7.4 随机存取二进制文件
前面几节中,工作的基础是程序的所有数据都是作为一个整体读入内存、进行适当处理,最后再作为整体写出。现代计算机具有很大的RAM容量,使得这种方法可以有效运作,即便对很大的数据集也是如此。然而,有些情况下,将数据存放在磁盘上,并只读入需要的部分,处理之后再将变化的部分写回磁盘,这是一种更好的解决方案。基于磁盘的随机存取方法最易于使用键-值数据库(“DBM”)或完整的SQL数据库来实现——两者都将在第12章进行介绍——但在这一节中,我们将展示如何手动处理随机存取文件。
我们首先给出的是BinaryRecordFile.BinaryRecordFile类,该类的实例用于表示通用的可读/可写二进制文件,在结构上则是固定长度的记录组成的序列。之后给出的是BikeStock.BikeStock类,该类用于存放一组BikeStock.Bike对象(以记录的形式存放在BinaryRecordFile.BinaryRecordFile中),通过该类可以了解二进制随机存取文件的使用。
7.4.1 通用的BinaryRecordFile类
BinaryRecordFile.BinaryRecordFile类的API类似于列表,因为我们可以获取/设置/删除给定的索引位置处的记录。记录被删除后,只是简单地标记为“已删除”,这使得我们不必移动该记录后面的所有记录来保证连续性,也意味着删除操作之后,所有原始的索引位置仍然是有效的。另一个好处是只要取消“已删除”标记,就可以反删除一条记录。当然,这种方法即便删除了记录,也仍然不能节省任何磁盘空间。为解决这一问题,我们将提供适当的方法来“压缩”文件,移除已删除的记录(并使得该索引位置无效)。
在讲述其具体实现之前,我们先看一些基本的使用方法。
Contact = struct.Struct("<15si")
contacts = BinaryRecordFile.BinaryRecordFile(filename, Contact.size)
这里,我们创建了一个结构(little-endian字节顺序,一个15字节的字节字符串,一个4字节的有符号整数),用于表示每条记录。之后创建了一个BinaryRecordFile. BinaryRecordFile实例,并使用一个文件名和一个记录大小做参数,以便匹配当前正在使用的结构。如果该文件存在,就将打开该文件(并保证其内容不被改变),否则创建一个文件——无论哪种情况,都将以二进制读/写模式打开文件。
contacts[4] = Contact.pack("Abe Baker".encode("utf8"), 762)
contacts[5] = Contact.pack("Cindy Dove".encode("utf8"), 987)
我们可以将文件当作一个列表,并使用项存取操作符[]对其进行操作,这里,我们对该文件的两个索引位置处进行了赋值操作,赋值为字节字符串(bytes对象,每个包含一个编码的字符串与一个整数),这两个赋值操作将重写任何现存的内容,如果文件尚未包含6条记录,那么前面索引位置处的记录将被创建,并且其中每个字节设置为0x00。
contact_data = Contact.unpack(contacts[5])
contact_data[0].decode("utf8").rstrip(chr(0)) # returns: 'Cindy Dove'
由于字符串“Cindy Dove”在长度上小于结构中15个UTF-8字符的约束,因此,在对其打包时,会在后面填充一些0x00字节。因此,取回该记录时,contact_data中存放的是一个二元组(b'Cindy Dove\x00\x00\x00\x00\x00', 987)。为获取名称,我们必须对UTF-8字符进行解码,以便产生一个Unicode字符串,并剥离其中的填充字节0x00。
在大概了解了该类的一些使用之后,现在来查看该类的实现代码。BinaryRecordFile.BinaryRecordFile类实现于文件BinaryRecordFile.py中,在通常的一些预备内容之后,该文件从一对私有字节值的定义开始:
_DELETED = b"\x01"
_OKAY = b"\x02"
每条记录都以一个“state”字节引导,该字节或者是_DELETED,或者是_OKAY(如果是空记录,就是b"\x00")。
下面给出其class行及初始化程序:
class BinaryRecordFile:
def __init__(self, filename, record_size, auto_flush=True):
self.__record_size = record_size + 1
mode = "w+b" if not os.path.exists(filename) else "r+b"
self.__fh = open(filename, mode)
self.auto_flush = auto_flush
有两个不同的记录大小,BinaryRecordFile.record_size是由用户设定的,是从用户角度看到的记录大小;私有的BinaryRecordFile.__record_size是内部实际的记录大小,包含状态字节。
打开文件时,要注意不要截取该文件。因此,如果文件已存在,就应该使用“r+b”模式;如果文件不存在,就应该使用“w+b”模式创建——这里,模式字符串的“+”部分表示的是读与写。如果布尔型值BinaryRecordFile.auto_flush为True,就在每次读之前与写之后都将其清空。
@property
def record_size(self):
return self.__record_size - 1
@property
def name(self):
return self.__fh.name
def flush(self):
self.__fh.flush()
def close(self):
self.__fh.close()
我们将记录大小与文件名设置为只读的特性。我们向用户报告的记录大小是用户请求的,并可以与其记录匹配。flush方法与close方法则是简单地对文件对象进行相应处理。
def __setitem__(self, index, record):
assert isinstance(record, (bytes, bytearray)), \
"binary data required"
assert len(record) == self.record_size, (
"record must be exactly {0} bytes".format(
self.record_size))
self.__fh.seek(index * self.__record_size)
self.__fh.write(_OKAY)
self.__fh.write(record)
if self.auto_flush:
self.__fh.flush()
这一方法支持语法格式brf[i] = data,其中,brf是一个二进制记录文件,i是一个记录索引位置,data是一个字节字符串。注意,记录必须与创建二进制记录文件时指定的大小相同。如果参数正确,就将文件指针移动到记录的第一个字节处——这里使用的是实际记录大小,也就是包含了状态字节。默认情况下,seek()方法可以将文件指针移动到字节的绝对位置,也可以给定另一个参数,使得文件指针移动到相对于当前位置或结果位置有多远的索引位置处(文件对象提供的属性与方法在表7-4与表7-5中列出。)




由于项正在被设置,显然没有被删除,因此,我们写入状态字节_OKAY,之后写入用户的二进制记录数据,二进制记录文件不知道也不关心正在使用的记录结构,而只要求记录大小是正确的。
我们没有检测索引值是否在有效取值范围之内。如果索引值超出了文件末尾,那么记录将被写入到正确的索引位置,并且在文件末尾与新记录之间的每个字节被设置为b"\x00",这样的空白记录既不是_OKAY,也不是_DELETED,因此,在需要的时候可以区分出来。
def __getitem__(self, index):
self.__seek_to_index(index)
state = self.__fh.read(1)
if state != _OKAY:
return None
return self.__fh.read(self.record_size)
取回记录时,需要考虑4种情况:记录不存在,也就是说,给定的索引位置超出了范围;记录是空的;记录已删除;记录状态为okay。记录不存在,私有的__seek_to_ index()方法将产生IndexError异常,否则,该方法将寻找该记录的引导字节,之后我们读入状态字节。如果状态不是_OKAY,那么记录必须为空或已删除,这两种情况将返回None;否则,我们将读入并返回该记录。(另一种策略是,对空记录或已删除记录,产生自定义异常,比如BlankRecordError或DeletedRecordError,而不是返回None。)
def __seek_to_index(self, index):
if self.auto_flush:
self.__fh.flush()
self.__fh.seek(0, os.SEEK_END)
end = self.__fh.tell()
offset = index * self.__record_size
if offset >= end:
raise IndexError("no record at index position {0}".format(
index))
self.__fh.seek(offset)
这是一个私有的支持方法,其他一些方法会使用本方法将文件位置指针移动到记录的首字节(从给定的索引位置)。我们从检测给定的索引位置是否在取值范围之内开始,为此,我们定位到文件结尾处(到文件结尾的字节偏移量为0),并使用tell()方法取回我们已定位到的字节位置。如果记录的偏移量在结尾处或超过结尾处,就说明索引位置已超出范围,此时应该产生适当的异常。否则,我们就定位到索引偏移位置,并做好下一次读写的准备。
def __delitem__(self, index):
self.__seek_to_index(index)
state = self.__fh.read(1)
if state != _OKAY:
return
self.__fh.seek(index * self.__record_size)
self.__fh.write(_DELETED)
if self.auto_flush:
self.__fh.flush()
首先,我们将文件位置指针移动到合适的位置,如果索引位置在取值范围之内(也就是说,没有产生IndexError异常),并且假定记录不是空白的或已删除的,我们就删除该记录,这是通过将其状态重写为_DELETED来实现的。
def undelete(self, index):
self.__seek_to_index(index)
state = self.__fh.read(1)
if state == _DELETED:
self.__fh.seek(index * self.__record_size)
self.__fh.write(_OKAY)
if self.auto_flush:
self.__fh.flush()
return True
return False
该方法首先找到记录并读取其状态字节,如果记录已删除,就使用_OKAY重写其状态字节,并向调用者返回True,以表明操作成功,否则(对空白记录或未删除的记录),返回False。
def __len__(self):
if self.auto_flush:
self.__fh.flush()
self.__fh.seek(0, os.SEEK_END)
end = self.__fh.tell()
return end // self.__record_size
这一方法将报告二进制记录文件中包含了多少条记录,这是通过用结尾字节位置(也即文件中包含多少个字节)与记录大小相除得到的。
至此,我们讲述了BinaryRecordFile.BinaryRecordFile类提供的所有基本功能,但还有一个需要考虑的功能:压缩文件,以便删除其中空白记录与已删除记录。为此,有两种方法。一种方法是使用索引位置更大的记录重写空白记录或已删除记录,以便记录之间没有缝隙,并对文件进行截取(如果结尾处有任意的空白行或删除的记录),inplace_compact()方法用于完成这一功能。另一种方法是将非空白且未删除的记录复制到一个临时文件中,之后将临时文件重命名为原始的文件名。如果正好需要进行备份,那么使用临时文件是一种非常便利的方法,compact()方法用于实现这一功能。
我们分两个部分来查看inplace_compact()方法:
def inplace_compact(self):
index = 0
length = len(self)
while index < length:
self.__seek_to_index(index)
state = self.__fh.read(1)
if state != _OKAY:
for next in range(index + 1, length):
self.__seek_to_index(next)
state = self.__fh.read(1)
if state == _OKAY:
self[index] = self[next]
del self[next]
break
else:
break
index += 1
我们对每条记录进行迭代,依次读入每条记录的状态。如果发现了空白记录或已删除记录,则继续寻找文件中下一条非空白且未删除的记录,找到后,就使用该条非空白且未删除的记录替换空白记录或已删除记录,并删除原始的非空白且未删除的记录;如果一直未找到,就跳出整个while循环,因为我们已经处理完了非空白且未删除的记录。
self.__seek_to_index(0)
state = self.__fh.read(1)
if state != _OKAY:
self.__fh.truncate(0)
else:
limit = None
for index in range(len(self) - 1, 0, -1):
self.__seek_to_index(index)
state = self.__fh.read(1)
if state != _OKAY:
limit = index
else:
break
if limit is not None:
self.__fh.truncate(limit * self.__record_size)
self.__fh.flush()
如果第一条记录就是空白记录或已删除记录,那么所有记录必然都是空白记录或已删除记录,因为前面的代码已经将所有非空白且未删除的记录移动到文件起始处,并将空白记录或已删除记录移动到文件末尾处。对这种情况,我们可以简单地将文件截取为0字节。
如果至少有一条非空白且未删除的记录,那么我们就沿着从最后一条记录到第一条记录的方向进行迭代,因为我们知道,空白记录或已删除记录已经被移动到文件结尾处。变量limit被设置为最靠前的空白记录或已删除记录(如果没有这样的记录,就将其设置为None),并对文件进行相应的截取。
另一种实现压缩的替代方案是将其复制到另外的文件中——如果我们正好需要进行备份,那么这种方法是有用的,接下来我们要查看的compact()方法展示了这种做法。
def compact(self, keep_backup=False):
compactfile = self.__fh.name + ".$$$"
backupfile = self.__fh.name + ".bak"
self.__fh.flush()
self.__fh.seek(0)
fh = open(compactfile, "wb")
while True:
data = self.__fh.read(self.__record_size)
if not data:
break
if data[:1] == _OKAY:
fh.write(data)
fh.close()
self.__fh.close()
os.rename(self.__fh.name, backupfile)
os.rename(compactfile, self.__fh.name)
if not keep_backup:
os.remove(backupfile)
self.__fh = open(self.__fh.name, "r+b")
这一方法创建两个文件,一个压缩后文件,一个原始文件的备份文件。压缩后文件与原始文件名称相同,但名称最后附加了.$$$,类似地,备份文件与原始文件名称相同,但名称最后附加了.bak。我们逐个记录读入现有的文件,对那些非空白且未删除的记录,就将其写入到压缩后文件中。(注意,我们写入的是真实的记录,也即每次都写入状态字节与用户记录。)
if data[:1] == _OKAY:这行代码是相当微妙的。Data对象与_OKAY对象都是bytes类型,该行代码中,我们需要将data对象的首字节与(1字节的)_OKAY对象进行比较,如果我们提取bytes对象的分片,就获取了一个bytes对象;如果我们提取一个单独的字节,比如data[0],获取的则是一个整数——字节的值。
因此,这里我们将data的一个字节的分片(其首字节,也即状态字节)与一个字节的对象_OKAY进行比较。(另一种实现方式是使用代码if data[0] == _OKAY[0],该代码将对两个int值进行比较。)
最后,我们将原始文件重命名为备份文件,将压缩后文件重命名为原始文件。之后,如果keep_backup为False(默认情况),就移除备份文件。最后,我们打开压缩后文件(现在该文件与原始文件名称一致),以备进一步的读写。
BinaryRecordFile.BinaryRecordFile类是底层的,但可以作为高层类的基础,这些高层类需要对由固定大小记录组成的文件进行随机存取,下一小节将对其进行展示。
7.4.2 实例:BikeStock模块的类
BikeStock模块使用BinaryRecordFile.BinaryRecordFile来提供一个简单的仓库控制类,仓库项为自行车,每个由一个BikeStock.Bike实例表示,整个仓库的自行车则存放在一个BikeStock.BikeStock实例中。BikeStock.BikeStock类将字典(其键为自行车ID,值为记录索引位置)整合到BinaryRecordFile.BinaryRecordFile中,下面给出一个简短的实例,有助于了解这些类的工作方式:
bicycles = BikeStock.BikeStock(bike_file)
value = 0.0
for bike in bicycles:
value += bike.value
bicycles.increase_stock("GEKKO", 2)
for bike in bicycles:
if bike.identity.startswith("B4U"):
if not bicycles.increase_stock(bike.identity, 1):
print("stock movement failed for", bike.identity)
上面的代码段打开一个自行车仓库文件,并对其中所有自行车记录进行迭代,以便计算其中存放的自行车的总体价值(价格乘以数量)。之后递增仓库中“GEKKO”自行车的数量(以2为递增值)与存放所有自行车ID以“B4U”开始的自行车的仓库(以1为递增值)。所有这些操作都在磁盘上进行,因此,读取字形成仓库文件的任意其他进程总是可以获取最新数据。
BinaryRecordFile.BinaryRecordFile根据索引进行工作,BikeStock.BikeStock类根据自行车ID进行工作,这是由BikeStock.BikeStock实例(其中存放一个字典,该字典将自行车ID与索引进行关联)进行管理的。
我们首先查看BikeStock.Bike类的class行与初始化程序,之后查看其中选定的几个BikeStock.BikeStock方法,最后将查看用于在BikeStock.Bike对象与二进制记录(用于在BinaryRecordFile.BinaryRecordFile中对其进行表示)提供桥梁的代码。(所有代码都在BikeStock.py文件中。)
class Bike:
def __init__(self, identity, name, quantity, price):
assert len(identity) > 3, ("invalid bike identity '{0}'"
.format(identity))
self.__identity = identity
self.name = name
self.quantity = quantity
self.price = price
自行车的所有属性都是以特性形式存在的——自行车ID(self.__identity)是一个只读的Bike.identity特性,其他属性则是读/写特性,并使用断言进行有效性验证。此外,只读特性Bike.value返回的是数量与价格的乘积。(我们没有展示该特性的实现,因为前面看到过类似的代码。)
BikeStock.BikeStock类提供了自己的用于操纵自行车对象的方法,并依次使用可写的自行车特性。
class BikeStock:
def __init__(self, filename):
self.__file = BinaryRecordFile.BinaryRecordFile(filename,
_BIKE_STRUCT.size)
self.__index_from_identity = {}
for index in range(len(self.__file)):
record = self.__file[index]
if record is not None:
bike = _bike_from_record(record)
self.__index_from_identity[bike.identity] = index
BikeStock.BikeStock类是一个自定义组合类,其中聚集了一个二进制记录文件(elf.__file)与一个字典(self.__index_from_identity),该字典的键是自行车ID,值为记录索引位置。
文件打开(如果不存在就创建)后,我们对其内容(如果存在)进行迭代。每个自行车都被取回,并使用私有的_bike_from_record()函数将其从bytes对象转换为BikeStock.Bike,自行车的identity与索引位置则添加到self.__index_from_identity字典中。
def append(self, bike):
index = len(self.__file)
self.__file[index] = _record_from_bike(bike)
self.__index_from_identity[bike.identity] = index
如果需要向其中添加一台自行车,实际上所做的工作就是找到适当的索引位置,并将该索引位置处的记录设置为自行车的二进制表象形式。此外,我们还需要更新self.__index_from_identity字典。
def __delitem__(self, identity):
del self.__file[self.__index_from_identity[identity]]
删除一条自行车记录是容易的,我们只需要找到该记录的索引位置,并删除该索引位置处的记录。在Bike-Stock.BikeStock类中,我们没有使用BinaryRecordFile.Binary-RecordFile的反删除功能。
def __getitem__(self, identity):
record = self.__file[self.__index_from_identity[identity]]
return None if record is None else _bike_from_record(record)
自行车记录可以通过自行车ID取回,如果没有要寻找的ID,那么在self.__index_from_identity字典中的搜索将产生KeyError异常。如果记录为空白记录或已删除记录,那么BinaryRecordFile.BinaryRecordFile将返回None;如果可以成功取回记录,就将其返回为一个BikeStock.Bike对象。
def __change_stock(self, identity, amount):
index = self.__index_from_identity[identity]
record = self.__file[index]
if record is None:
return False
bike = _bike_from_record(record)
bike.quantity += amount
self.__file[index] = _record_from_bike(bike)
return True
increase_stock = (lambda self, identity, amount:
self.__change_stock(identity, amount))
decrease_stock = (lambda self, identity, amount:
self.__change_stock(identity, -amount))
私有方法__change_stock()提供了increase_stock()方法与decrease_stock() 方法的实现。首先找到自行车的索引位置,并取回该记录,之后将数据转换为一个BikeStock.Bike对象。相应的变化作用于自行车,之后,使用更新后自行车对象的二进制表示形式重写文件中的原记录(还有一个__change_bike()方法,提供了对change_name()方法与change_price()方法的实现,但这里没有展示,因为与我们这里展示的非常类似)。
def __iter__(self):
for index in range(len(self.__file)):
record = self.__file[index]
if record is not None:
yield _bike_from_record(record)
这一方法确保可以对BikeStock.BikeStock对象进行迭代,就像对列表一样,每次迭代返回一个BikeStock.Bike对象,并跳过空白记录与已删除记录。
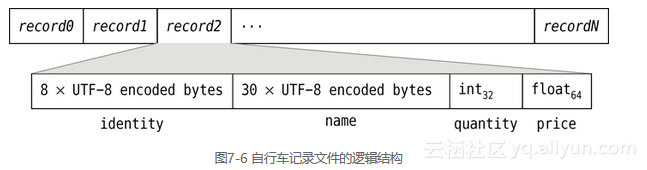
私有函数_bike_from_record()与record_from_bike()将BikeStock.Bike类的二进制表示从BikeStock.BikeStock类(存放一组自行车)中隔离出来。图7-6展示了自行车记录文件的逻辑结构,物理结构稍有差别,因为每条记录都是由一个状态字节引导的。
_BIKE_STRUCT = struct.Struct("<8s30sid")
def _bike_from_record(record):
ID, NAME, QUANTITY, PRICE = range(4)
parts = list(_BIKE_STRUCT.unpack(record))
parts[ID] = parts[ID].decode("utf8").rstrip("\x00")
parts[NAME] = parts[NAME].decode("utf8").rstrip("\x00")
return Bike(*parts)
def _record_from_bike(bike):
return _BIKE_STRUCT.pack(bike.identity.encode("utf8"),
bike.name.encode("utf8"),
bike.quantity, bike.price)
在将二进制记录转换为BikeStock.Bike时,我们首先将unpack()返回的元组转换为列表。这允许我们对元素进行修改,这里是将UTF-8编码的字节转换为字符串,并剥离其中的填充字节0x00。之后,我们使用序列拆分操作符(*)将相应部分提供给BikeStock.Bike 初始化程序。打包数据更简单,我们只是必须确保将字符串编码为UTF-8字节。
对现代的桌面系统而言,随着RAM大小与磁盘速度的增长,应用程序对随机存取二进制数据的需求降低了。需要这样的功能时,通常最简单的方法是使用DBM文件或SQL数据库。尽管如此,这里展示的技术对有些系统仍然是有用的,比如,嵌入式系统或其他资源受限型的系统。