3.1 通过监控规划容量
任何一家互联网公司都会有自己的运维系统,在运维系统之中,重中之重的是监控系统。
监控的方法有很多,最简单的就是利用一些系统命令,如用df命令来查看磁盘使用率,然后每天出报表,通过查看报表运维人员便监控到系统压力及容量,当逼近系统压力上限时,发出报警,提醒扩容。
但这种方法不能作为主要的监控手段,仅用来做辅助监控之用,毕竟监控是为了实时了解系统的状态。这方面都是用监控系统来完成,目前开源的监控系统有很多,如cacti、zabbix等,大多数监控系统都是以图表方式展示监控指标,如图3.1所示。
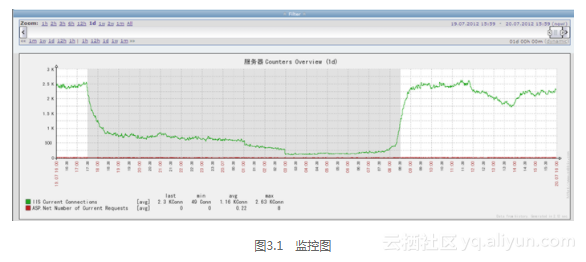
大多数监控系统都是基于SNMP(Simple Network Management Protocol),即简单网络管理协议。SNMP是度量性能指标的通用标准,大部分网络设备和服务器设备都支持该协议,因此,我们的监控系统才能通过该协议获取到设备的监控指标。既然是“简单”网络管理协议(其实SNMP一点都不简单),这说明仅凭SNMP的话还是不能满足所有监控需求,因此,这些监控系统也支持自定义采集程序。
扩展一下,如果公司业务比较复杂,一般的开源监控系统无法满足需求的话,公司会开发出适合的监控系统。这通常是为满足自定义监控,自定义的监控一般包括。
(1)日志监控,从日志文件中匹配出关键字,统计相应的个数,比如统计状态码的个数,或者处理时间大于一定时间的个数。
(2)端口监控,探测端口是否存活,一般用来判断Server程序是否“健在”,但不是很可靠,有时候Server端口还占据着但已经无响应了,此时端口监控依然表示正常。
(3)语义监控,这种就相对可靠多了,它是模拟客户端向Server发送请求,然后Server给予响应的方式来监控。
(4)结构体监控,这种监控要与特定进程绑定到一起才行得通,也就是那个被监控的模块会处理这种结构体。
除此之外,还可以通过模拟用户单击的方式来监控,也就是模拟用户行为,这是最真实的监控,效果最好,但由于此类模拟程序是要捕捉网页中的dom标签元素,因此,只要网页改变,监控就要重新写,比较麻烦。
回到正题,在监控系统中我们都会设置报警阈值,在监控图中我们都会看到逼近报警阈值的紧迫程度。如果接近了阈值,运维人员便开始扩容。
扩容的前提是压力趋近于模块的极限,如某模块每秒最大处理的请求数(qps)是300个,当实际qps接近于250左右时就要考虑扩容了。如何判断模块已经接近了最大处理极限呢?一种方法是在程序的日志文件中增加请求处理时间的字段,这样针对每个请求的处理时间我们便清楚了,如果任何页面的处理时间太长的话就要考虑扩容了。这里所说的处理时间长度没有固定的大小,还是要和业务结合,如果该页面主要消耗CPU资源,在不考虑阻塞的情况下,该页面的处理时间就不应该太大,最大不超过几百毫秒,如果该页面功能和存储或外网相关,就会相对长一些,超过1秒是很正常的。
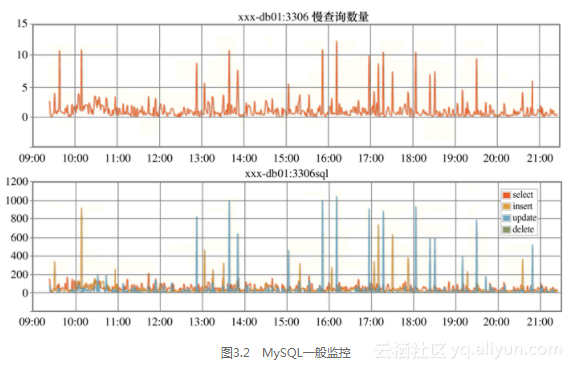
一般情况下我们也会把模块各种请求的处理数量或大于某值的请求统计出来,按分钟或更小的时间粒度在监控系统中绘图。如图3.2的MySQL的增、删、改、查和慢查询监控图所示。
除此之外,大多数模块都会有请求超时的设置,例如某模块设置了请求的最大处理时间是30秒,超过30秒的请求会在日志中写入报错信息,一般会有warning、error或fatal等关键字,我们可以在监控日志中匹配这些关键字来统计单位时间内因超时而报错的请求数,当达到某个极限值时就表示离扩容不远了。
为了将监控可视化,通常情况下也会把这类日志监控添加到监控系统中,同样,如果监控系统不支持这类监控的话,我们可以自己写监控程序,然后自己输出图像。一般开发语言中都有现成的图形函数可以调用,或者使用第三方工具,如可以利用rrdtool或者前端图形库highcharts、amcharts等。