3.2 单链表
在一个单链表中,每个单元格由一个单链路连接到下一个单元格。图3-1所示的链表即是单链表。
如果要使用一个链表,就需要一系列算法来遍历链表、将项添加到链表中、查找链表中的项、删除链表中的项。以下各节将描述一些可能需要使用的算法。
3.2.1 遍历链表
假设一个程序已经建立了一个链表,遍历它的单元格是比较容易的。下面的算法展示了如何遍历链表中的单元格,并使用某种方法对单元格中的值进行处理。本例中使用Print方法来显示单元格的值,但也可以用其他任何方法来代替Print方法对单元格进行操作。
注 这些算法假定参数top是按值传递的,所以该代码可以修改它而不会改变调用代码中的top的值。
该算法开始于一个While循环,只要top单元格指针不为空则该循环就执行。在循环里,该算法调用Print方法显示top单元格的值。然后,top被设置为指向当前top单元格后面的单元格。
这个过程一直进行到top被设置为空指针,此时While循环停止。
该算法将检查链表的每一个单元格,因此如果该列表包含N个单元格,它的运行时间为O(N)。
3.2.2 查找单元格
查找链表中的某个单元格只需要遍历链表直到找到要查找的单元格为止。下面的算法遍历一个链表并返回包含目标值的单元格:
该算法进入一个只要top不为空就执行的While循环。在循环中,该算法将top单元格的值与目标值进行比较。如果值匹配,该算法返回top。如果这两个值不匹配,则该算法将top指向链表的下一个单元格。
如果一直运行到top指针为空,那么目标值不在链表中,这时算法返回空。(另外,该算法可以提示异常,或者增加某些类型的错误,这取决于采用的编程语言。)
下面的章节中将会介绍,在处理链表中某个单元格的时候,如果有一个指向该单元格的前一个单元格的指针,往往会让处理更加容易。下面的算法就是要找到一个包含目标值的单元格的前一个单元格:
此代码与之前的代码类似,但有两处不同。首先,在开始之前它必须检查top不为空,这样它知道可以安全访问top.Next。如果top为空,则top.Next没有被定义,不检查top就会导致算法崩溃。
如果top不为空,则算法进入一个和以前一样的While循环,但这次算法看的是top.Next.Value而不是top.value。当它找到目标值,top指向含有目标值单元格之前的单元格,之后该算法返回top。
3.2.3 使用哨兵
如果仔细研究上述FindCellBefore算法,可能会找到该算法的一个失败之处。如果在链表中的第一个单元格中就包含目标值,但在它之前却没有单元格,因此该算法不能返回它。该算法检查的第一个值位于链表中的第二个单元格,并且它从不回查。
处理这种情况的一种方式是添加专用代码明确地在第一个单元格中寻找目标值然后再特殊处理。该程序可能需要将这种情况作为一个特例处理,这样程序可能会变得混乱。
另一种方法是在列表的开始处创建一个哨兵。一个哨兵是一个单元格,这个单元格是链表的一部分,但不包含任何有意义的数据。它仅作为一个占位符,这样算法就可以找到第一个单元格之前的单元格。
下面的伪代码显示了使用标记修改过的前一个FindCellBefore算法:
此版本并不需要检查top是否为空指针。因为链表至少有一个哨兵,top就不能为空指针。这意味着While循环能够立即开始了。
这个版本也以检查链表中第一个单元格而不是第二个单元格开始,因此它可以检测到其中第一单元包含目标值的情况。
这个版本的算法可以返回第一个真正的单元格(顶端单元格)之前的哨兵。因此,使用该算法的程序不需要其他的代码来处理那种目标值在链表开头的特殊情况。
当搜索一个目标值时,该算法可能很幸运地立即找到这个目标值。但是在最坏的情况下,找到目标值之前它可能需要搜索链表中的绝大部分单元格。如果目标值不在链表中,该算法需要搜索链表中的所有单元格。如果链表中包含N个单元格,这意味着该算法的运行时间为O(N)。
设立一个哨兵似乎是浪费空间,但不再需要特殊用途的代码,这使算法更简单、更优雅。
以下各节假设链表有哨兵并且顶端指针指向哨兵。
3.2.4 在开头添加单元格
链表的一个用途是提供一个可以存储项的数据结构。这有点像一个当需要更多空间时能随时扩展的数组。
将项添加到链表中的最简单的方法是在开头设置一个新单元格,该单元格恰好在哨兵之后。 下面的算法展示了如何在链表的开头增加了一个新的项: 
该算法设置新单元格的Next指针,使它指向原链表中哨兵后的第一个单元格。然后设置哨兵的Next指针指向新的单元格。这样便将新单元格放在了哨兵之后,使它成为链表中新的第一个单元格。
图3-2显示了新单元格在被添加到链表顶端之前和之后的链表。链表的哨兵用阴影部分表示: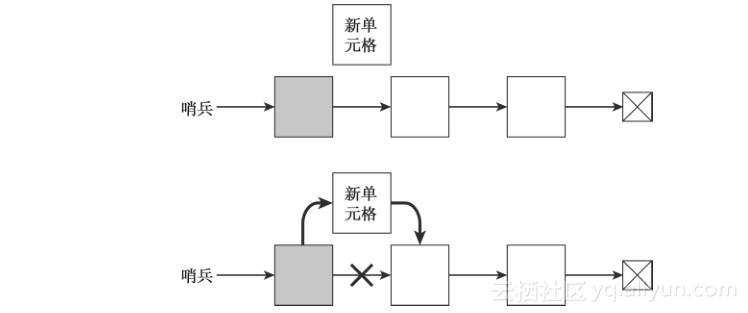
图3-2 在链表的顶端添加一个项,使新单元格的连接点指向链表以前的顶端,然后将哨兵的链接指向新的单元格
该算法只执行两个步骤,所以不管链表中包含多少个单元格,它的运行时间为O(1)。
3.2.5 在结尾添加单元格
在链表末尾添加单元格比在链表开头加入单元格要更加困难,因为该算法需要先遍历链表才能找到最后的单元格。
下面的伪代码显示了在链表末尾添加新单元格的算法:
这段代码遍历整个链表直到它找到最后一个单元格为止,并让最后一个单元格指向新的单元格,然后将新的单元格指向空(null)。
如果链表中没有一个哨兵,此代码将会更加混乱。比如,当该链表为空时,top指针指向null,将不得不使用特殊的代码来处理这种情况。
图3-3展示了以上过程: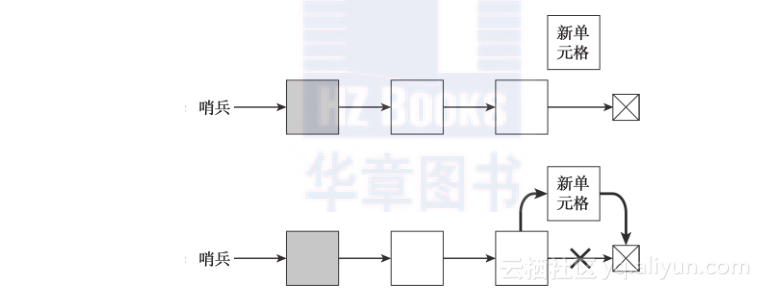
图3-3 要在链表的末尾添加一个项,需要先找到最后一个单元格,并使其链接指向新单元格。然后,使新单元格的链接指向null
该算法必须遍历整个链表,因此,如果该链表包含N个单元格,它的运行时间为O(N)。
3.2.6 在某个单元格后插入单元格
前面的章节解释了如何在链表开头或结尾处添加单元格,但有时可能希望在链表的中间插入一个单元格。假设有一个变量命名为after_me,在它所指向的单元格之后插入新的项,下面的伪代码显示了在after_me之后插入一个单元格的算法:
该算法使新单元格指向after_me之后的单元格,然后让after_me指向新单元格。图3-4展示了该过程:
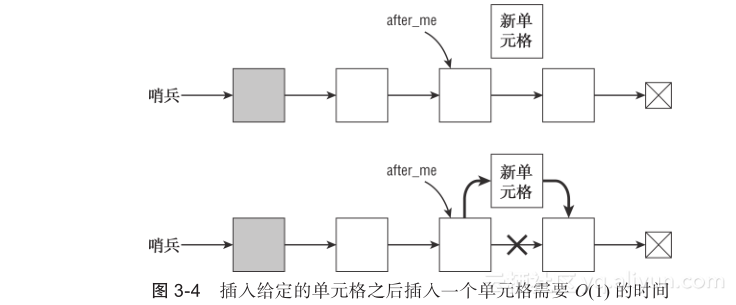
该算法只需要两步,所以它的时间复杂度是O(1),虽然可能需要使用O(N)的时间来寻找单元格after_me。例如,如果要在一个包含目标值的单元格之后插入一个单元格,首先需要找到包含目标值的单元格。
3.2.7 删除单元格
要删除一个目标单元格,只需设置前一个单元格的链接指向目标单元格的下一个单元格。下面的伪代码显示了删除after_me之后的单元格的算法:
图3-5展示了该过程: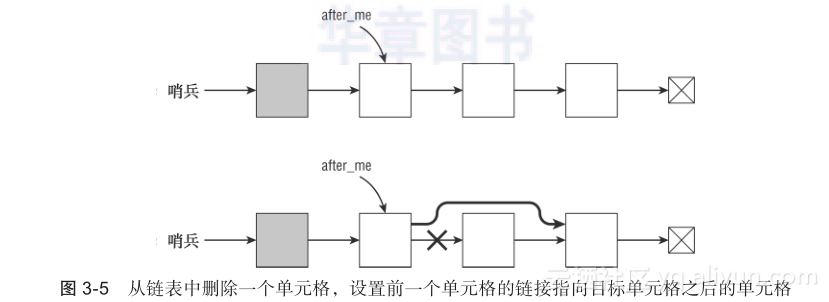
C#和Visual Basic中使用一种有利于内存管理的垃圾回收方案。这意味着,当程序需要更多的存储空间时,被删除的单元格会被自动回收。但根据所使用编程语言,可能需要执行额外的工作来正确释放被删除的单元格。例如,在C++中,可能需要下面的算法来释放目标单元格:

如何删除链表也取决于使用的语言。在C#和Visual Basic中,可以简单地将所有程序使用的链表设置为null,而垃圾收集器最终回收空链表。在一些语言如C++中,当需要显式地释放每个单元格时,需要遍历链表来释放每一个单元格,如下面的伪代码所示:
如何释放资源是与编程语言相关的,所以这本书在本章甚至后面的章节中并没有说任何更多相关的事情。只要知道,当从一个数据结构中删除一个单元格或者其他的东西时,可能需要做一些额外的工作。