![]()
Express 作为 Node.js
的框架,如今发展可谓如日中天。我很喜欢其灵活、易扩展的设计理念。尤其是该框架的中间件架构设计:使得在应用中加入新特性更加标准化、成本最小化。这篇文章,我会尝试编写一个非常简单、小巧的中间件,完成服务端缓存功能,进而优化性能。
关于中间件
说到中间件,Express 官网对它的阐述是这样的:
“Express 是一个自身功能极简,完全是路由和中间件构成一个web开发框架:从本质上来说,一个 Express 应用就是在调用各种中间件。”
也许你使用过各种各样的中间件进行开发,但是可能并不理解中间件原理,也没有深入过 Express 源码,探究其实现。这里并不打算长篇大论帮您分析,但是使用层面上大致可以参考下图:
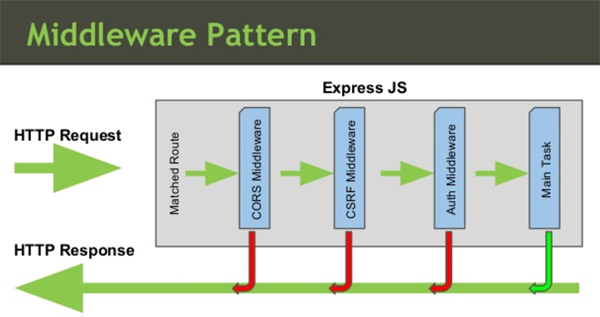
建议有兴趣、想深入的读者自己分析,有任何问题欢迎与我讨论。即便您不打算深入,也不会影响对下文中间件编写的理解。
关于服务端缓存
缓存已经被广泛应用,来提高页面性能。一说到缓存,可能读者脑海里马上冒出来:“客户端缓存,CDN 缓存,服务器端缓存......”。另一维度上,也会想到:“200(from cache),expire,eTag......”等概念。
当然作为前端开发者,我们一定要明白这些缓存概念,这些缓存理念是相对于某个具体用户访问来说的,性能优化体现在单个用户上。比如说,我第一次打开页面 A,耗时超长,下一次打开页面由于缓存的作用,时间缩短了。
但是在服务器端,还存在另外一个维度,思考一下这样的场景:
我们有一个静态页面 B,这个页面服务端需要从数据库获取部分数据 b1,根据 b1 又要计算得到部分数据 b2,还得做各种高复杂度操作,最终才能“东拼西凑”出需要返回的完整页面 B,整个过程耗时2s。
那么面临的灾难就是,user1 打开页面耗时2s,user2同样打开页面耗时2s......而这些页面都是静态页面 B,内容是完全一样的。为了解决这个灾难,这时候我们也需要缓存,这种缓存就叫先做服务端缓存(server-side cache)。
总结一下,服务端缓存的目的其实就是对于同一个页面请求,而返回(缓存的)同样的页面内容。这个过程完全独立于不同的用户。
上面的话有些拗口,可以参考英文表达更清晰:
The goal of server side cache is responding to the same content for the same request independently of the client’s request.
因此,下面展示的 demo 在第一次请求到达时,服务端耗费5秒来返回 HTML;而接下来再次请求该页面,将会命中缓存,不过是哪个用户访问,只需要几毫秒便可得到完整页面。
Show me the code & Demo
其实上文提到的缓存概念非常简单,稍微有些后端经验的同学都能很好理解。但是这篇文章除去科普基本概念外,更重要的就是介绍 Express 中间件思想,并自己来实现一个服务端缓存中间件。
让我们开工吧!
最终 Demo 代码,欢迎访问它的Github地址。
我将会使用 npm 上 memory-cache 这个包,以方便进行缓存的读写。最终的中间件代码很简单:
- 'use strict'
- var mcache = require('memory-cache');
- var cache = (duration) => {
- return (req, res, next) => {
- let key = '__express__' + req.originalUrl || req.url
- let cachedBody = mcache.get(key)
- if (cachedBody) {
- res.send(cachedBody)
- return
- } else {
- res.sendResponse = res.send
- res.send = (body) => {
- mcache.put(key, body, duration * 1000);
- res.sendResponse(body)
- }
- next()
- }
- }
- }
为了简单,我使用了请求 URL 作为 cache 的 key:
- 当它(cache key)及其对应的 value 值存在时,便直接返回其 value 值;
- 当它(cache key)及其对应的 value 值不存在时,我们将对 Express send 方法做一层拦截:在最终返回前,存入这对 key-value。
缓存的有效时间是10秒。
最终在判断之外,我们的中间件把控制权交给下一个中间件。
最终使用和测试如下代码:
- app.get('/', cache(10), (req, res) => {
- setTimeout(() => {
- res.render('index', { title: 'Hey', message: 'Hello there', date: new Date()})
- }, 5000) //setTimeout was used to simulate a slow processing request
- })
我使用了 setTimeout 来模拟一个超长(5s)的操作。
打开浏览器控制面板,发现在10秒缓存到期以内:
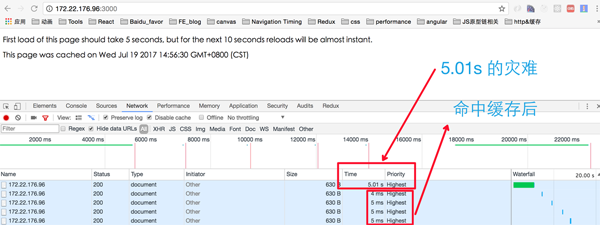
至于为什么 cache 中间件要那样子写、next() 为什么是中间件把控制权传递,我并不打算展开去讲。有兴趣的读者可以看一下 Express 源码。
还有几个小问题
仔细看我们的页面,再去体会一下实现代码。也许细心的读者能发现一个问题:刚才的实现我们缓存了整个页面,并将 date: new Date()
传入了 jade 模版 index.jade 里。那么,在命中缓存的条件下,10秒内,页面无法动态刷新来同步,直到10秒缓存到期。
同时,我们什么时候可以使用上述中间件,进行服务端缓存呢?当然是静态内容才可以使用。同时,PUT, DELETE 和 POST 操作都不应该进行类似的缓存处理。
同样,我们使用了 npm 模块:memory-cache,它存在优缺点如下:
- 读写迅速而简单,不需要其他依赖;
- 当服务器或者这个进程挂掉的时候,缓存中的内容将会全部丢失。
- memcache 是将缓存内容存放在了自己进程的内存中,所以这部分内容是无法在多个 Node.js 进程之间共享的。
如果这些弊端 really matter,在实际开发中我们可以选择分布式的 cache 服务,比如 Redis。同样你可以在 npm 上找到:express-redis-cache 模块使用。
总结
在真实的开发场景中,服务端缓存已经成为 common sense,但是在 Node.js 的世界里,体会其中间件思想,自己手动编写服务,同样乐趣无穷。
与实践相结合,我认为真正缓存整个页面(如同 demo 那样)并不是一个推荐的做法(当时实际场景实际分析),同样使用请求 url 作为缓存的 key 也有待考虑。比如,页面中的一些静态内容可能会在其他页面中重复使用到,复用就成了问题。
作者:lucas_580e331d326b4
来源:51CTO