第9章 9.1 误差建模原理
著名机器学习专家,卡内基梅隆大学的 TomMitchell 教授曾经用三个要素定义了机器学习的基本概念1[1] ——基于经验 E,针对学习目标 T,提升表现度量 P。经验是学习的信息来源,代表了预先获取并输入机器学习算法的训练数据或信号观测。如对于有监督学习问题,经验体现为数据及其标记构成的有标记数据集合;而对于无监督学习问题,经验就仅体现为数据本身构成的无标记数据集。学习目标是学习的最终任务,体现为机器学习方法预期获得的最终输出结果。如对于判别问题,学习目标为对未知数据能够执行判别的决策函数;对于信号复原问题,学习目标为对输入信号进行恢复的信号等。
表现度量是学习的实现手段,对应于一个衡量学习效果满意程度的量化标准。通过将表现度量作为优化问题的目标函数并设计优化算法对其进行求解,机器学习的任务得以实现。如何构造机器学习的表现度量,或者说如何对机器学习的优化问题进行建模,是对给定数据与特定学习目标进行有效机器学习的核心问题。通常采用如下模型来实现这一目的: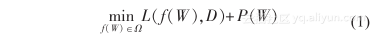
该模型中,D代表了训练数据;f(W)代表了学习目标;W 代表了模型参数。模型中主要包含三个因素,其物理意义分别如下:L(f(W),D) 为误差函数,代表了学习目标对训练数据的拟合精度,最常见的形式包括最小二乘误差(即 L 2 范数误差)与稳健误差(如L 1 范数误差等)等;P(W) 为正则项,编码了模型参数的先验信息,常采用的形式包括 ridge 正则(即L 2 范数正则)或稀疏正则(如 L 1 范数正则等);Ω称为学习机,代表了一个预先设置的学习目标可行集,其功能为对学习目标的学习范围进行约束。机器学习首先要关注的问题,当然是学习目标对训练数据的有效拟合。这一目标又可称为经验风险极小化原理 (empirical risk minimization) [2] 。
具体来说,就是如何针对输入数据 D,使在经验数据上的误差,L(f(W),D) 尽可能小的问题。神经网络是基于这一原理实现的典型机器学习方法,其跌宕起伏的发展历程,几乎可以概括为一部“成也拟合,败也拟合”的历史。最早期由 Rosenblatt 提出的感知机概念[3-4] ,事实上对应于一个包含简单加减法的两层神经网络。尽管在字母识别等应用中体现了一定的应用效果,但其拟合能力有限的问题很快受到其他学者的质疑。特别是,在 1969 年著名科学家Minsky 与 Papert 关于感知机的著作中[5] ,证明了感知机甚至无法对经典异或问题进行有效拟合。此问题导致之后十多年的时间,神经网络的研究几乎停滞不前。其再一次复兴的标志成果为 1975 年出现的后向传播算法[6] 。该算法解决了神经网络对异或回路的拟合学习问题,并实现了多层神经网络的有效训练策略。由于理论可以证明,多层网络具有对广泛函数的万有逼近(universal approximation)性能[7] ,机器学习对于数据的拟合问题似乎得以很好的解决,这也带来了神经网络在上世纪八九十年代的又一次研究热潮。然而,学者们很快发现,片面地追求在训练数据上的拟合精度往往也是有问题的。当采用形态较为复杂的学习目标对学习任务进行训练时,在训练数据上拟合精度可能很高;然而当对未包含在训练数据中的测试数据进行预测时,精度却可能较差,特别在训练数据的数目相对较少的情况下(即小样本问题),这一问题尤为突出。这一现象,被称之为机器学习的过拟合问题
。其背后的哲学原理称为“奥卡姆剃刀原理”(Occam's Razor [8] ),其含义为“如无必要,勿增实体”,即简单有效原则。换句话说,在保证拟合精度的前提下,我们更加预期形式简单的学习目标。从学习理论的角度理解,机器学习的目的不仅关注于学习结果对于训练数据的“ 逼 近 能 力”(approximation capability), 更 加 要强调所获学习目标对未来数据进行预测的“泛化能力”(generalization capability)。过度复杂的学习目标(如一个深层全连接的前向神经网)也许会使学习对训练数据实现精确拟合,这种过度的拟合忽略了训练数据中蕴含的噪音扰动与结构缺失,从而导致其无法对体现数据一般规律的测试数据进行有效拟合;而蕴含了数据本质结构的简单学习目标,尽管使学习对训练数据的逼近能力减弱,却可能使获得的学习目标减弱了噪音的干扰,增强了对数据结构的刻画功能,从而具有更好的泛化能力。因此,设置合适的正则项与学习机对学习目标的复杂度进行限制,就成为机器学习十分重要的研究内容。
对于机器学习的建模原理,也由经验风险极小化原理,进化为结构风险极小化原理 (StructuralRisk Minimization) [2] 。即,不仅要在机器学习模型中考虑对训练数据的拟合精度,同时要对学习目标结构进行约束和控制,使其在保证拟合精度的前提下,尽可能具有简单的形式。对于学习目标结构的控制,可以通过在机器学习模型 (1) 中加入模型参数正则项或者设计学习机结构的方式来实现。基于这一原理设计的最为典型的机器学习方法,是由Vladimir Vapnik 教授提出的支撑向量机[9] 。该方法采用分类最大间隔 (maximum margin) 构造了模型参数的正则项,并发展了完善的统计学习理论,证明了该正则项有益于机器学习泛化能力的增强。在这一阶段 ( 大约为上世纪 90 年代后期与本世纪前 10年的时间 ),以使用简单学习目标结构的支撑向量机为代表的学习策略成为了机器学习的主流,神经网络研究的热度又一次开始跌落。近年来,关于如何针对特定应用问题和数据结构类型,将领域知识嵌入机器学习模型的学习目标结构,逐渐成为非常热点的研究方向。
一个典型的例子为 L 2,1 组稀疏正则[10] ,其功能为将数据的领域聚类结构信息嵌入数据变量稀疏性的编码之中。事实上,近十年来深度神经网络掀起的又一股机器学习的热潮,从一定意义上也许仍然是此类领域正则的体现。其良好性能的来源也许并不完全在于其远比传统神经网络更大、更深的网络结构,而也很可能是由于其基于 Imagenet 等性态良好、结构丰富的大规模数据集进行预训练后的初值准备(待迁移的先验知识正则),基于问题内涵与数据特点对网络结构进行的匹配设计(针对性的领域结构正则),以及如 dropout [11] 与 Batch Normalization [12] 等本质嵌入了正则因素的训练方法(隐式的模型参数正则)等。只不过在大数据的背景下,由于数据规律本身极其复杂,即使经过如此的正则控制,最终呈现的学习目标仍然相对传统方法具有更为庞大的结构形式。试想,即使针对所谓大规模数据,如果用一个参数量巨大,却不考虑任何数据 / 问题相关先验知识的全连接神经网络去对数据进行学习,除过庞大计算量的问题之外,过拟合问题也许仍然难以避免。以上介绍了机器学习从学习目标对数据的拟合,到学习目标的正则控制,再到学习目标中领域结构知识的有效编码与嵌入的发展历程。到目前为止,机器学习已在诸多领域中获得令人兴奋的成功应用,体现了蓬勃的发展趋势。
那么自然的一个问题是,未来机器学习还有什么值得研究的科学问题?在最近一个对周志华教授的访谈中2 ,关于机器学习下一步发展的问题,周教授提出了这样一个观点:“往后有很多任务可能都需要新的机器学习技术,但是一个大的趋势是我们要增加机器学习的鲁棒性。”在今年刚刚结束的人工智能顶会AAAI中,著名学者 Thomas G. Dietterich 教授也特别表达了对人工智能鲁棒性的关注3 。所谓机器学习方法的鲁棒性 (robustness),简单来说,就是当数据中包含异常干扰时,方法仍然能够保持稳健可靠的良好性能。事实上,从机器学习的基本模型 (1) 来看,机器学习的鲁棒性与误差函数的选择紧密相关。因此,接下来不再强调以上不断提及的学习机与正则项,侧重谈谈机器学习的误差项。