概述
异常处理,是编程语言或计算机硬件里的一种机制,用于处理软件或信息系统中出现的异常状况(即超出程序正常执行流程的某些特殊条件)。Python和R作为一门编程语言自然也是有各自的异常处理机制的,异常处理机制在代码编写中扮演着非常关键的角色,却又是许多人容易混淆的地方。对于异常机制的合理运用是直接关系到码农饭碗的事情!所以,本文将具体介绍一下Python和R的异常处理机制,阐明二者在异常处理机制上的异同。
异常安全
在了解Python和R的异常机制之前,我们有必要了解一下异常安全的概念。
根据WikiPedia的文献,一段代码是异常安全的,如果这段代码运行时的失败不会产生有害后果,如内存泄露、存储数据混淆、或无效的输出。我们可以知道一段代码的异常安全通常分为下面五类:
异常安全通常分为5个层次:
- 失败透明:如果出现了异常,将不会对外进一步抛出该异常。(一般比较复杂)
- 强异常安全:可以运行失败,不过数据会回滚到代码运行前(无副作用)
- 基本异常安全:运行失败导致的数据变更,使得代码运行前后数据不一致了(有副作用)
- 最小异常安全:运行失败保存了无效数据,但是还不会引起崩溃,资源不会泄露(进程不会挂)
- 异常不安全:没有任何保证(进程可能会挂掉)
从上述的5个层次来看,我们可以知道,在平时写代码的时候,对数据库、文件、网络等的IO操作都是需要尽量保证无副作用的,也就是强异常安全。具体来说就是,RDBS操作在失败的时候需要回滚机制、所有IO操作在最后要保证IO连接资源关闭。
其实和多数语言的异常机制的语法是类似的:Python和R都是通过抛出一个异常对象或一个枚举类的值来返回一个异常;异常处理代码的作用域由try开始,以第一个异常处理子句(catch,
except等)结束;可连续出现若干个异常处理子句,每个处理特定类型的异常。最后通过finally子句,无论是否出现异常它都将执行,用于释放异常处理所需的一些资源。
下面将具体介绍二者的异常处理机制。
Python 中的异常处理机制
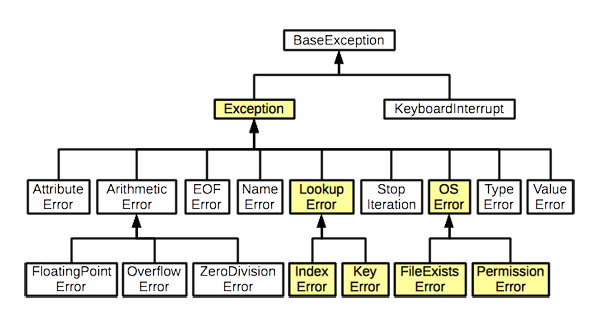
首先,Python 是一门面向对象语言,所有的异常类都是通过继承BaseException类来实现的,我们亦可以通过相应的继承来实现自定义的异常类,比如在工作流调度中使用AirflowException,具体实现可以直接看Airflow的源码。
事实上,这些在我们代码处理范围内的异常其实就是可以分成两个部分:
- IO异常:由网络抖动、磁盘文件位置变更、数据库连接变更等引起的IO异常问题。
- 运行期异常:由于计算或者传输的参数参数类型有误、参数值异常等等发生在运行期的异常,都统一被称为运行期异常。正常来说,IO上的异常我们都要有相应的try-catch-finally机制,在Python也就是如下实现:
- try:
- do something with IO
- except:
- do something without IO
- finally:
- close IO
这里容易犯的一个错误就是在except中又引入了新的IO操作,比如在except中又引入了一个API的POST请求或者数据库写操作等等,这样如果在except阶段又发生了异常,将导致异常信息的丢失。
另一方面,对于可能的运行期异常则需要我们根据具体应用场景的需求来做相应的处理,一般就是遇到一个新的问题加一个新的异常捕获机制,当然这里也就考验到码农程序设计的功利,是否能够未雨绸缪。比如数组长度的检查,传入字典的Key检查等等。Python本身提供了丰富的异常处理类型并且易于拓展,正确使用将可以显著提升程序的鲁棒性(保住码农的饭碗)。
使用try-catch-finally机制是足够简单的,但是在混入return和rasie操作之后,事情就看起来变得有点复杂。
举一个例子:
- def test():
- try:
- a = 1/0
- except:
- a = 0
- raise(ValueError,"value error, the division must greater than 0")
- return a
- finally:
- a = 1
- return a
- test()
你看这里的返回应该是什么呢?
其实,这里的返回最后应该是 1,而except中raise的异常则会被吃掉。这也是许多人错误使用finanlly的一个很好的例子。
Python在执行带有fianlly的子句时会将except内抛出的对象先缓存起来,优先执行finally中抛出的对象,如果finally中先抛出了return或者raise,那么except段抛出的对象将看起来被吃掉了。
一个段正确的处理方式应该是这样的:
- try:
- do IO
- info = {"status":200}
- except:
- info = {"status":400}
- finally:
- try:
- write log(info)
- except:
- raise(SomeError,"error message")
- close IO
具体的调用栈的过程可以参考这个更加生动的例子:
R 中的异常处理机制
R和Python最大的不同就是 R 本质上是一门强动态类型的非纯函数式编程语言(所谓非纯即存在副作用)而非面向对象语言。从函数式编程语言的角度上讲,R和Erlang、LISP的关系比较近一些。
既然是函数式语言,处理异常也是通过函数式的,而非直接通过面向对象的方式。R 从语法上来看就略显突兀(花括号函数式语言的一大通病):
- tryCatch({
- doStuff()
- doMoreStuff()
- }, some_exception = function(se) {
- recover(se)
- })
如果这段用Python来表达就变成:
- try:
- doStuff()
- doMoreStuff()
- except SomeException, se:
- recover(se)
事实上正确运用 R 的异常处理机制反而是比较负担小的一种方式:(R 还支持用中文字符集命名变量)
- tryCatch({
- 结果 <- 表达式
- }, warning = function(w) {
- warning()
- ... # 运行期异常
- }, error = function(e) {
- stop()
- ... # IO异常
- }, finally {
- on.exit()
- ... # 资源回收
- }
下面是 Hadley 大神对R的异常处理机制优点的分析:
One of R’s great features is its condition system. It serves a
similar purpose to the exception handling systems in Java, Python, and
C++ but is more flexible. In fact, its flexibility extends beyond error
handling–conditions are more general than exceptions in that a
condition can represent any occurrence during a program’s execution
that may be of interest to code at different levels on the call stack.
For example, in the section “Other Uses for Conditions,” you’ll see
that conditions can be used to emit warnings without disrupting
execution of the code that emits the warning while allowing code higher
on the call stack to control whether the warning message is printed.
For the time being, however, I’ll focus on error handling.
The condition system is more flexible than exception systems because
instead of providing a two-part division between the code that signals
an error and the code that handles it, the condition system splits the
responsibilities into three parts–signaling a condition, handling it,
and restarting. In this chapter, I’ll describe how you could use
conditions in part of a hypothetical application for analyzing log
files. You’ll see how you could use the condition system to allow a
low-level function to detect a problem while parsing a log file and
signal an error, to allow mid-level code to provide several possible
ways of recovering from such an error, and to allow code at the highest
level of the application to define a policy for choosing which
recovery strategy to use.
我的理解是R通过条件机制,然我们可以选择性的在低阶函数中把warning吃掉,这样就不至于影响高阶函数的运行?条件机制将异常分为三阶段而不是两阶段:
- 异常信号捕获
- 异常处理
- 重启机制。
并且我们还可以看到在异常处理中,如何在中阶函数中恢复低阶函数的Error,并且在高阶函数中选择一定的恢复策略。
这段貌似个人理解有误,还请看官指正。
作者:HarryZhu
来源:51CTO