1.2 运行ANTLR并测试识别程序
下面是一个简单的、识别类似hello world和hello parrt的词组的语法:
为整洁起见,我们把这个语法文件放到它自己的目录里,如/tmp/test。接下来对该语法文件运行ANTLR命令并编译生成的结果。
对Hello.g4运行ANTLR工具命令生成了一个由HelloParser.java和HelloLexer.java组成的、可以运行的语法识别程序,不过我们还缺一个main程序来触发这个语言识别的过程。(语法分析器和词法分析器的介绍详见下一章。)这就是项目刚开始时的典型过程。在开始构建一个实际的程序之前,你可以先熟悉一下这些不同的语法。无须对每个新的语法都编写一个main程序来测试。
ANTLR在运行库中提供了一个名为TestRig的方便的调试工具。它可以详细列出一个语言类应用程序在匹配输入文本过程中的信息,这些输入文本可以来自文件或者标准输入。TestRig使用Java的反射机制来调用编译后的识别程序。与之前一样,最好通过别名或者批处理文件来调用它。在本书中,我将会使用grun作为别名,你可以使用任何你喜欢的别名。
测试组件有点像是main()方法,接收一个语法名和一个起始规则名作为参数,此外,它还接收众多的参数,通过这些参数我们可以指定输出的内容。假设我们希望显示识别过程中生成的词法符号。词法符号是类似于关键字hello和标识符parrt的符号。可以通过以下命令启动grun,测试之前的语法:
首先输入上述grun命令,回车,然后输入hello parrt,回车。这个时候,你必须手动输入文件结束符(end-of-file character)来阻止程序继续读取标准输入,否则,程序将什么都不做,静静等待你的下一步输入。由于grun命令使用了-tokens选项,一旦识别程序读取到全部的输入内容,TestRig就会打印出全部的词法符号的列表。
每行输出代表了一个词法符号,其中包含了该词法符号的全部信息。例如,[@1, 6:10 = 'parrt', <2>, 1:6]表明,这个词法符号位于第二个位置(从0开始计数),由输入文本的第6个到第10个位置之间的字符组成(包含第6个和第10个,同样从0开始计数);包含的文本内容是parrt;词法符号类型是2(即ID);位于输入文本的第一行、第6个位置处(从0开始计数,tab符号被看作一个字符)。
我们可以很容易地打印出LISP风格文本格式的语法分析树(根节点和子节点在同一行)。
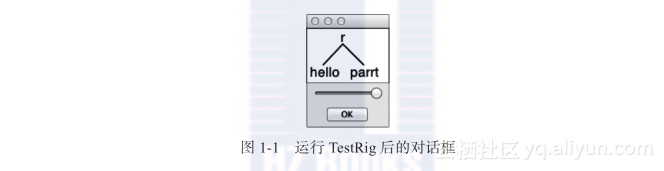
要想知道识别程序是如何识别输入文本的,最简单的办法是查看可视化的语法分析树。使用grun-gui运行TestRig,即grun Hello r-gui,将产生如图1-1所示的对话框。
当不带参数地运行TestRig时,会产生一些帮助信息: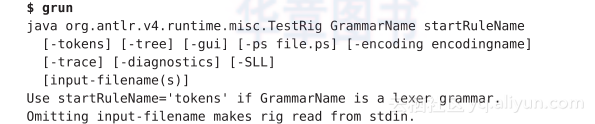
在本书中,我们将会使用其中的很多选项,下面是它们的简单介绍:
-tokens 打印出词法符号流。
-tree 以LISP格式打印出语法分析树。
-gui 在对话框中以可视化方式显示语法分析树。
-ps file.ps 以PostScript格式生成可视化语法分析树,然后将其存储于file.ps。本章中的语法分析树的图片就是使用-ps选项生成的。
-encoding encodingname 若当前的区域设定无法正确读取输入,使用这个选项指定测试组件输入文件的编码。例如,在12.4节中我们需要通过这个选项来解析日语XML文件。
-trace 打印规则的名字以及进入和离开该规则时的词法符号。
-diagnostics 开启解析过程中的调试信息输出。通常仅在一些罕见情况下才使用它产生信息,例如输入的文本有歧义。
-SLL 使用另外一种更快但是功能稍弱的解析策略。
现在,我们已经成功地安装了ANTLR,并尝试着用它分析了一个简单的语法。在下一章中,让我们后退一步,先纵观全局,学习一些重要的术语。之后,我们将会尝试建立一个简单的入门工程来识别和翻译一列形如{1, 2, 3}的数字。接下来,在第4章中我们将会学习一系列有趣的例子,这些例子展示了ANTLR的强大功能以及可被应用的领域。