一. 正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
|
元字符 |
描述 |
|
\ |
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
|
^ |
匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
|
$ |
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
|
* |
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。 |
|
+ |
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
|
? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
|
{n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
|
{n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
|
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
|
? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多的匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少的匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
|
.点 |
匹配除“\r\n”之外的任何单个字符。要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。 |
|
(pattern) |
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
|
(?:pattern) |
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
|
(?=pattern) |
非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
|
(?!pattern) |
非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
|
(?<=pattern) |
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
|
(?<!pattern) |
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题 此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows 正确匹配 |
|
x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”或"|ood"。 |
|
[xyz] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
|
[^xyz] |
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
|
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
|
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
|
\B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
|
\cx |
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
|
\d |
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
|
\D |
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
|
\f |
匹配一个换页符。等价于\x0c和\cL。 |
|
\n |
匹配一个换行符。等价于\x0a和\cJ。 |
|
\r |
匹配一个回车符。等价于\x0d和\cM。 |
|
\s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
|
\S |
匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
|
\t |
匹配一个制表符。等价于\x09和\cI。 |
|
\v |
匹配一个垂直制表符。等价于\x0b和\cK。 |
|
\w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
|
\W |
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
|
\xn |
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
|
\num |
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
|
\n |
标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
|
\nm |
标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
|
\nml |
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
|
\un |
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
|
\p{P} |
小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。 其他六个属性: L:字母; M:标记符号(一般不会单独出现); Z:分隔符(比如空格、换行等); S:符号(比如数学符号、货币符号等); N:数字(比如阿拉伯数字、罗马数字等); C:其他字符。 *注:此语法部分语言不支持,例:javascript。 |
|
\< \> |
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
在linux中,通配符是由shell解释的,而正则表达式则是由命令解释的,下面我们就为大家介绍三种文本处理工具/命令:grep、sed、awk,它们三者均可以解释正则。
二. grep
1. grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为"-",则grep指令会从标准输入设备读取数据。
语法
- grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
- -a或--text 不要忽略二进制的数据。
- -A<显示列数>或--after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
- -b或--byte-offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
- -B<显示列数>或--before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
- -c或--count 计算符合范本样式的列数。
- -C<显示列数>或--context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
- -d<进行动作>或--directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式>或--regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
- -E或--extended-regexp 将范本样式为延伸的普通表示法来使用。
- -f<范本文件>或--file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
- -F或--fixed-regexp 将范本样式视为固定字符串的列表。
- -G或--basic-regexp 将范本样式视为普通的表示法来使用。
- -h或--no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
- -H或--with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
- -i或--ignore-case 忽略字符大小写的差别。
- -l或--file-with-matches 列出文件内容符合指定的范本样式的文件名称。
- -L或--files-without-match 列出文件内容不符合指定的范本样式的文件名称。
- -n或--line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
- -q或--quiet或--silent 不显示任何信息。
- -r或--recursive 此参数的效果和指定"-d recurse"参数相同。
- -s或--no-messages 不显示错误信息。
- -v或--revert-match 反转查找。
- -V或--version 显示版本信息。
- -w或--word-regexp 只显示全字符合的列。
- -x或--line-regexp 只显示全列符合的列。
- -y 此参数的效果和指定"-i"参数相同。
- --help 在线帮助。
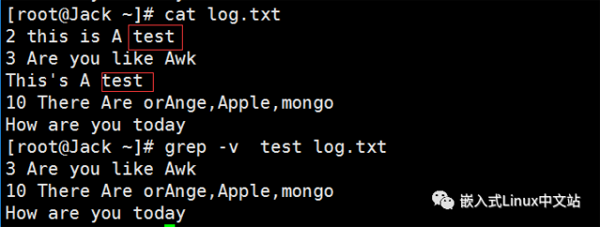
实例1 查找当前目录下包含”test“内容的所有文件
grep -r 匹配内容 目录,以递归的方式查找此目录及子目录下文件的内容

实例2 反向查找(-v)
查找文件中不包含”test“内容的行
2. egrep(扩展正则)
egrep执行效果与"grep-E"相似,使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
egrep是用extended regular expression语法来解读的,而grep则用basic regular expression 语法解读,extended regular expression比basic regular expression的表达更规范。
语法
- egrep [范本模式] [文件或目录]
参数说明:
- [范本模式] :查找的字符串规则。
- [文件或目录] :查找的目标文件或目录。
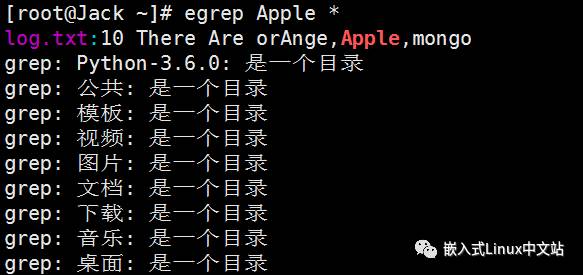
实例1 查找当前目录下包含“Apple”内容的文件,并显示匹配的行
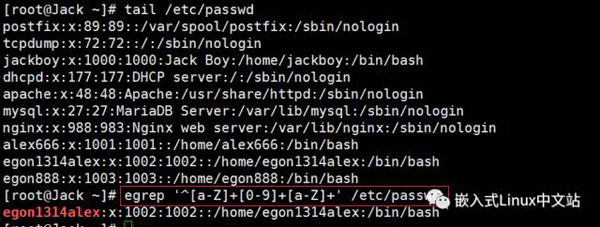
实例2 匹配用户配置文件中以“字母+数字+字母”命名的用户
三. sed
Linux sed命令是利用script来处理文本文件。
sed可依照script的指令,来处理、编辑文本文件。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
语法
- sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
- -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或--help 显示帮助。
- -n或--quiet或--silent 仅显示script处理后的结果。
- -V或--version 显示版本信息。
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
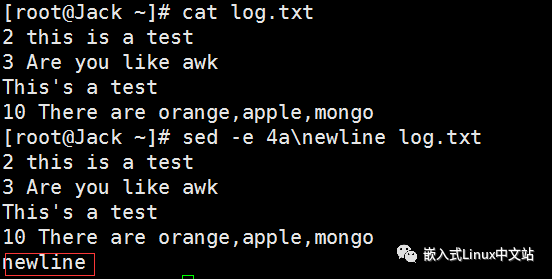
实例1 在“log.txt"的第4行后添加一行
实例2 将文件中的第2,3行删除并显示出来(注意,实际上”log.txt“文件并没有被修改)
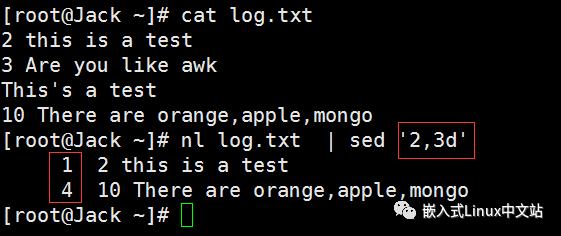
实例3 将文件中的2,3行用”No 2-3 number“取代

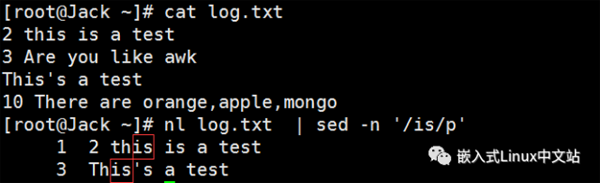
实例4 匹配每一行是否有”is“,然后仅输出匹配的行的内容
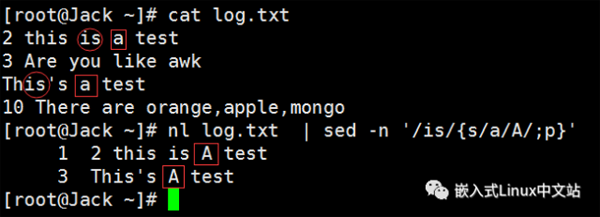
实例5 匹配包含”is“的行,并将其中的’a‘替换为’A‘
{}内为执行的命令,每条命令之间用”;“隔开
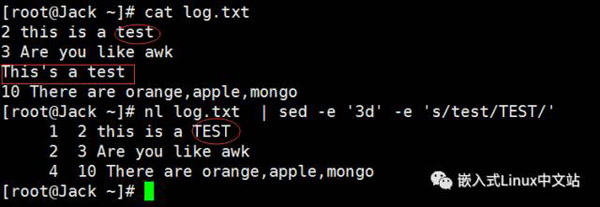
实例6 多点编辑,将文件中的第3行删除,并将”test“替换为”TEST“
实例7 直接修改文件内容(危险动作)
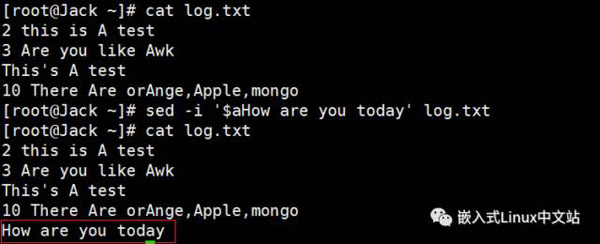
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试!
在文件最后一行插入一行内容”How are you today“,并保存
四. awk
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的Family Name的首字符。
语法
- awk [选项参数] 'script' var=value file(s)
- awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
- -F fs or --field-separator fs
- 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
- -v var=value or --asign var=value
- 赋值一个用户定义变量。
- -f scripfile or --file scriptfile
- 从脚本文件中读取awk命令。
- -mf nnn and -mr nnn
- 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
- -W compact or --compat, -W traditional or --traditional
- 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
- -W copyleft or --copyleft, -W copyright or --copyright
- 打印简短的版权信息。
- -W help or --help, -W usage or --usage
- 打印全部awk选项和每个选项的简短说明。
- -W lint or --lint
- 打印不能向传统unix平台移植的结构的警告。
- -W lint-old or --lint-old
- 打印关于不能向传统unix平台移植的结构的警告。
- -W posix
- 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。
- -W re-interval or --re-inerval
- 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
- -W source program-text or --source program-text
- 使用program-text作为源代码,可与-f命令混用。
- -W version or --version
- 打印bug报告信息的版本。
运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ ~! | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / & | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
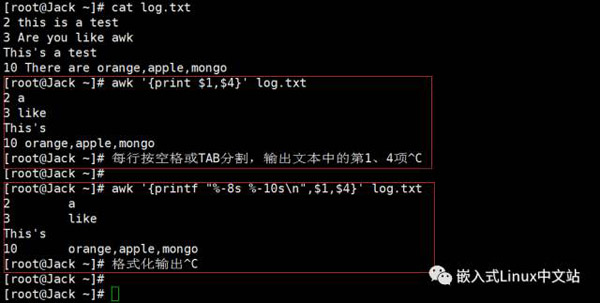
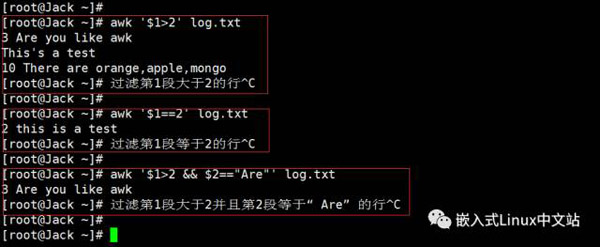
实例1
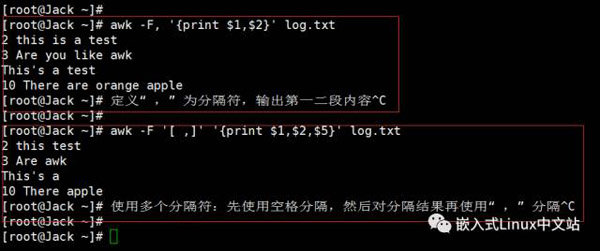
实例2
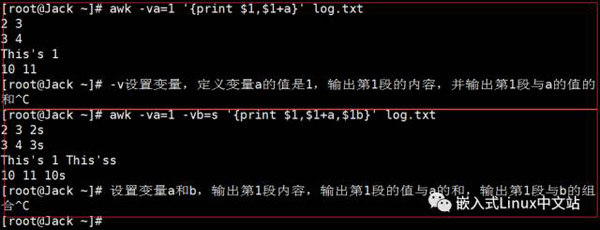
实例3
实例4
内建变量
| 变量 | 描述 |
|---|---|
| \$n | 当前记录的第n个字段,字段间由FS分隔 |
| \$0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 同NR,但相对于当前文件 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 当前记录中的字段数 |
| NR | 当前记录数 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符(默认值是一个空格) |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
实例5
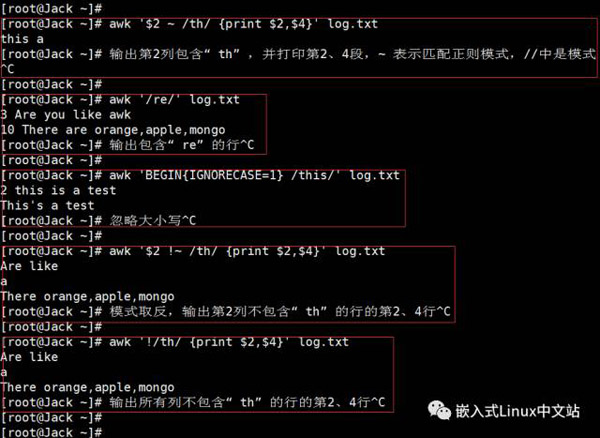
实例6 awk脚本
关于awk脚本,我们需要注意两个关键词BEGIN和END。
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
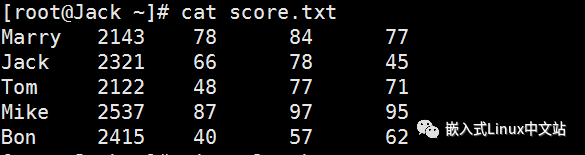
我们的awk脚本如下:
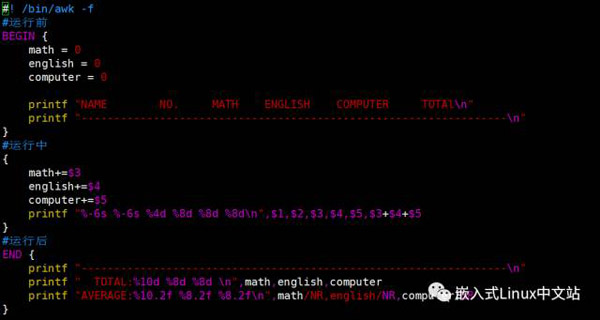
我们来看一下执行结果:
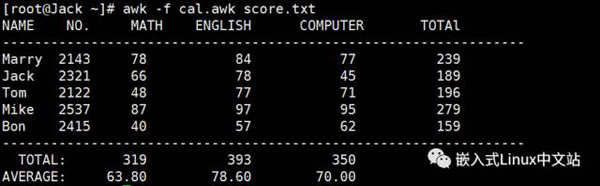
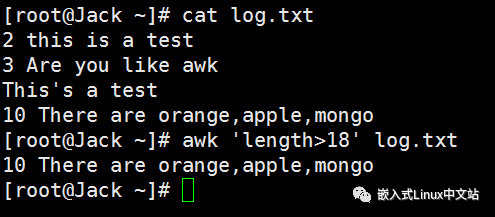
实例7 从文件中找出长度大于18的行
本文作者:佚名
来源:51CTO