2.4 优化循环
此刻,测试代码可以比原始代码加速2倍了。但这是能够获得的性能最好的代码吗?目前添加的导语可以在任何加速器上实现代码的提速,但为了在特定的测试机器上取得最佳性能,需要使用特定目标设备优化技术。万幸的是,OpenACC提供了一种指定devcie_type的优化手段,因此特定的子句仅在编译为指定设备的代码时才会生效。首先从分析目前代码的编译器反馈信息着手,针对matvec子程序,因为它是最为耗时的代码段(见图2-22)。

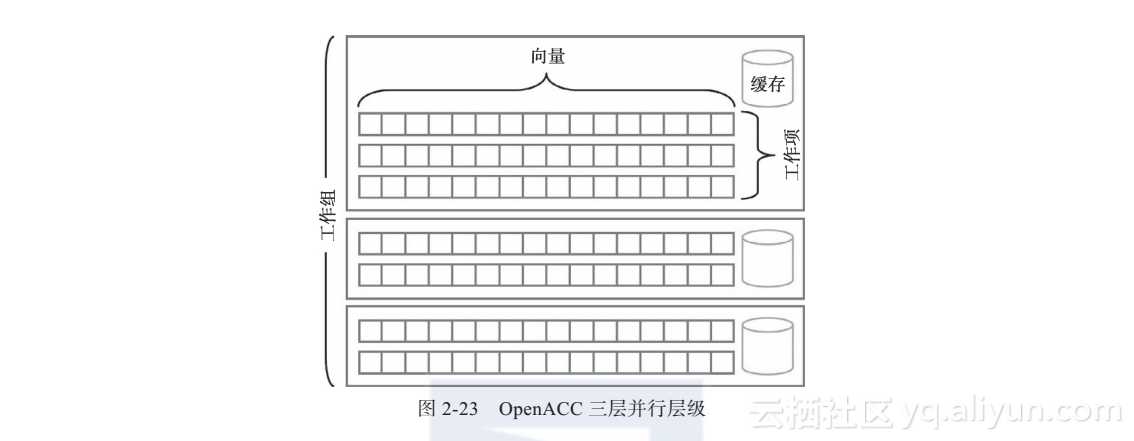
编译器提供了它如何并行化两个矩阵循环(第30和24行)的信息。但为了理解这些信息,需要理解OpenACC的三层并行层级:工作组(gang),工作项(worker)和向量(vector)。从最底层开始研究,向量化并行层级是针对细粒度并行的,对多个数据元素实施同样的操作。例如,有两个数组想要进行相加操作,有些硬件支持特殊的指令集,可以在成组的数据中同时进行加法操作。同时相加操作的数据个数称为向量长度,这一值随着不同硬件有所不同。顶层并行层级是工作组。工作组运行完全独立的操作,操作相互间不可能进行同步,且无法保证什么时候每个工作组会与其他工作组发生通信。由于工作组并行层级是粗粒度的,故具有很好的可扩展性。工作项并行层级介于工作组和向量之间。工作组由一个或多个工作项组成,每个工作项操控一个向量。同一个向量内的工作项可进行同步操作,且可以共享同一个高速缓存。每个由OpenACC编译器并行化的循环将被映射到以上三层并行层级中的至少一层,或串行执行(如果由seq修饰)。图2-23展示了OpenACC的三层并行层级。
基于以上背景知识,能够研究OpenACC编译器如何将二重循环映射到三层并行层级中的。它将第30行的循环映射到gang和vector并行层级,隐式地为每个gang建立了一个worker,且将向量长度设置为128。第34行的循环是串行执行的。有了这些信息,现在可以告知编译器额外的信息,引导获知编译器如何将这些循环映射到不同的并行层级。
2.4.1 缩短向量长度
使用NVIDIA GPU运行测试程序,作者会利用对NVIDIA GPU的理解和应用经验来更好地决策如何进行循环并行化。例如,知道NVIDIA GPU在向量循环在stride-1范围内进行数据访问时效率最高,即每个连续的循环体访问的是连续的数组元素。外层循环以跨度1访问row_offsets数组,内层循环也以跨度1访问Acols,Acoefs和xcoefs数组,这样使得代码更适合于向量化目标处理器。为内层循环添加loop导语允许进一步标明内层循环属于哪一个并行度层级。此外,可以说明向量长度是多少。编译器更倾向于使用128作为向量长度,但内层循环永远处理27个非零元素,这样会在每次运行循环时损失101个向量通道的性能。这里缩减向量长度是更好的选择,当然前提是提前知道循环次数。理想情况下,将向量长度缩减为27,因为已知循环迭代次数就是27,但NVIDIA GPU具有硬件向量长度,NVIDIA称为warp宽度,即32。因此,将向量宽度缩减为32,仅浪费掉5个向量通道而不是101个。图2-24展示了内层循环映射为vector并行层级且向量长度为32的matvec循环。注意:device_type子句需要添加到循环导语中,该子句表明列举的多条子句仅适用于nvidia类型的设备。这表明在其他设备上,编译器不进行这些特殊处理。


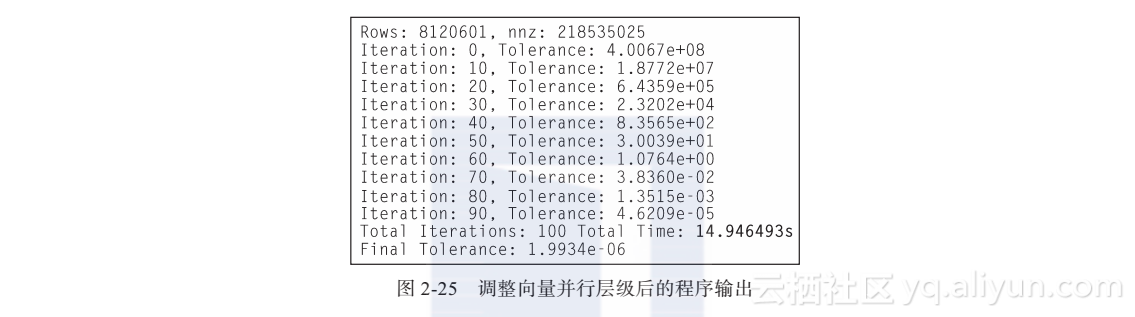
如图2-25所示,这一改动实际上降低了程序整体性能。可以尝试性地将代码改回原样,因为这一改动没有提升性能。但作者认为向量化最内层循环是一个正确的决定,故使用性能调试器来运行程序,以便能更好地理解为什么没有获得理想中的加速效果。
2.4.2 增加并行度
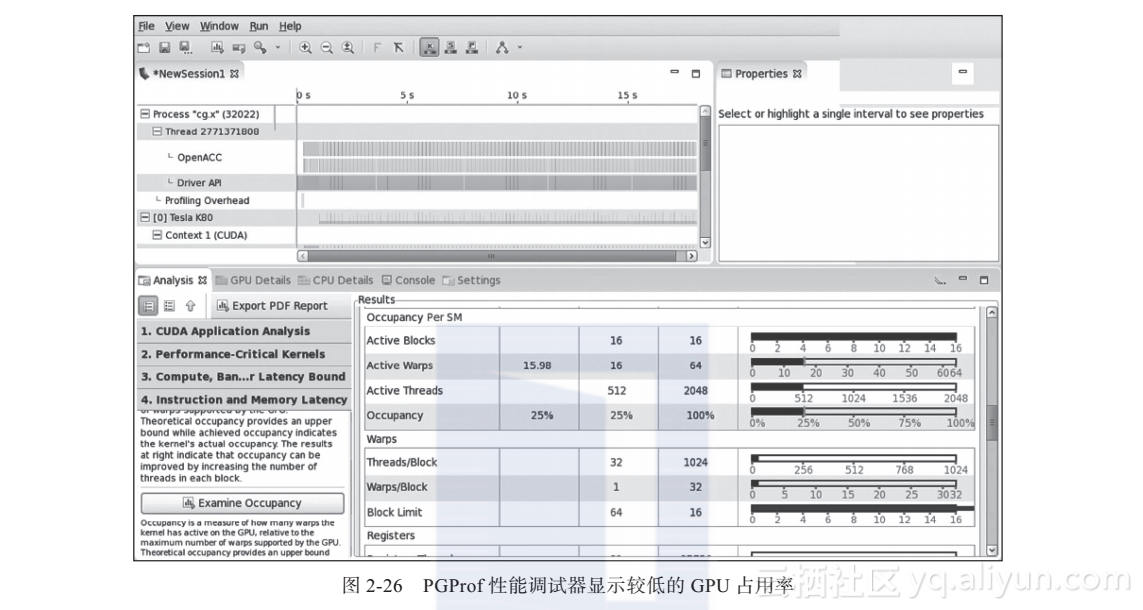
为了确定为何修改向量宽度后并未获得期望的性能提升效果,将使用PGProf指导分析模式来辅助监测性能瓶颈点。指导性分析是默认开启的,因此在当前可执行文件中开启一个新代码段时,需要选择“分析”选项卡并遵循文档建议的操作。分析过程最终将集中于GPU占用率,这是一个瓶颈,如图2-26所示。占用率是NVIDIA提出的一个术语,标志GPU工作强度的饱满程度,即GPU当前工作强度与其理论最大工作能力之间的比较。NVIDIA GPU由1个或多个流多处理器组成,通常称为SM。每个SM可以操控多达2048个并行线程,但这些线程不一定能够同时处于激活和运行状态。性能调试器输出结果显示对于可能激活的2048条线程,SM仅运行了512条线程,导致占用率为25%。图2-26中的红线说明了原因:SM可以最多调度16个线程块,对应于OpenACC的gang,但根据gang的尺度大小,需要有64个线程块才能达到最大占用率,但从“Threads/Block”行中发现仅有32个线程。以上情况说明通过缩减向量宽度至32,每个线程块的总线程数也被缩减到32,因此需要引入更大的并行度来更好地“喂饱”GPU。
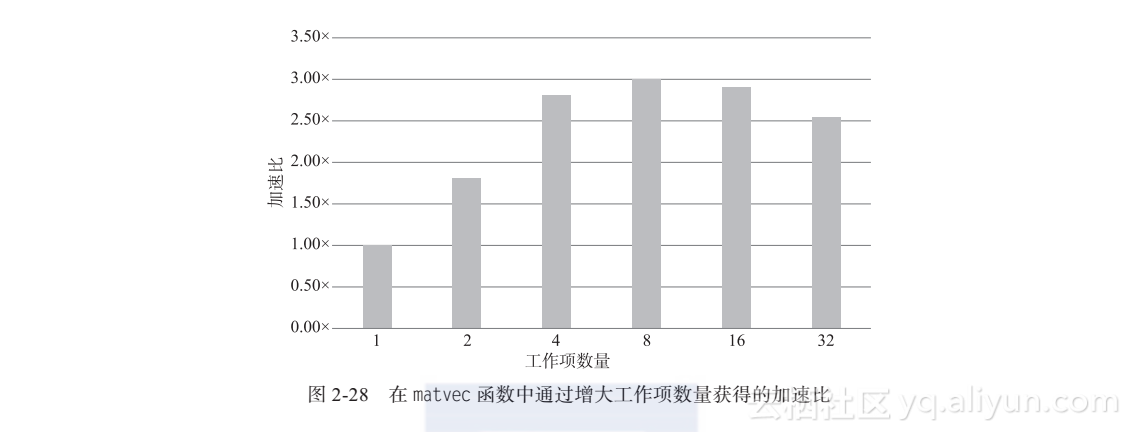
可以通过两种途径增加gang的并行度:增加向量宽度和增加工作项。从前述章节可知,增加向量宽度是无效的,因为没有足够的计算量适应更长的向量宽度。因此将尝试增加工作项的数目。GPU线程块中的总任务可以认为是工作项数×向量宽度。因此,最多可以利用32个工作项,因为32×32=1024个GPU线程。图2-27展示了最终的matvec循环的代码。图2-28展示了通过改变每个工作组中的工作项数获得的加速效果。

在本书使用的测试系统中,8个worker和32个线程对应于最优gang。因为使用了device_type子句,这些优化仅作用于NVIDIA GPU,不会影响其他加速器设备对应的代码。