
Prophet 是 Facebook 推出的开源大规模预测工具,可以在 R 和 Python 中使用以预测时间序列数据。
下面将简单介绍 Prophet 在 R 中的使用。
一、基础介绍
下面实例中使用的是佩顿 · 曼宁的维基百科主页每日访问量的时间序列数据(2007/12/10 – 2016/01/20)。我们使用 R 中的 Wikipediatrend 包获取该数据集。这个数据集具有多季节周期性、不断变化的增长率和可以拟合特定日期(例如佩顿 · 曼宁的决赛和超级碗)的情况等 Prophet 适用的性质,因此可以作为一个不错的例子。( 注: 佩顿 · 曼宁为前美式橄榄球四分卫)
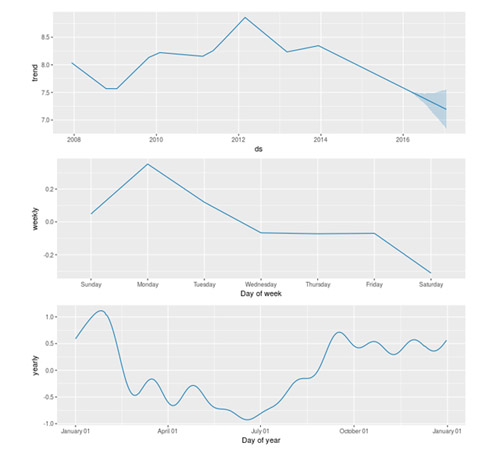
在 R 中,Prophet 提供了一个 prophet 函数去拟合模型并且返回一个模型对象,可以对这个模型对象执行“预测”( predict )和“绘图”( plot )操作。

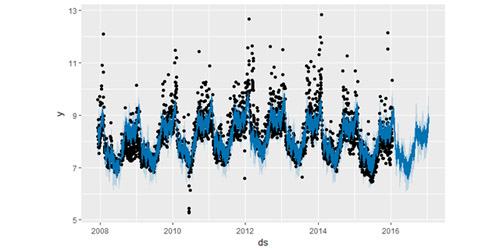
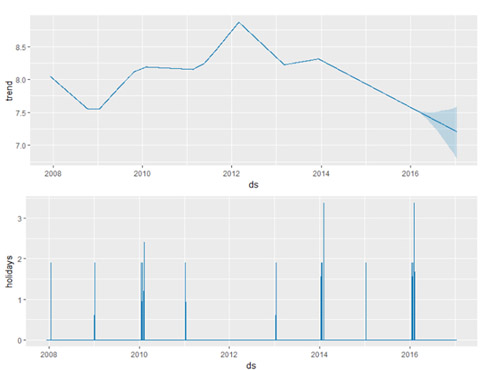
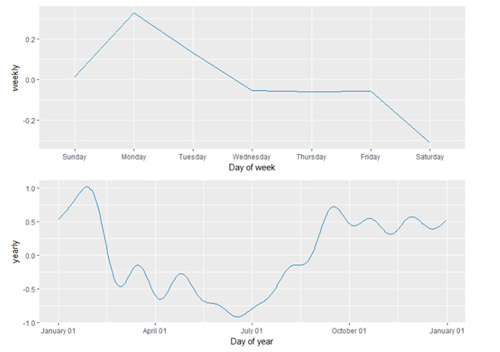
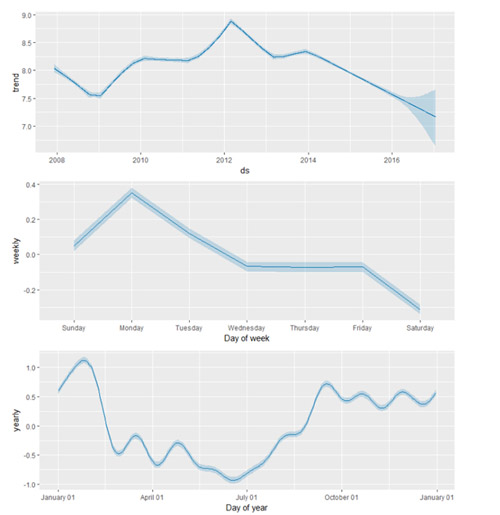
使用 prophet_plot_components 函数去展示预测中的趋势、周效应和年度效应。

注: Windows 系统语言设置为中文的话,会导致 R 输出成分分析图时,周效应无法正常显示,可在 R 中使用 Sys.setlocale("LC_ALL","English") 代码将环境改为英文。
二、预测增长
默认情况下, Prophet 使用线性模型进行预测。当预测增长情况时,通常会存在可到达的最大极限值,例如:总市场规模、总人口数等等。这被称做承载能力,那么预测时就应当在接近该值时趋于饱和。
Prophet 可使用 logistic 增长 趋势模型进行预测,同时指定承载能力。下面使用 R 语言的维基百科主页 访问量(取对数)的实例来进行说明。


三、趋势突变点
默认情况下, Prophet 将自动监测到突变点,并对趋势做适当地调整。
下面将会介绍几种使用的方法可以对趋势的调整过程做更好地控制。
1. 调整趋势的灵活性
如果趋势的变化被过度拟合(即过于灵活)或者拟合不足(即灵活性不够),可以利用输入参数 changepoint.prior.scale 来调整稀疏先验的程度。默认下,这个参数被指定为 0.05 。
增加这个值,会导致趋势拟合得更加灵活。如下代码和图所示:

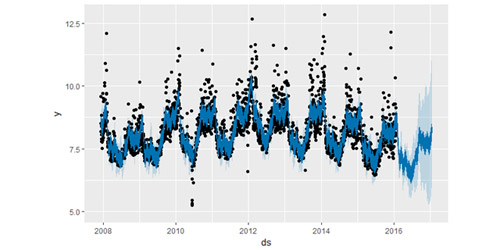
减少这个值,会导致趋势拟合得灵活性降低。如下代码和图所示:


四、节假日效应
1. 对节假日建模
如果需要专门对节假日进行建模,你就必须得为此创建一个新的数据框,其中包含两列(节假日 holiday 和日期戳 ds ),每行分别记录了每个出现的节假日。
你可以在这个数据框基础上再新建两列 lower_window 和 upper_window ,从而将节假日的时间扩展成一个区间 [ lower_window , upper_window ] 。举例来说,如果想将平安夜也加入到 “圣诞节” 里,就设置 lower_window = -1 , upper_window = 0 ;如果想将黑色星期五加入到 “感恩节” 里,就设置 lower_window = 0 , upper_window = 1 。
下面我们创建一个数据框,其中包含了所有佩顿 · 曼宁参加过的决赛日期:
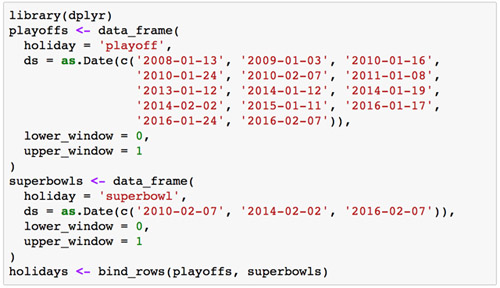
上述代码中,我们将超级碗的日期既记录在了决赛的日期数据框中,也记录在了超级碗的日期数据框中。这就会造成超级碗日期的效应会在决赛日期的作用下叠加两次。
一旦这个数据框创建好了,就可以通过传入 holidays 参数使得在预测时考虑上节假日效应。

可通过 forecast 数据框,来展示节假日效应:

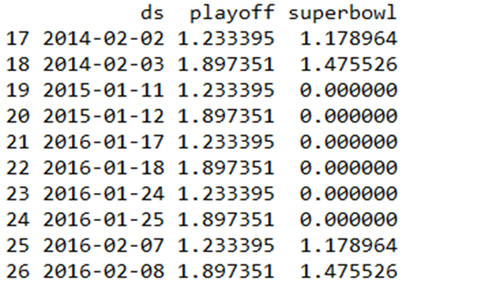
在成分分析的图中,如下所示,也可以看到节假日效应。我们可以发现,在决赛日期附近有一个穿透,而在超级碗日期时穿透则更为明显。

2. 对节假日和季节性设定先验规模
如果发现节假日效应被过度拟合了,通过设置参数 holidays.prior.scale 可以调整它们的先验规模来使之平滑,默认下该值取 10 。

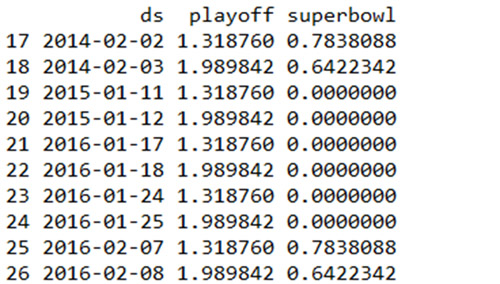
和之前相比,节假日效应的规模被减弱了,特别是对观测值较少的超级碗而言。类似的,还有一个 seasonality.prior.scale 参数可以用来调整模型对于季节性的拟合程度。
五、预测区间
在预测时,不确定性主要来源于三个部分:趋势中的不确定性、季节效应估计中的不确定性和观测值的噪声影响。
1. 趋势中的不确定性
预测中,不确定性最大的来源就在于未来趋势改变的不确定性。Prophet 假定 “未来将会和历史具有相似的趋势” 。尤其重要的是,我们假定未来趋势的平均变动频率和幅度和我们观测到的历史值是一样的,从而预测趋势的变化并通过计算,最终得到预测区间。
这种衡量不确定性的方法具有以下性质:变化速率灵活性更大时(通过增大参数changepoint.prior.scale 的值),预测的不确定性也会随之增大。原因在于如果将历史数据中更多的变化速率加入了模型,也就代表我们认为未来也会变化得更多,就会使得预测区间成为反映过拟合的标志。
预测区间的宽度(默认下,是 80% )可以通过设置 interval.width 参数来控制:

2. 季节效应中的不确定性
默认情况下, Prophet 只会返回趋势中的不确定性和观测值噪声的影响。你必须使用贝叶斯取样的方法来得到季节效应的不确定性,可通过设置 mcmc.samples 参数(默认下取 0 )来实现。

上述代码将最大后验估计( MAP )取代为马尔科夫蒙特卡洛取样 ( MCMC ),并且将计算时间从 10 秒延长到 10 分钟。如果做了全取样,就能通过绘图看到季节效应的不确定性了:

六、异常值
下面我们使用之前使用过的 R 语言维基百科主页对数访问量的数据来建模预测,只不过使用存在时间间隔并不完整的数据:

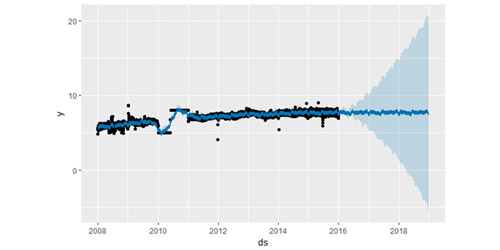
如上 R 输出图所示,趋势预测看似合理,预测区间的估计却过于广泛。
处理异常值最好的方法是移除它们,而 Prophet 使能够处理缺失数据的。如果在历史数据中某行的值为空( NA ),但是在待预测日期数据框 future 中仍保留这个日期,那么 Prophet 依旧可以给出该行的预测值。
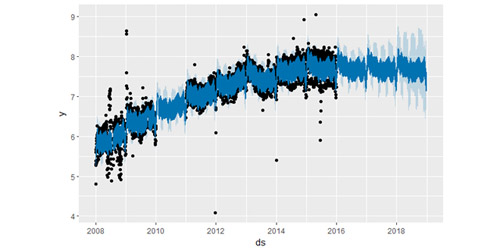
上述这个实例虽然影响了不确定性的估计,却没有影响到主要的预测值 yhat 。但是,现实往往并非如此,接下来,在上述数据集基础上加入新的异常值后再建模预测:

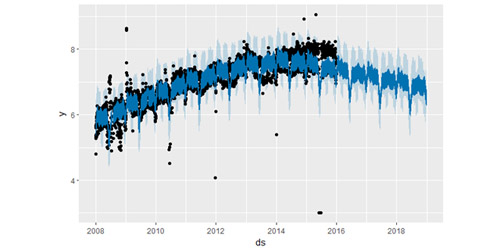
这里 2015年 6 月存在一些异常值破坏了季节效应的估计,因此未来的预测也会永久地受到这个影响。最好的解决方法就是移除这些异常值:

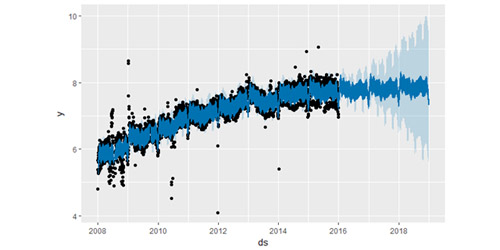
七、非日数据
Prophet 处理的对象并非必须是日数据,不过要是试图通过非日数据来预测每日的情况或拟合季节性效应,往往会得到奇奇怪怪的结果。下面使用美国零售业销售量数据来预测未来 10 年的情况:

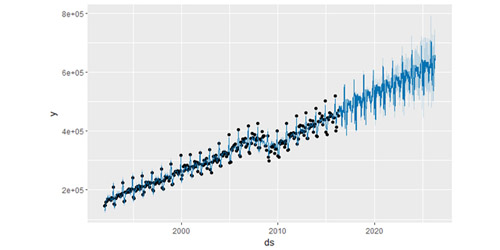
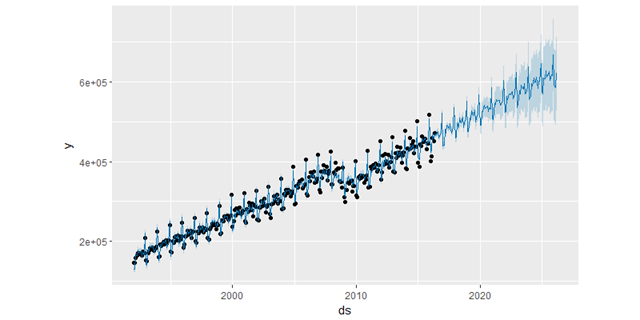
预测结果看起来非常杂乱,原因正是在于这个特殊的数据集使用的是月数据。当我们拟合年度效应时,只有每个月第一天的数据,而且对于其他天的周期效应是不可测且过拟合的。当你使用 Prophet 拟合月度数据时,可以通过在 make_future_dataframe 中传入频率参数只做月度的预测。

本文作者:佚名
来源:51CTO