1.4 使用计算机执行贝叶斯推断
接下来模拟一个有趣的实例,它是一个有关用户发送和收到短信的例子。
1.4.1 实例:从短信数据推断行为
你得到了系统中一个用户每天的短信条数数据,如图1.4.1中所示。你很好奇这个用户的短信使用行为是否随着时间有所改变,不管是循序渐进地还是突然地变化。怎么模拟呢?(这实际上是我自己的短信数据。尽情地判断我的受欢迎程度吧。)
figsize(12.5, 3.5)
count_data = np.loadtxt("data/txtdata.csv")
n_count_data = len(count_data)
plt.bar(np.arange(n_count_data), count_data, color="#348ABD")
plt.xlabel("Time (days)")
plt.ylabel("Text messages received")
plt.title("Did the user's texting habits change over time?")
plt.xlim(0, n_count_data);```
<div style="text-align: center"><img src="https://yqfile.alicdn.com/7d3b678ca688c4e3eb496ba7517beadd86cb1bb0.png" width="" height="">
</div>
在建模之前,仅仅从图1.4.1中你能猜到什么吗?你能说在这一段时间内用户行为出现了什么变化吗?
我们怎么模拟呢?像前文提到的那样,Possion随机变量能很好地模拟这种计数类型的数据。用Ci表示第i天的短信条数。
<div style="text-align: center">
Ci~Poi(λ)
</div>
我们不能确定参数λ的真实取值,然而,在图1.4.1中,整个观察周期的后期收到短信的几率升高了,也可以说,λ在某些时段增加了(在前文中有提到过,当λ取大值的时候更容易得到较大的结果值。在这里,也就是说一天收到短信条数比较多的概率增大了)。
怎么用数据表示这种观察呢?假设在观察期的某些天(称它为τ),参数λ的取值突然变得比较大。所以参数λ存在两个取值:在时段τ之前有一个,在其他时段有另外一个。在一些资料中,像这样的一个转变称之为转换点:
<div style="text-align: center"><img src="https://yqfile.alicdn.com/2e77fcb58e9a3056f995de86d2656960f5f6f19d.png" width="" height="">
</div>
如果实际上不存在这样的情况,即λ1=λ2,那么λ的先验分布应该是均等的。
对于这些不知道的λ我们充满了兴趣。在贝叶斯推断下,我们需要对不同可能值的λ分配相应的先验概率。对参数λ1和λ2来说什么才是一个好的先验概率分布呢?前面提到过λ可以取任意正数。像我们前面见到的那样,指数分布对任意正数都存在一个连续密度函数,这或许对模拟λi来说是一个很好的选择。但也像前文提到的那样,指数分布也有它自己对应的参数,所以这个参数也需要包括在我们的模型里面。称它为参数α。
<div style="text-align: center">
λ1~Exp(α)
λ2~Exp(α)
</div>
α被称为超参数或者是父变量。按字面意思理解,它是一个对其他参数有影响的参数。按照我们最初的设想,α应该对模型的影响不会太大,所以可以对它进行一些灵活的设定。在我们的模型中,我们不希望对这个参数赋予太多的主观色彩。但这里建议将其设定为样本中计算平均值的逆。为什么这样做呢?既然我们用指数分布模拟参数λ,那这里就可以使用指数函数的期望值公式得到:
<div style="text-align: center">
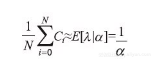
</div>
使用这个值,我们是比较客观的,这样做的话可以减少超参数对模拟造成的影响。另外,我也非常建议大家对上面提到的不同时段的两个λi使用不同的先验。构建两个不同α值的指数分布反映出我们的先验估计,即在整个观测过程中,收到短信的条数出现了变化。
对于参数τ,由于受到噪声数据的影响,很难为它挑选合适的先验。我们假定每一天的先验估计都是一致的。用公式表达如下:
<div style="text-align: center">
τ~DiscreteUniform(1,70)
=﹥P(τ=k)=1/70
</div>
做了这么多了,那么未知变量的整体先验分布情况应该是什么样的呢?老实说,这并不重要。我们要知道的是,它并不好看,包括很多只有数学家才会喜欢的符号。而且我们的模型会因此变得更加复杂。不管这些啦,毕竟我们关注的只是先验分布而已。
下面会介绍PyMC,它是一个由数学奇才们建立起来的关于贝叶斯分析的Python库。
####1.4.2 介绍我们的第一板斧:PyMC
PyMC是一个做贝叶斯分析使用的Python库。它是一个运行速度快、维护得很好的库。它唯一的缺点是,它的说明文档在某些领域有所缺失,尤其是在一些能区分菜鸟和高手的领域。本书的主要目标就是解决问题,并展示PyMC库有多酷。
下面用PyMC模拟上面的问题。这种类型的编程被称之为概率编程,对此的误称包括随机产生代码,而且这个名字容易使得使用者误解或者让他们对这个领域产生恐惧。代码当然不是随机的,之所以名字里面包含概率是因为使用编译变量作为模型的组件创建了概率模型。在PyMC中模型组件为第一类原语。
Cronin对概率编程有一段激动人心的描述:
“换一种方式考虑这件事情,跟传统的编程仅仅向前运行不同的是,概率编程既可以向前也可以向后运行。它通过向前运行来计算其中包含的所有关于世界的假设结果(例如,它对模型空间的描述),但它也从数据中向后运行,以约束可能的解释。在实践中,许多概率编程系统将这些向前和向后的操作巧妙地交织在一起,以给出有效的最佳的解释。
由于“概率编程”一词会产生很多不必要的困惑,我会克制自己使用它。相反,我会简单地使用“编程”,因为它实际上就是编程。
PyMC代码很容易阅读。唯一的新东西应该是语法,我会截取代码来解释各个部分。只要记住我们模型的组件(τ,λ1,λ2)为变量:import pymc as pm
alpha = 1.0/count_data.mean()# Recall that count_data is the
# variable that holds our text counts.lambda_1 = pm.Exponential("lambda_1", alpha)
lambda_2 = pm.Exponential("lambda_2", alpha)
tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data)`
在这段代码中,我们产生了对应于参数λ1和λ2的PyMC变量,并令他们为PyMC中的随机变量,之所以这样称呼它们是因为它们是由后台的随机数产生器生成的。为了表示这个过程,我们称它们由random()方法构建。在整个训练阶段,我们会发现更好的tau值。
print "Random output:", tau.random(), tau.random(), tau.random()
[Output]:
Random output: 53 21 42
@pm.deterministic
def lambda_(tau=tau, lambda_1=lambda_1, lambda_2=lambda_2):
out = np.zeros(n_count_data) # number of data points
out[:tau] = lambda_1 # lambda before tau is lambda_1
out[tau:] = lambda_2 # lambda after (and including) tau is
# lambda_2
return out```
这段代码产生了一个新的函数lambda_,但事实上我们可以把它想象成为一个随机变量——之前的随机参数λ。注意,因为lambda_1、lambda_2、tau是随机的,所以lambda_也会是随机的。目前我们还没有计算出任何变量。
@pm.deterministic是一个标识符,它可以告诉PyMC这是一个确定性函数,即如果函数的输入为确定的话(当然这里它们不是),那函数的结果也是确定的。observation = pm.Poisson("obs", lambda_, value=count_data,
observed=True)
model = pm.Model([observation, lambda_1, lambda_2, tau])`
变量observation包含我们的数据count_data,它是由变量lambda_用我们的数据产生机制得到。我们将observed设定为True来告诉PyMC这在我们的分析中是一个定值。最后,PyMC 希望我们收集所有变量信息并从中产生一个Model实例。当我们拿到结果时就会比较好处理了。
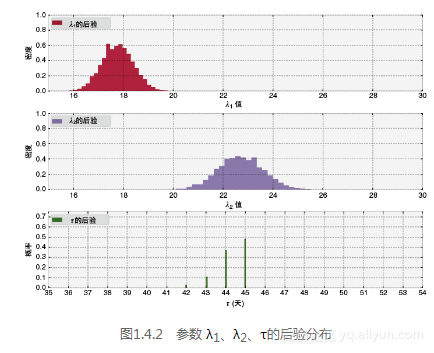
下面的代码将在第3章中解释,但在这里我们展示我们的结果是从哪里来的。可以把它想象成为一个不断学习的过程。这里使用的理论称为马尔科夫链蒙特卡洛(MCMC),在第3章中会给出进一步的解释。利用它可以得到参数λ1、λ2和τ先验分布中随机变量的阈值。我们对这些随机变量作直方图,观测他们的先验分布。接下来,将样本(在MCMC中我们称之为迹)放入直方图中。结果如图1.4.2所示。
# Mysteri-ous code to be explained in Chapter 3. Suffice it to say,
# we will get
# 30,000 (40,000 minus 10,000) samples back.
mcmc = pm.MCMC(model)
mcmc.sample(40000, 10000)
[Output]:
[-----------------100%-----------------] 40000 of 40000 complete
in 9.6 sec
lambda_1_samples = mcmc.trace('lambda_1')[:]
lambda_2_samples = mcmc.trace('lambda_2')[:]
tau_samples = mcmc.trace('tau')[:]
figsize(14.5, 10)
# histogram of the samples
ax = plt.subplot(311)
ax.set_autoscaley_on(False)
plt.hist(lambda_1_samples, histtype='stepfilled', bins=30, alpha=0.85,
la-bel="posterior of $\lambda_1$", color="#A60628", normed=True)
plt.legend(loc="upper left")
plt.title(r"""Posterior distributions of the parameters\
$\lambda_1,\;\lambda_2,\;\tau$""")
plt.xlim([15, 30])
plt.xlabel("$\lambda_1$ value")
plt.ylabel("Density")
ax = plt.subplot(312)
ax.set_autoscaley_on(False)
plt.hist(lambda_2_samples, histtype='stepfilled', bins=30, alpha=0.85,
la-bel="posterior of $\lambda_2$", color="#7A68A6", normed=True)
plt.legend(loc="upper left")
plt.xlim([15, 30])
plt.xlabel("$\lambda_2$ value")
plt.ylabel("Density")
plt.subplot(313)
w = 1.0 / tau_samples.shape[0] * np.ones_like(tau_samples)
plt.hist(tau_samples, bins=n_count_data, alpha=1,
la-bel=r"posterior of $\tau$", color="#467821",
weights=w, rwidth=2.)
plt.xticks(np.arange(n_count_data))
plt.legend(loc="upper left")
plt.ylim([0, .75])
plt.xlim([35, len(count_data)-20])
plt.xlabel(r"$\tau$ (in days)")
plt.ylabel("Probability");```
<div style="text-align: center">
</div>
####1.4.3 说明
回想一下,贝叶斯方法返回一个分布。因此,我们现在有分布描述未知的λ和τ。我们得到了什么?马上,我们可以看我们估计的不确定性:分布越广,我们的后验概率越小。我们也可以看到参数的合理值:λ1大概为18,λ2大概是23。这两个λ的后验分布明显是不同的,这表明用户接收短信的行为确实发生了变化。(请参阅1.6补充说明中的正式参数。)
你还能做哪些其他的观测呢?再看看原始数据,你是否觉得这些结果合理呢?
还要注意到λ的后验分布并不像是指数分布,事实上,后验分布并不是我们从原始模型中可以辨别的任何分布。但这挺好的!这是用计算机处理的一个好处。如果我们不这么做而改用数学方式处理这个问题,将会非常的棘手和混乱。使用计算数学的方式可以让我们不用在方便数学处理上考虑太多。
我们的分析页返回了τ的一个分布。由于它是一个离散变量,所以它的后验看起来和其他两个参数有点不同,它不存在概率区间。我们可以看到,在45天左右,有50%的把握可以说用户的行为是有所改变的。没有发生变化,或者随着时间有了慢慢的变化,τ的后验分布会更加的分散,这也反映出在很多天中τ是不太好确定的。相比之下,从真实的结果中看到,仅仅有三到四天可以认为是潜在的转折点。
####1.4.4 后验样本到底有什么用?
在这本书的其余部分,我们会面对这样一个问题,它是一个能带领我们得到强大结果的说明。现在,用另外一个实例结束这一章。
我们会用后验样本回答下面的问题:在第t(0≤t≤70)天中,期望收到多少条短信呢?Poisson分布的期望值等于它的参数λ。因此问题相当于:在时间t中,参数λ的期望值是多少。
在下面的代码中,令i指示后验分布中的变量。给定某天t,我们对所有可能的λ求均值,如果 t < τi (也就是说,如果并没有发生什么变化),令λi=λ1,i,否则我们令λi = λ2,i。figsize(12.5, 5)
tau_samples, lambda_1_samples, lambda_2_samples contain
N samples from the corresponding posterior distribution.
N = tau_samples.shape[0]
expected_texts_per_day = np.zeros(n_count_data) # number of data points
for day in range(0, n_count_data):
ix is a bool index of all tau samples corresponding to
the switchpoint occurring prior to value of "day."
ix = day < tau_samples
Each posterior sample corresponds to a value for tau.
For each day, that value of tau indicates whether we're
"before"
(in the lambda 1 "regime") or
"after" (in the lambda 2 "regime") the switchpoint.
By taking the posterior sample of lambda 1/2 accordingly,
we can average
over all samples to get an expected value for lambda on that day.
As explained, the "message count" random variable is
Poisson-distributed,
and therefore lambda (the Poisson parameter) is the expected
value of
"message count."
expected_texts_per_day[day] = (lambda_1_samples[ix].sum()\
+ lambda_2_samples[˜ix].sum()) / N
plt.plot(range(n_count_data), expected_texts_per_day, lw=4,
col-or="#E24A33", label="Expected number of text messages\
received")plt.xlim(0, n_count_data)
plt.xlabel("Day")
plt.ylabel("Number of text messages")
plt.title("Number of text messages received versus expected number\
received")plt.ylim(0, 60)
plt.bar(np.arange(len(count_data)), count_data, color="#348ABD",
al-pha=0.65, label="Observed text messages per day")plt.legend(loc="upper left")
print expected_texts_per_day
[Output]:
[ 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707
17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707
17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707
17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707 17.7707
17.7707 17.7707 17.7707 17.7708 17.7708 17.7712 17.7717 17.7722
17.7726 17.7767 17.9207 18.4265 20.1932 22.7116 22.7117 22.7117
22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117
22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117
22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117 22.7117
22.7117 22.7117]
在图1.4.3中展示的结果,很明显地说明了转折点的重要影响。但是对此我们应该保持谨慎的态度,从这个观点看,这里并不存在我们非常希望看到的“短信的期望数量”这样的一条直线。我们的分析结果非常符合之前的估计——用户行为确实发生了改变(如不然,λ1和λ2的值应该比较接近),而且这是一个突然的变化,而非一种循序渐进的变化(τ的先验分布突然出现了峰值)。我们可以推测这种情况产生的原因是:短信费用的降低,天气提醒短信的订阅,或者是一段新的感情。
<div style="text-align: center">
