
你希望学习文本挖掘,却发现大多数教程难度跨度很大?或者说你找不到心仪的数据集?
本文将会通过 8 个小贴士帮助你走进文本挖掘之门。
对文本保持好奇
在数据科学世界中,凡事的第一步都是“感到好奇”,文本挖掘也不例外。
就像 StackOverflow 的数据科学家 David Robinson 在他的博客中说的那样,“当我看到一个假设 […] 我就迫不及待地想要用数据验证它”。你也应该像他那样对文本保持好奇心。
David Robinson 看到的假设是:
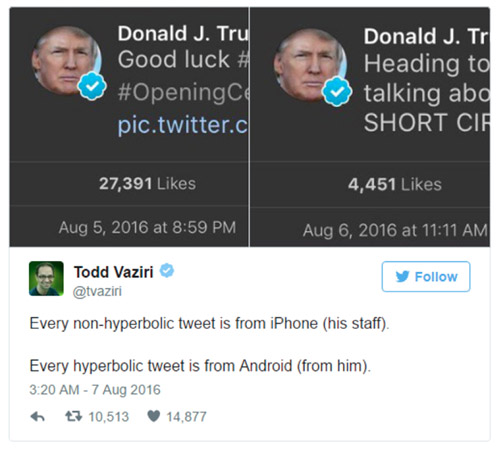
即使你并不打算真的去验证它,你也应该对自己看到的词云图感到好奇,并且有想要自己动手复现一遍的想法。
如果你还未能感受到文本挖掘的魅力,那就来看看这些最近在媒体上广受关注的文本挖掘应用案例吧,比如 South Park dialogue, film dialogue 等等,你会从中得到启发。
掌握你所需要的知识和技能

当你拥有了好奇心,是时候去学习关于文本挖掘的知识和技能了。你可以通过完成一些教学课程轻松地做到这一步。
在这些教程中你需要格外关注的是数据科学工作流中的基本步骤,比如数据预备和预处理,数据探索,数据分析等等。
推荐阅读:
- Ted Kwartler: Text Mining in R: Are Pokémon GO Mentions Really Driving Up Stock Prices?
- Ted Kwartler: Text Mining: Bag of Words
- Neal Caren: An introduction to text analysis with Python
- Kaggle: Part 1: For Beginners – Bag of Words
- DataCamp: Learn Data Science – Resources for Python & R
词语,词语,词语 – 寻找你的数据

一旦你掌握了分析和展现数据所需的基本概念和方法,就可以开始寻找你的数据了!
有非常多途径可以找到你心仪的数据,除了 google trends 和雅虎,你还可以从以下途径获取数据:
- 推特!R 和 Python 都提供了连接推特 API 的包或库。
- The Internet Archive, 一个非营利性的资料库,包含上百万的免费图书、电影、软件、音乐、网页等等。
- Project Gutenberg, 提供超过 55000 本免费电子书。大多数是成熟文献,如果你想要对如像莎士比亚、简·奥斯汀、爱伦坡这样的作家的用词进行分析,它会是很好的资源。
- 在学术方面,你可以使用 JSTOR’s data for research。这是一个免费的自助工具,允许计算机科学、数字人文主义者和其他研究者使用 JSTOR 上的内容。
- 如果你打算像开头的例子中一样对剧集或者电影进行文本挖掘,你可能需要考虑下载字幕。只要谷歌一下就能得到你想要的文本挖掘语料。
- 你也可以从语料库开始。两个著名的语料库是:
The Reuters Text Corpus, 一些人对这个语料库是不是最多样化的语料库有争议,但是它仍然对你开始学习文本挖掘很有帮助;
Brown Corpus, 包括500种来源的文本,并已经根据类型分类。
如你所见,文本来源有无限可能。任何包含文本的东西都可以成为你的文本挖掘案例学习的主题。
寻找合适的工具

现在你已经找到了你的数据的来源,你可能需要使用合适的工具来对他们进行处理。你已经学习的教学课程应该已经为你提供了许多入门工具。
但是,如果你仅仅学习了教学课程,你可能错过了一些东西,比如下文会介绍的用 R 进行文本挖掘时会用到的包:
- 在R中进行文本挖掘时最常用的包毫无疑问是 tm 包。这个包常被加入到其他包中,比如 twitterR 包,通过这个包你可以从推特的网页上提取推文和关注者等。
- 在 R 中进行网页爬虫的时候你需要 rvest 包,这里有一个简短的 rvest 教程。
- 对于Python,你可以使用以下库:
- 自然语言工具箱,包含在 nltk 包中,这个包是极其实用的,因为他提供了超过 50 种语料库和词汇资源的入口。你可以查看 nltk 数据列表。
- 如果你想要挖掘推特数据,你有许多包可以选择。其中最广泛被使用的是 tweey 包
- 对于网页爬虫,scrapy 包是最容易上手的,也可以考虑使用 urllib2,这是一个用来打开网页链接的包。有时候更推荐使用 requests, 因为某些场合下它可能更方便使用。也有些人说它更加人性化,因为诸如设置 user-agent 和请求页面都只需要一行代码。偶尔你会看到有人提到并不太流行的 urllib包,大多数开发者提到它只是因为他们在里面找到一两个他们觉得特别实用的函数。
充分的准备是成功的一半——数据预处理

数据科学家工作中 80% 的时间用在数据清洗上,文本挖掘也不例外。
如果你不确定要怎么预处理,以下是一些标准流程中的步骤:
- 从文本中提取出你想要处理的格式和结构,
- 去掉如 “that” 和 “and” 这样的停用词,
- 词干化(提取词根)。这一步需要字典、语言学规则或算法(如 Porter 算法)的帮助。
这些步骤看起来很难,实际上你不用每一步都自己实现。大多数情况下,上文中提到的库和包都能帮你实现这些步骤。比如 R 中的 tm 包可以让你通过其内置函数完成词干化、去除停止词、消除空白以及小写转换。类似的,Python 中的 nltk 库也可以通过其内置函数完成这些预处理过程。
然而,你可能仍然需要进一步使用正则表达式来描述你需要的文本模式,以便进一步预处理。这也可以加速你的数据清理过程。
对于 Python, 你可以使用 re 库,而在 R 中,有许多内置函数,如 grep(), grepl(), regexpr(), gregexpr(), sub(), gsub() 和 strsplit()。
如果你想要更加深入地了解这些函数,或者 R 中的正则表达式,你可以查看这个正则表达式介绍网页。
数据科学家的仙境冒险——数据探索

到目前为止,你已经摩拳擦掌准备开始分析了。但是,在分析之前最好还是先看看数据长什么样子。
利用上文提到的那些包和库,你可以快速地进行一些数据探索工作:
- 创建一个文档词项矩阵:该矩阵中的元素表示语料库中一篇文档内,一个词项(一个单词或者一个 n 元词组)出现的频繁程度。
- 当你创建了文档词项矩阵,你可以绘制直方图来可视化语料库中的词汇频率。
- 你也可以计算语料库中两个或更多词项之间的相关性。
- 你可以使用词云图来可视化你的语料库。在 R 中你可以使用 wordcloud 包来绘制,Python 中也有一个同名的库。
经过数据探索过程,你会对你接下来分析中,要分析的对象有一定的了解。如果你看到文档词汇矩阵或者直方图中有很多词语是稀疏的,你可以考虑将他们去掉。
提升你的文本挖掘技能

当你使用上述工具完成了预处理和基本的文本分析等步骤,你可以考虑通过你的数据集,进一步扩展你的文本挖掘技能。因为到现在,你看到的技巧提示都只是文本挖掘的冰山一角。
首先,你应该考虑探索文本挖掘和自然语言处理(NLP)的区别。更多关于 NLP 的 R 包可以在这个 NLP 的 R 包网页找到。NLP 中,你会学习到命名实体识别、词性标注、篇章分析、情感分析等内容。对于 Python, 你可以使用 nltk 库。这个使用 nltk 库进行情感分析完全指南会对你有所帮助。
除了这些包,还有诸如深度学习、统计主题发现模型(如隐式狄利克雷分配,LDA)等工具等着你去学习。这些算法对应的包有:
- Python 库:gensim,这个库可以实现 word2vec, GloVe, LDA 等算法。此外,如果你需要研究深度学习,theano 是一个很值得考虑的库。
- R 包:text2vec 包可以用于实现文本向量化和词嵌入。如果你对情感分析感兴趣,使用 syuzhet 和 tm 包可以完成这个任务。最后,topicmodes 包可以用于实现统计主题发现模型。
当然,并不仅仅只有这些包。
不止是词语——结果可视化

可视化是一种非常吸引人的表达方式,所以将结果可视化可能是你能做的最美妙的事情!注意,你要可视化的是你要讲的故事,而不是将你分析中发现的关联性或者话题可视化。
Python 和 R 中都有许多可视化包:
对于 Python, 你可以考虑使用 NetworkX 库来可视化复杂网络,matplotlib 包可以用来解决其他可视化问题。此外,plotly 包让你可以发布可交互在线图表。试着将 Python 和 D3 联系起来会得到更好的效果。D3 是一个用于动态数据操纵和可视化的 JavaScript 库,可以让你的读者和听众参与到数据可视化的过程中来。
对于 R, 除了 ggplot2 等大家耳熟能详的包,你也可以使用 igraph 包来分析关注、被关注以及转发微博等关系。此外,plotly 和 networkD3 包可以把 R 和 JavaScript 链接起来,LDAvis 包则可以将主题模型进行可交互的可视化。
本文作者:佚名
来源:51CTO