效或损坏的数据。一旦数据符合所需的格式,就可以启动执行分析阶段的工作。Apache Hive、Apache Pig和Spark SQL都是对海量数据进行预处理的优秀工具。
在某些项目中,如果数据已经具备了整洁的格式,或者分析过程是使用读取模式(Schema-on-Read)方法直接针对源数据进行的,那可能就不需要这个步骤了。
5. 进行分析
我们进行分析的目的是回答业务方面的问题。这就需要了解数据以及数据点之间的关系。进行分析的类型有描述性和诊断性分析,得到的是数据的过去和当前视图。它通常回答的是像 “发生了什么事情?”和“为什么发生?”这样的一些问题。在某些情况下也会进行预测分析,它回答的问题是,基于某个假设会发生什么情况,诸如此类。
Apache Hive、Pig、Impala、Drill、Tez、Apache Spark和HBase都是在批处理模式下进行数据分析的优秀工具。而Impala、Tez、Drill和Spark SQL等实时分析工具可以集成到传统的商业智能工具(Tableau、Qlikview等)里,用于交互式分析。
6. 数据可视化
数据可视化是把分析结果以图像或图形格式来呈现,以便更好地理解分析结果,并根据这些数据做出业务决策。
通常,我们可以使用Sqoop将最终数据从Hadoop导出到RDBMS数据库,以便集成到可视化系统中;也可以把可视化系统直接集成到Tableau、Qlikview、Excel这些工具中。基于Web的笔记本(如 Jupyter、Zeppelin和Databricks cloud等)也可以通过和Hadoop及 Spark组件进行集成,用于实现数据的可视化。
1.1.2 Hadoop和Spark承担的角色
Hadoop和Spark为你提供了大数据分析的极大灵活性:
