背景
之前的文章《阿里云容器服务测评》就高可用零宕机方面对容器服务作了详细测评,本文我们介绍一下小博无线目前的线上环境,Mesos+Marathon,是如何做到高可用零宕机的。
Marathon
Marathon作为Mesos的容器调度框架,本身就提供了非常可靠的高可用方案:
- 自身的High Availability Mode保证了单点故障时,依然能够提供服务
- 蓝绿部署机制在新版容器健康之后再停止旧版容器,确保新旧服务平滑切换
- 当容器健康检查持续失败,Marathon会将其kill,并启动新的容器
但这些还不够,因为:
- 容器可能被部署到集群内任意节点上,已有的容器也会漂移到其它节点。对于新增/停止的节点,该如何在对应的SLB中添加/移除节点
- 新版容器启动后,Marathon只能判断容器本身的健康状态,无从知道该容器对应的SLB状态是否健康。如果在SLB的新节点还处于异常状态时就将旧版容器停止,则会出现服务短时不可用的故障
- 停止容器会使其正在处理的请求被终止,并且,从停止容器到SLB感知到节点异常,需要一定时间,这段时间被分发到已停止节点的请求也无法被正常处理
- Marathon不支持动态伸缩
在阿里云上使用Marathon,基本上都会遇到这四个问题。下面介绍我们是如何解决这些问题的。
添加/移除SLB节点
我们利用Marathon的Event Bus机制来解决这个问题,启动Marathon时,可以配置一个HTTP回调地址,当某些特定的事件发生时,Marathon通知回调地址。
我们部署了一个基于golang web server的运维服务平台(osp),在上面实现了这个回调接口。该接口订阅status_update_event事件,并判断taskStatus的值。如果taskStatus是TASK_RUNNING,那么就添加对应节点到SLB;如果是[TASK_FINISHED, TASK_KILLED, TASK_LOST, TASK_FAILED],则从SLB中移除对应的后端节点。
获取SLB状态
如何让Marathon的健康检查获取到SLB的状态?我们的设计是通过添加一个负责查询SLB状态的中间层,并让健康检查请求这个中间层。
Marathon支持三种模式的健康检查:
- TCP
- HTTP
- COMMAND
其中TCP和HTTP只能请求容器内的端口,COMMAND则可以设置为任意shell命令。我们在osp上实现了这样一个接口:查询SLB状态,如果状态为『正常』,缓存结果下次不再查询,否则每次都调用SLB API进行查询。之所以缓存查询结果,是因为SLB Health API很慢,而且有调用次数的限制。最后使用COMMAND健康检查请求这个接口。配置如下:
"protocol": "COMMAND",
"command": {
"value": "curl -v -f --request POST 'http://osp/health_check' --data 'host=$HOST' --data 'service_name=$MARATHON_APP_ID' --data 'mesos_task_id=$MESOS_TASK_ID'"
},
"gracePeriodSeconds": 200,
"intervalSeconds": 30,
"timeoutSeconds": 10,
"maxConsecutiveFailures": 5,
第一版的整个流程如图:
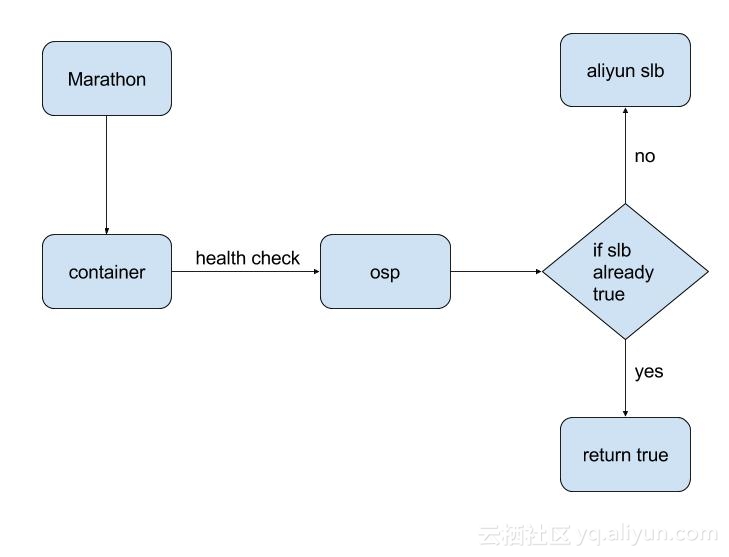
这个流程存在以下不足:
- 中间层缓存了SLB检查结果,在SLB状态正常后不会继续查询,所以导致Marathon获取不到容器本身的健康状态。即使容器内服务出错,Marathon依然认为它是健康的
- 这应该算是Marathon的一个bug,如果leader节点宕机,那么所有COMMAND模式的服务的健康状态会变为
unknown状态
因此我们又加入了一个中间层,它是一个部署在容器中的golang web server,做下面两件事情:
- 调用运维平台API,返回结果
- 如果运维平台API返回结果为『健康』,缓存结果,不再请求运维平台,改为请求容器内服务自身的OK API,返回结果
由于web server位于容器内部,健康检查可以由COMMAND模式改为HTTP模式,这样就很好地解决了上面碰到的两个问题。虽然增加了些复杂度,需要在每个容器中嵌入这个web server,但可以将这一步固化在最底层的base image中,而且其硬件开销几乎可以忽略不计(不到2M内存)。
最终的流程如下:
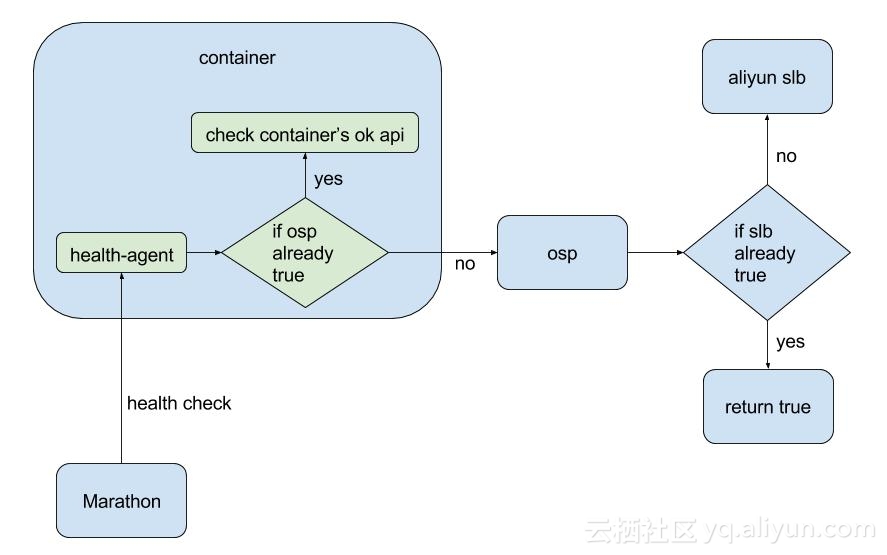
停止容器前通知SLB
这个问题我们起初期望通过Event Bus来解决:
- 设置Mesos的
executor_shutdown_grace_period和docker_stop_timeout参数。如果容器收到SIGTERM信号后迟迟不停止,一分钟后再发送SIGKILL信号强制停止容器 - 在容器内捕获
SIGTERM信号,让容器在收到kill命令后不退出,继续提供服务 - 订阅Marathon的Event,在
taskStatus==TASK_KILLED时将后端节点权重置为0
测试发现这个方案不可行,原因是Marathon并不是在第一次向容器发送SIGTERM信号时,而是在发送SIGKILL信号将容器强制停止后,才触发taskStatus==TASK_KILLED事件,
最终的方案为,在容器中捕获SIGTERM信号,之后通知运维平台容器即将被停止,运维平台收到请求后将该容器在SLB的权重设为0。通过设置executor_shutdown_grace_period和docker_stop_timeout参数为容器从收到SIGTERM信号到被强制停止之间留出一分钟,这部分时间用于SLB的断流以及容器对已有请求的处理的平滑切换。
我们在最底层的镜像中创建了服务的运行框架,其中一个python进程会将指定的所有服务启动起来。因此我们只要在这个python进程中捕获SIGTERM信号并通知运维平台即可解决问题。
signal.signal(signal.SIGTERM, lambda signum, frame: shutdown_grace())
一年多的线上实战表明,这套解决方案是非常可靠的。无论是部署、重启、还是停止容器,都可以做到无感知平滑漂移。
动态伸缩
解决了上面和SLB有关的三个问题后,能够解决容器的启动与停止过程中对服务质量的影响。但在容器运行中,依然有可能发生影响服务的情况,例如负载的变化。
Marathon支持对每个容器配置不同的资源(CPU、内存、磁盘),也可以选择不配置,让所有容器共用ECS资源,但建议尽量不要这么做,这种做法虽然简单,可是风险很高,让单个服务也有可能耗光ECS上的CPU或内存资源,进而影响到部署在ECS上所有服务的服务质量。
合理的资源配置参数不应是静态的,而应随着负载的变化而动态地伸缩。这里的伸缩,分为两个方面:
- 横向地伸缩容器的数量
- 纵向地伸缩容器的配额
然而,Marathon并不原生支持动态地伸缩容器。为了解决这个问题,我们制作了运维机器人TidyMaid,用于采集、分析每个容器负载,判断是横向还是纵向地伸缩服务。大致的方案为:
- CPU负载超限,横向伸缩服务,直至容器数量达到设定的上限或下限
- 内存负载超限,如果容器已经运行超过一段时间,那么直接将超限的容器停止(停止后Marathon会自动启动新容器);否则纵向地伸缩服务,直至容器配额已经达到设定的上限或下限
该方案背后的考虑是,CPU负载的变化,一般和流量压力紧密关联,压力的变化会立即反映在CPU负载上,横向伸缩能立即适配流量压力;但是内存则不然,某些时候,内存负载升高,仅靠增加容器个数并不能解决问题。虽然增加容器使每个容器的请求压力降低,但对于内存已经居高的容器,其负载并不会立即下降,所以选择直接停止服务或者纵向伸缩(纵向伸缩会重启服务)。
这样做了之后,服务在任意时刻都会处于一个合理的配置,既能负担高峰期的压力,又不至于闲置过多的资源。
可见,无感知平滑漂移是一个容器调度服务系统的必备功能。只有实现了平滑漂移,才有可能落地快速迭代开发方式,每天线上发版数十次;只有实现了平滑漂移,运维机器人才能放开手脚,自由的重启状态异常的容器,合理的调整容器的配额,更好的为实现高可用零宕机服务!