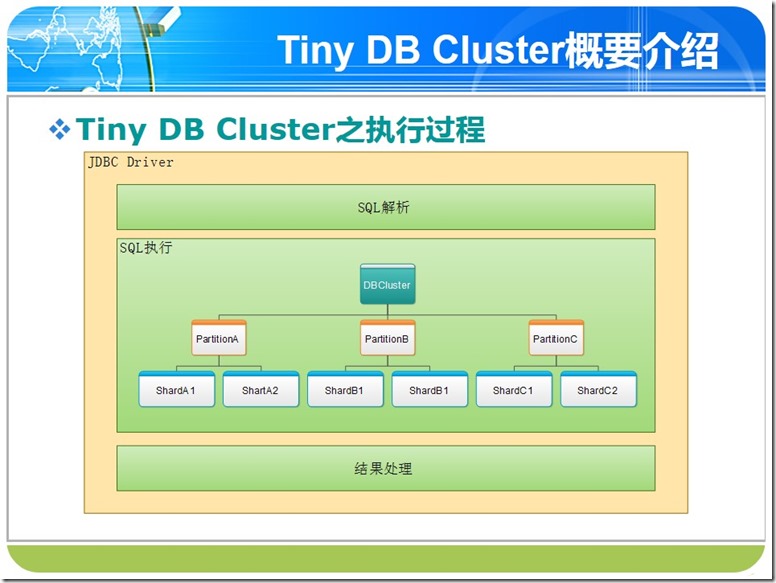
前面有过一篇文章介绍TinyDbRouter,但是当时没有开出来,主要原因是:1偶的粉丝数太少,期望到100的时候,纪念性的发布这个重量级框架,另外一个原因是当时有个编译问题没有完美的解决,偶担心同学们使用的时候不方便--其实偶也不方便,尤其是发布和测试的时候. 现在粉够100了,那个编译问题也顺利的解决了,OK,没有什么理由不快些把它开放给大家. 前面偶起的名字是TinyDBCluster,后来由于有同学们反应说这个与数据库集群歧义,因此还是改成TinyDBRouter了,如果看到两个名字,请