越来越多的应用采用MongoDB作为数据存储层,性能高,扩展性强,通过WriteCocern参数还可以控制写入持久级别,CAP上灵活配置。文档型的存储结构又是特别适合物联网,游戏等领域,这些数据也蕴藏这巨大的价值,就像是金矿一样,需要挖掘。虽然MongoDB提供了MapReduce功能,但功能相对薄弱,如果说MongoDB MapReduce是铁锹,Spark就是一台真正的挖掘机。
阿里云云数据库已经推出了MongoDB云服务,EMR(E-MapReduce)也是公测期,EMR提供了便捷的Spark服务,本篇文章将给大家介绍下如何使用使用阿里云服务,构建基于MongoDB的大数据计算平台。
EMR服务申请和创建
准备工作
- 钱,服务是要买的,学习为目的可以使用小时付费
- 提前开通OSS,EMR服务是依赖OSS的,所以建议提前开通OSS
申请EMR公测资格
点击申请地址,开通一般是在1-2个工作日左右,目前公测期间EMR服务的价格与ECS保持一致。长期使用可以按月购买,最小规模大概1000元左右,学习的话可以按小时付费,不过用好后请记得释放。
创建EMR集群
申请通过后就可以创建集群了,注意下运行日志的路径,需要指定一个OSS Bucket存放日志,为了方便追踪状态,建议开启。
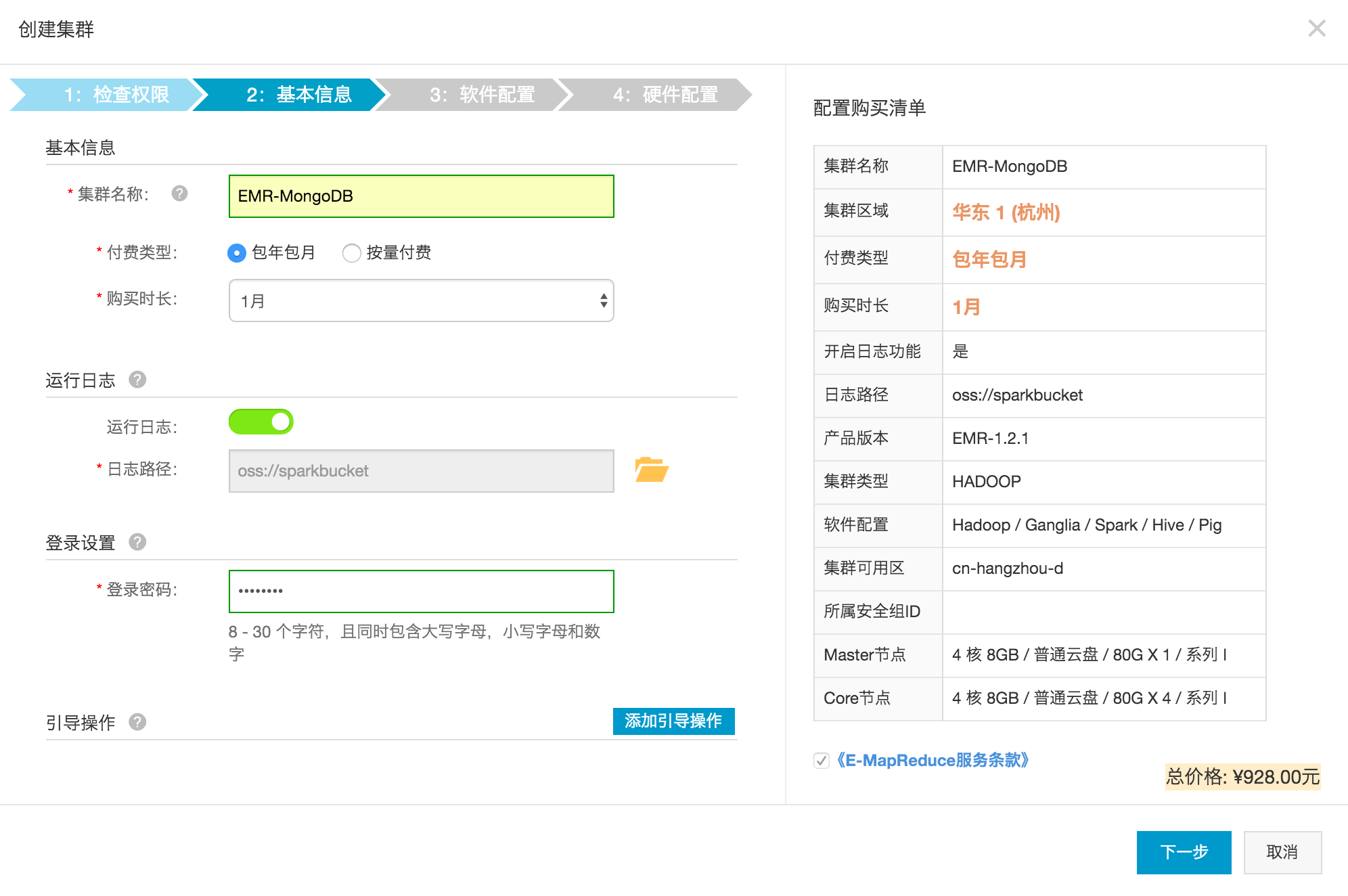
输入好密码后就可以点击下一步了进行软件配置,默认选择Hadoop集群即可,继续下一步。因为EMR实际上是运行在ECS上,所以需要安全组配置,没有的话需要创建一个。另外,测试目的的话需要最小化集群配置,Core减小到一个节点,生产目的的话强烈建议多个Core。
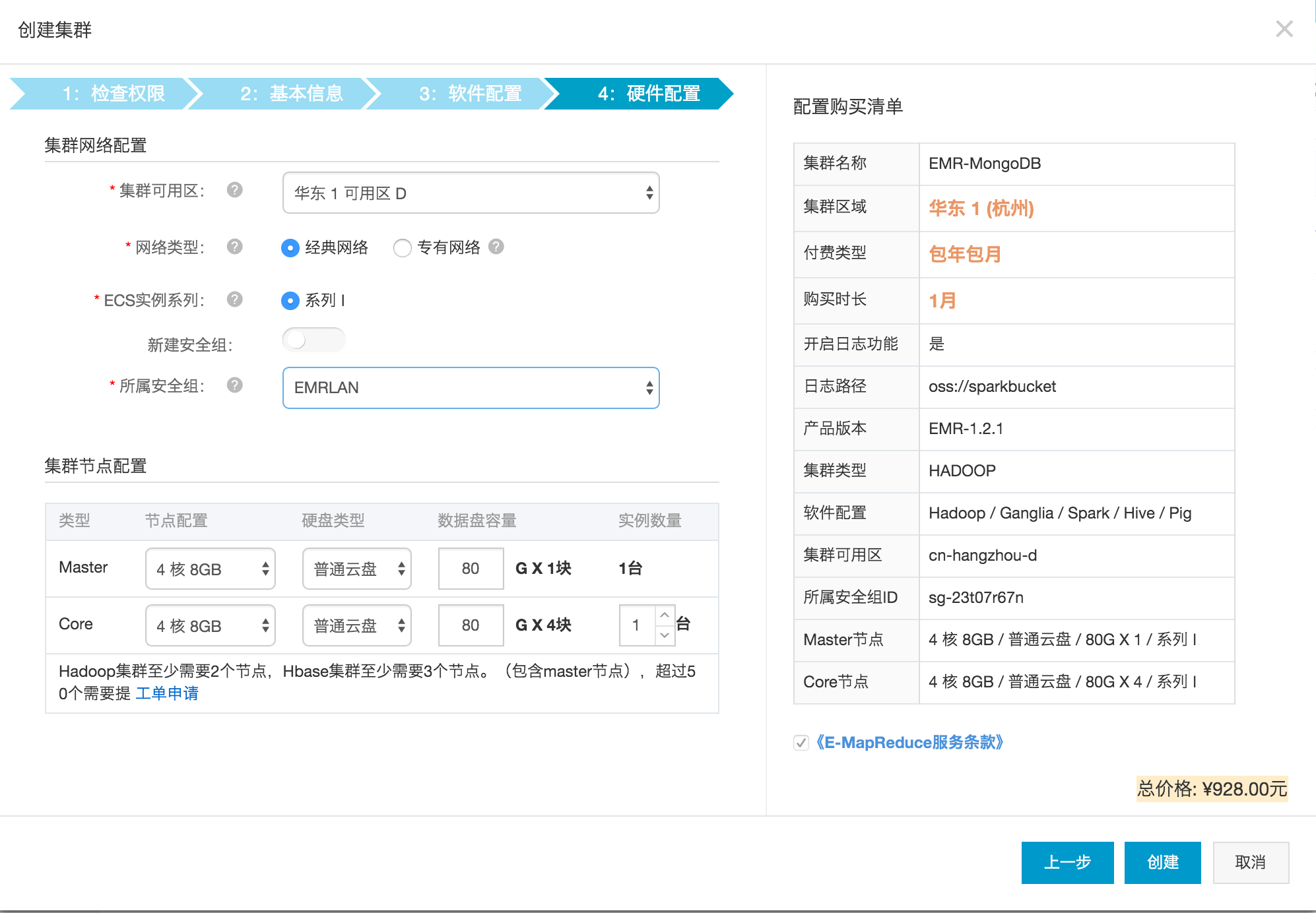
继续,支付订单,等待集群创建,大概30秒后集群即可创建完毕。在ECS控制台上也可以看到新生产出的两个ECS节点,上面就运行着EMR服务,我们可以像使用普通ECS的方式一样登陆到节点上。

OK,至此Spark集群已经构建完成。
购买阿里云云数据库MongoDB
因为MongoDB已经是商业化的服务,所以正常购买即可,但需要注意的是,一定要购买与EMR服务在同一个可用区的实例,否则网络是不通的。
EMR可用区查看

MongoDB可用区选择
等待30S后查看控制台,MongoDB实例创建成功。
创建好后,先写上几条数据,为后面的DEMO做准备,如图: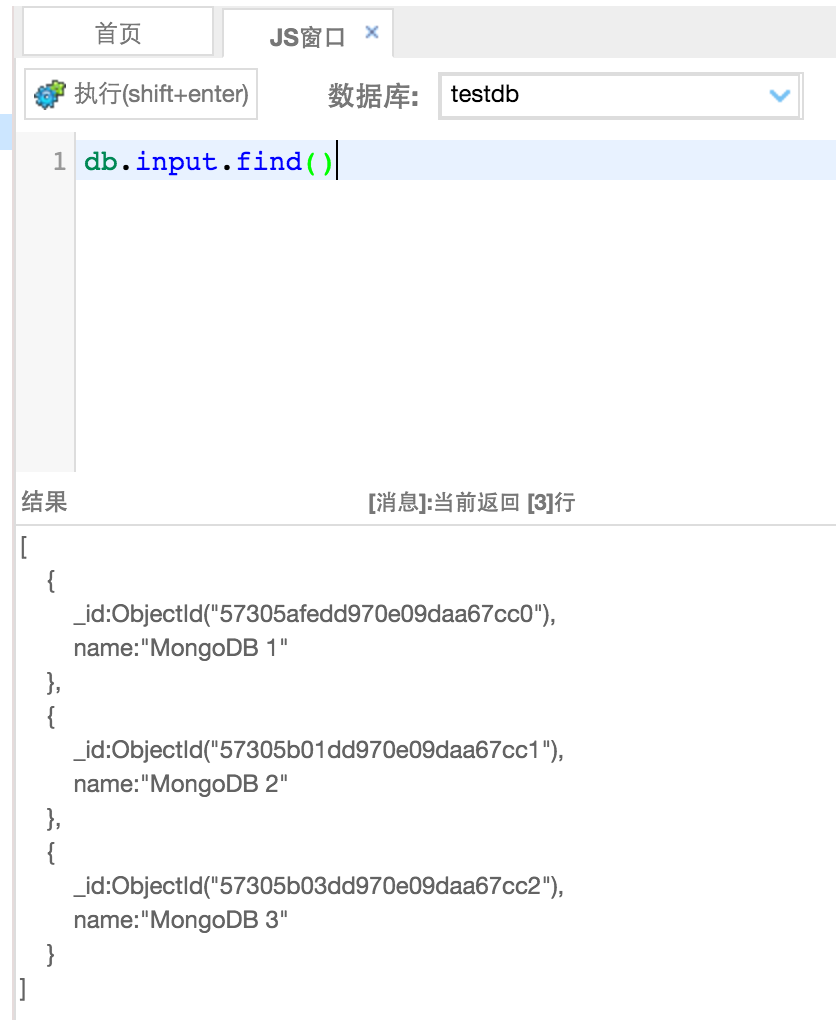
检查网络连通性
开始之前还需要检查下EMR与MongoDB云服务的网络连通性,看看是否是畅通的。登陆到EMR创建好的ECS上,通过telnet命令来探测:
telnet dds-xxxxxxx.mongodb.rds.aliyuncs.com 3717
如果发现无法连接有几个可能性逐一排查:
- EMR服务与MongoDB云服务不在同一个可用区,阿里云的网络规则下是不通的,需要重新购买
- 安全组限制了内网进出口,可以登陆ECS控制台修改安全组规则,让其可以访问MongoDB服务端口
- 由于欠费等原因,生长出来的实例被回收了,也可以通过控制台查看实例状态是否正常
至此,资源都已经Ready,接下来我们一起构建Spark 计算用的Jar包吧。
Spark任务编写
Jar包依赖
要想Spark访问MongoDB,必须找到相对应的Hadoop Connector和相关的Jar包,可以参考如下Maven POM配置。具体的版本,根据自己的实际需要去更新。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.aliyun.mongodb</groupId>
<artifactId>spark-test</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>fully.qualified.MainClass</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver</artifactId>
<version>3.2.2</version>
</dependency>
<dependency>
<groupId>org.mongodb.mongo-hadoop</groupId>
<artifactId>mongo-hadoop-core</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>
Job编写
通过MongoDB控制台准备好MongoDB的几个属性:
- 两个访问地址,注意,是两个
- 用户名,密码,从MongoDB上拉取需要读权限,如果还希望数据写回MongoDB,那写权限也需要准备好
- MongoDB集群名,以mgset开头
private static String DEFAULT_AUTH_DB = "admin";
private static String seed1 = "dds-xxxxx1.mongodb.rds.aliyuncs.com:3717";
private static String seed2 = "dds-xxxxx2.mongodb.rds.aliyuncs.com:3717";
private static String username = "root";
private static String password = "123456";
private static String replSetName = "mgset-1234567";
接下来构建MongoDB ConnectionURI,具体的规则参考如下代码,参考github文档,或者跟着下面的代码抄写。最终要有三个URI:
mongoURI用来鉴权inputURI数据输入地址ouputURI数据输出地址
private static String authURIPrefix = "mongodb://" +
username + ":" + password + "@" +
seed1 + "," + seed2 + "/";
private static String authURISuffix = "?replicaSet=" + replSetName;
private static String inputColl = "testdb.input";
private static String outputColl = "testdb.output";
private static String mongoURI = authURIPrefix + DEFAULT_AUTH_DB + authURISuffix;
private static String inputURI = authURIPrefix + inputColl + authURISuffix;
private static String outputURI = authURIPrefix + outputColl + authURISuffix;
至此,访问环境相关的变量都已经初始化完成,正式进入到Job内容,这里的Demo很简单,不能免俗的Hello World风格,但麻雀虽小五脏俱全,从配置到输入到计算再到输出,完整的一套流程。
首先撞见SparkContext,Spark作业的生命周期都会伴随着这个Context,并且配置Configuration对象,Configuration对象维护着上面提到的访问地址参数,更详细参数说明可以参考github。
JavaSparkContext sc = new JavaSparkContext(new SparkConf());
Configuration config = new Configuration();
config.set("mongo.job.input.format", "com.mongodb.hadoop.MongoInputFormat");
config.set("mongo.job.output.format", "com.mongodb.hadoop.MongoOutputFormat");
config.set("mongo.auth.uri", mongoURI);
config.set("mongo.input.uri", inputURI);
config.set("mongo.output.uri", outputURI);
接下来轮到获取数据RDD了,RDD是Spark中的数据表达形式。这里要注意RDD Value类型,是BSONObject,BSON是MongoDB文档数据的表现形式。通过这样一条语句做了BSON到RDD的映射。
JavaPairRDD<Object, BSONObject> documents = sc.newAPIHadoopRDD(
config, // Configuration
MongoInputFormat.class, // InputFormat: read from a live cluster.
Object.class, // Key class
BSONObject.class // Value class
);
有了数据,就可以开始计算了,简单的做个mapValues动作,可以注意看,返回的仍然是个RDD,不过这个RDD是经过map动作处理后的。
JavaPairRDD<Object, BSONObject> updates = documents.mapValues(new MongoDBMapFunction());
mapFunction很简单,替换所有的name值为Spark,当然也可以做些统计的DEMO,后面的文章会再介绍更复杂的DEMO,敬请关注。
public class MongoDBMapFunction implements Function<BSONObject, BSONObject> {
public BSONObject call(BSONObject bsonObject) throws Exception {
bsonObject.put("name", "spark");
return bsonObject;
}
}
最后一步,数据的输出,MongoDB即是输入源又是输出源,所以第一个hdfs路径参数实际是无效的,但不可以是null,后面的类型描述了RDD的key,value类型,要跟updates一致,最后的config内容已经在程序最开始设置过了。
updates.saveAsNewAPIHadoopFile(
"file://this-is-completely-unused",
Object.class,
BSONObject.class,
MongoOutputFormat.class,
config
);
额外说说明一下,Spark在动作是lazy的,整个代码流程下来,只有当程序执行到saveAsNewAPIHadoopFile时,才会触发数据拉取和计算等动作。
最后一步,构建Jar包,使用assembly的方式去构建,避免ClassNotFound的尴尬:
mvn assembly:assembly
上传JAR包并执行
剩下的操作都不需要写代码了,只需要操作控制台即可。几个步骤:上传JAR包->创建作业->创建执行计划->执行,我们来实际操作下。
再次登陆到OSS控制台,把刚才Jar包上传到OSS上,后面会用到。再回到EMR控制台上的作业栏里创建一个作业,需要指定一些参数,只名Job Class,然后点击下面的按钮添加OSS路径,内容是就是刚才上传的Jar包地址。值得注意的是,这里用的是ossref前缀,遇到这样的前缀EMR服务会自动的从OSS拉取Jar下来,否则原生的Spark是不识别的。最后应用参数应该是如下样子:
--master yarn-client --class com.aliyun.apsaradb.mongodb.Main ossref://sparkbucket/jar/spark-test-1.0-SNAPSHOT-jar-with-dependencies.jar
接下来是创建执行计划了,根据提示,在执行计划栏里进行创建,会提示采用的集群,作业集合,调度方式,这个DEMO采用的手动方式调度。
最后激动的时刻来临了,在执行计划栏里点击立即执行,运行过程和结束后都可以通过浏览器在网页上查看运行日志,非常方便。等待几十秒后,任务成功。
我们在回到DMS上查看数据集合,会发现已经多出了ouput集合,并且内容都为
{ "name": "spark"}
至此,Spark与MongoDB的Hello World风格教程结束,各位可以发挥无限的想象力,玩的开心!
参考连接:
- https://docs.mongodb.com/ecosystem/tools/hadoop/
- https://databricks.com/blog/2015/03/20/using-mongodb-with-spark.html