
总结下最近做的一个项目,只提供一些技术方案,不涉及具体业务和具体实现。
背景
自动识别图片中电话号码,也可以推广到识别字符串,英文等。

---识别--->
“18811610168”
当然,背景会有干扰(自然环境),字体也更多变。
要求:全对识别,人工修正的成本过高,如果有一位识别错误,人工修正还不如重新输入方便(人工输入可以支持语音识别的)。
保证85%以上的数据是可以全对识别的,最好返回全对识别的概率。当然对于电话号码业务,根据识别的文本结果再加上电话的一些规则,后判断程序也可以有效地判断哪些是高概率识别错误的。
方案
目标检测、ocr识别已经是被学术界玩透的技术了。神经网路是目前的大热,而且效果极佳。识别方案有以下三种:
方案一:作为传统ocr来解
检测图片中的数字位置,然后对数字region过分类器识别。传统方法:Sliding Windows、Selective Search等寻找候选区域;Boosting分类器、SVM等都可以用于识别。深度学习的方案效果更好,比如:Faster RCNN、YOLO等。
它们的实质都是:检测字符的位置,识别字符的类别(内容)。
检测:

识别:
--->数字“1”
----->数字“8” … …
识别结果主要受检测准确度和识别精度的影响。在检测完全正确的情况下,自左向右识别各个字符,然后串联识别结果。
如果检测完全正确,识别分类器的loss=0.01,每个字符的正确识别的概率p=0.99。11位电话全对的概率约为0.895,loss值=-ln(0.895)=0.111。
但是,检测可能出错。另外,图片中的电话可能是倾斜的,后期串联结果也会比较繁琐,比如。
方案二:循环神经网络RNN
方案一没有考虑电话号码的序列特性,如果将图片分割为时序信号,送入RNN/LSTM/BLSTM等网络,识别性能会大幅提升。
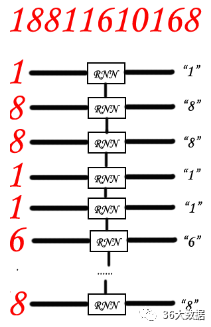
问题是图片的分割不准确怎么办?
其实这里的分割并不是严格的,解决方案是,将图片按行分割成n个,比如电话号码分割成21个小图片,然后20个图片送入RNN网络得到20个序列化的输出。
由于一个字符可能在相邻两个小图上出现(各一半),最终的识别结果很可能是“1_88_8_1_1_66_10_16_8”。最后再经过一个CTC网络融合得到“18811610168”。
方案三:循环卷积网路RCN
方案二是把图片原图分割后送入RNN网络,RNN做特征提取和分类识别。级联RNN的训练是不容易收敛的,而且特征的提取工作是CNN的强项。
重新设计网络,可以使用cnn提取图片的特征,然后将feature Map分割成n个,送入RNN做识别,最终通过CTC得到识别结果。
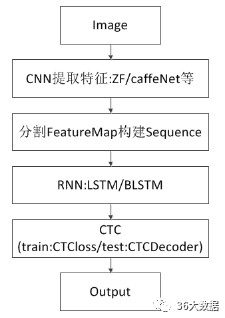
这样的好处是,输入数据不用做预处理,切割可以通过网络中矩阵的转置实现;网络实现了End-to-End;输出是完整字符串,识别准确率高,loss值约为0.02,全对正确率约为0.98。
本文作者:候凯
来源:51CTO