恰逢 CIKM 2017召开(2017 年 11 月 6 日,新加坡),AI 论道的第一篇文章主要介绍我们的被 CIKM 2017 收录的一篇文章:Dual Learning for Cross-Domain Image Captioning,这里只介绍了论文框架,细节请参照我们的论文。我们后续将 release 代码。
图片描述生成(image captioning)任务是结合 CV 和 NLP 两个领域的综合性任务,是一个跨学科跨模态的交叉性任务。其输入是一副图片,输出为对该图片进行描述的一段文字。这项任务要求模型可以识别图片的物体以及理解物体之间的关系,并用一句自然语言来表达。
应用场景:例如当用户拍了一张照片后,利用 image caption 技术为其匹配合适的文字,方便以后检索或省去用户手动配字等。此外,它还可以帮助视觉障碍者理解图片内容。
现在,许多科研团队和企业都参与来这个任务,包括 Google, IBM, Microsoft, 腾讯等。然而,这些团队主要在 MS COCO 数据集[1]上进行研究,并未考虑 cross-domain 的问题 (i.e., 训练数据与测试数据不属于同一个领域)。
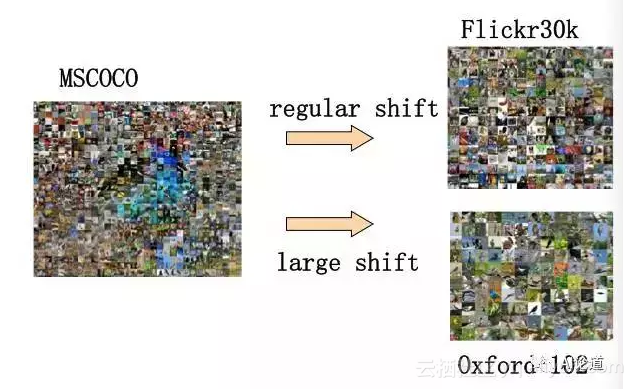
比如,下图为三个不同的数据,其中 MS COCO 与 Flickr30K 图片相似,具有比较小的差异。而 MS COCO 与 Oxford-102 数据集则存在较大差异。在 MS COCO 上训练的模型,在 Oxford-102 数据集上一般表现得非常差。

我们的工作主要致力于解决跨领域图片描述生成问题 (cross-domain image captioning)。我们采用了 pre-training then adaptation 的策略。首先在 Source domain (i.e. MS COCO) 数据上做 pre-training, 然后再在 target domain (e.g. Oxford-102) 数据上做 fine-tuning。我们的工作主要有以下贡献:
1. 据我们所知,我们是第一个将 dual learning 用于图片描述生成的工作。我们同时优化两个任务:图片描述生成和图片生成。图片描述生成部分,我们采用了 encoder-decoder 学习框架,其中 encoder 是 CNN (e.g. VGG-19), 而 decoder 是 attention-based LSTM 模型。 图片生成部分,我们采用了 GAN 学习框架;
2. 图片描述生成部分,我们应用了强化学习(RL),这样可以解决传统 maximize likelihood 所错存在的 exposure bias 和 non-differentiable task metric 问题;
3. 我们将 MS COCO 做为 source domain, 将 Oxford102 和 Flickr30K 作为target domain。实验结果证明,我们的方法比传统方法有较大提升。
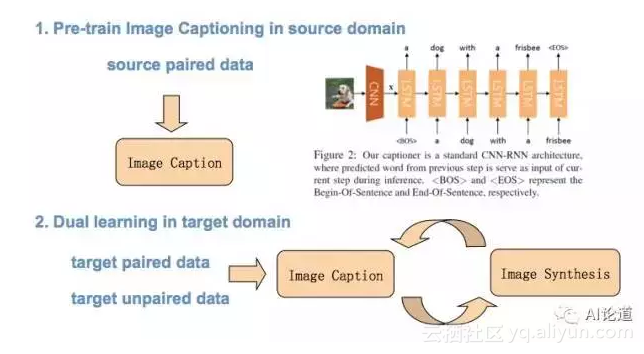
pre-training 的过程采用了标准的 encoder-decoder 框架,对于具体细节问题,还请大家参考原文。下面将为大家主要介绍我们的用于 domain adaptation 的 dual learning 方法。
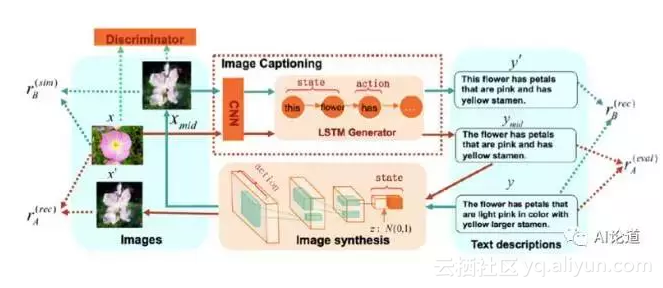
我们采用强化学习强化学习(i.e., Policy gradient)方法来优化整个模型。我们运用了两类 rewards: evaluation metrics 和 reconstruction reward。前者可以帮助我们充分的优化生成的衡量指标,比如 BLEU,CIDEr 。后者可以帮助我们同时利用 image captioning 和 image synthesis 模型的关联,提高两个模型的效果。
另外,因为计算 reconstruction reward 不需要标注数据,我们的模型也可以无监督的或者半监督地进行学习(通过为 policy gradient 选择不同的 reward)。
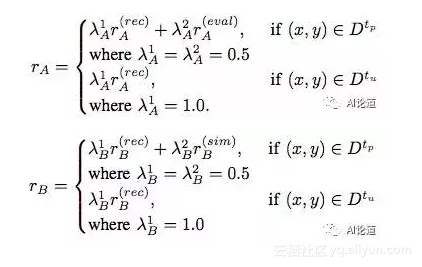
reconstruction reward 的计算依赖于 dual learning 过程。我们将 image captioning 作为 primal task A,将 image synthesis 作为 dual task B。例如,当我们从 A 开始时,过程如下:首先,我们用模型 A 为每个图片 x 生成一个中间描述 y_{mid}。然后,我们用模型 B 为中间描述 y_{mid} 反向生成一个图片 x’。最后,通过评测这两个过程的生成结果,我们可以采用强化学习同时提高模型 A 和 B 的效果。
同理,当我们从 B 开始时,我们用模型 B 为每句图片描述y生成一个中间图片 x_{mid}。 然后,我们用模型 A 这个中间图片 x_{mid} 生成一句描述 y’。
这时我们可以计算模型 A 和模型 B 的 policy gradient 算法的 rewards:
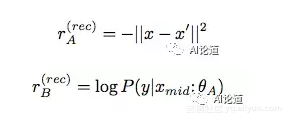
实验结果
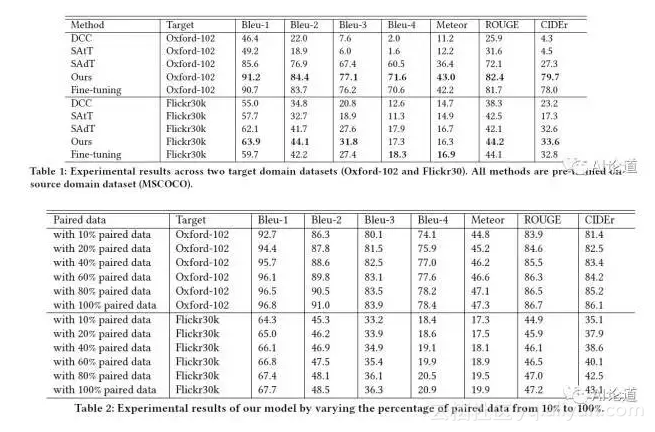
为了验证我们的跨领域图片描述生成模型,我们将 MS COCO 作为 source domain,将 Oxford102 和 Flickr30K 作为 target domain。
可发现我们的算法有较高提升。
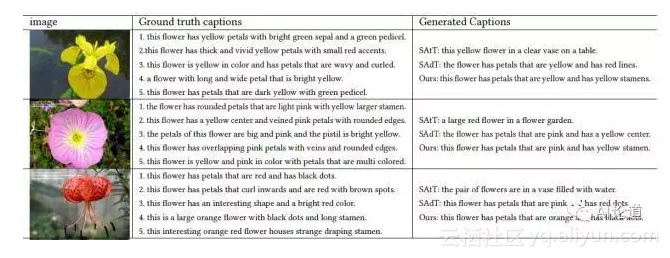
我们也分别展示了生成的图片描述:
以及生成的图片:

关于我们
“AI论道”公众号主要用于介绍我们团队(中科院深圳先进院前瞻中心移动大数据实验室[2])以及 coauthors 的 AI 相关的一些工作。这里要感谢温伟煌同学,我们的知乎、微博、微信公众号才得以顺利出现在大家面前。
顺便打一个招人广告(我们正在建立一个研究团队):欢迎对科研有热情的同学报考我们的研究生,也欢迎同学(本科生、研究生)来我们组里实习,主要做一些关于机器学习(ML),自然语言处理(NLP)(包括将 NLP 用于图像,金融,安全等领域 )的工作。
具体研究领域请参见我的个人主页[3],同时,也欢迎大家推荐或者自荐来我们组里做 postdoc。有意者可以将简历发至我邮箱:min.yang1129@gmail.com。