TL;DR
MySQL 5.7为了提升只读事务的性能改进了MVCC机制,虽然在只读场景下能获得很好的收益,但是在读写混合的高并发场景下却带来了性能劣化,导致的结果就是rt飙升和业务端超时。本文剖析了此问题背后的原因,并给出了解决办法。
引言
MySQL 5.7自发布以来备受关注,不仅是因为5.7的在功能特性上大大丰富,它的读写性能上相对于之前的版本也有了很大提升。正是由于5.7卓越的表现,我们自去年起就开始着手将AliSQL整体搬迁到5.7上。然而经过一年多的整合测试我们发现,5.7宣称的有些能力表现却不尽如人意。这里面当然有很多有趣的故事可以讲,本文要讲的这个故事却是对MySQL 5.7引以为傲的“高并发高性能”的一个很好的回应。
自MySQL从4.0发展演进到现在的8.0,高并发场景下MySQL的性能越来越强,以下是dimitrik针对MySQL的多个版本做的性能对比测试。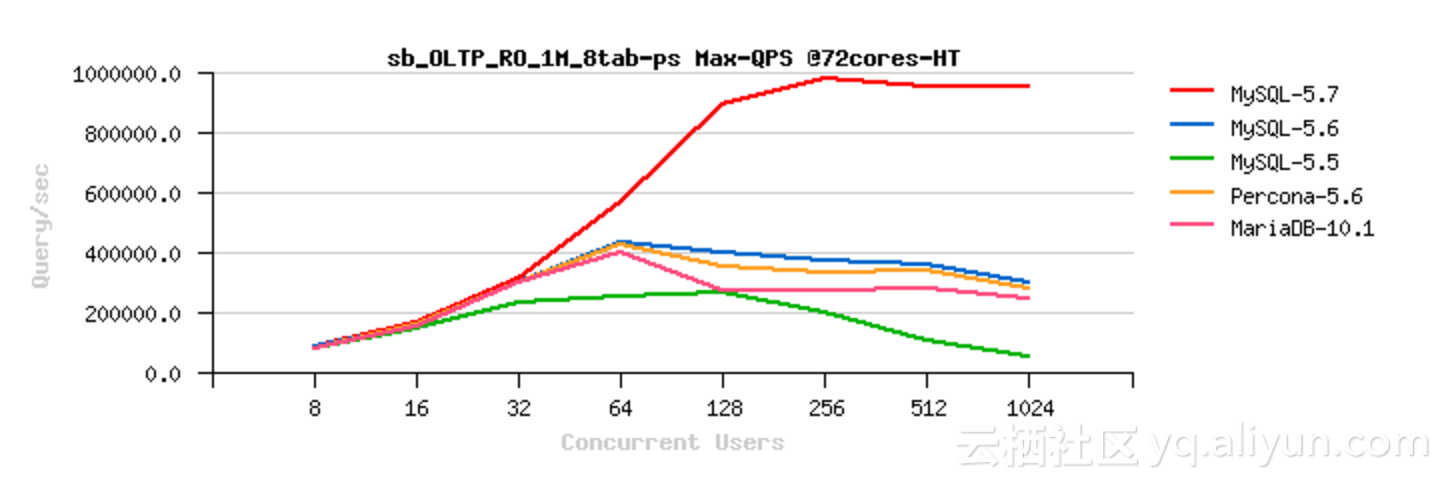
可以看到MySQL 5.7的读能力有了很大的提升,这是因为它针对读性能做了很多优化,其中就包括了InnoDB引擎层MVCC机制的改进。本文要介绍的性能退化问题就和这个MVCC机制的改进密切相关。
背景介绍
在说明问题之前有必要交代一下InnoDB的多版本控制(MVCC),与MVCC密切相关的是快照读。所谓快照读既是无锁读,那么它是用来解决什么样问题的?
我们知道InnoDB是一个支持事务的引擎,事务的一个重要特性是隔离性,即还未提交的事务的修改对外界是不可见的。为了实现事务隔离性数据库一般使用两种实现手段,分别是当前读和快照读。
所谓当前读就是加锁读,事务对访问的数据进行加锁,事务提交时释放所持有的锁。由于锁的互斥性,正在被活跃事务修改的数据无法被其它事务访问,必须等到修改它的事务提交。这种方式的优点是实现简单,但缺点也很明显,并发性能差。
而快照读的特点是多个事务访问相同数据时不需要加锁,可以并发执行。具体做法是一份数据保存多个历史版本,不同事务访问不同历史版本的数据彼此之间互不影响。不过快照读也有一个明显的缺点,那就是事务对数据只能读不能修改。
InnoDB的事务在修改一份数据时对其进行加锁读,而只读不改数据的时候进行快照读,最大限度的提高事务的并发性能。
再来讲讲快照读的具体实现,这里涉及到几个问题:1,历史版本如何保存;2,如何拿到正确版本的历史数据;3,历史数据如何回收。
数据的历史版本有两种保存方法:一种保存全量的历史数据,另一种保存能够回滚到历史数据的undo日志。InnoDB采用的是后一种方式,事务更新数据同时产生一份对应的undo日志,并且日志中记录了事务id。
事务使用快照(readview)去读取数据正确的历史版本,快照中包含的信息是当前所有活跃事务的id。开始读之前分配一个快照(read-committed和repeatable-read隔离级别下快照分配方式略有不同),实际就是对当前所有的活跃事务做了个快照。在读取数据过程中,由于需要通过undo日志构造历史版本,而每个undo日志有一个事务id,对比undo日志中的事务id和readview中的事务id就可以判断历史版本是否可见。说直白点就是,快照创建的那一刻生成这份历史数据的事务是已提交状态(可见)还是未提交(不可见)。
最后,历史数据是需要回收的,不然undo日志占用的空间会越来越大。InnoDB回收历史数据的任务由后台purge线程完成,回收的原则是:只能回收那些永远不会再被用到的undo日志。具体做法是:purge线程从当前所有readview中找到创建时间最久的那个oldest readview,那些比oldest readview还要旧的undo日志就是可以被安全回收的。因此,InnoDB维护了一个全局的readview链表,链表中的readview按照创建时间排序,purge线程只须找到链表尾端的readview就是oldest readview。
5.7的改进
根据上面的介绍可以知道,事务进行一次快照读的步骤如下:
1. 分配一个快照对象
2. 将快照对象加入到全局readview链表头部
3. 对当前活跃事务打快照
3. 进行快照读
4. 完成后,将快照对象从全局readview链表中移除
需要说明的是,rr隔离级别下每个事务使用一个快照,而rc隔离级别下每条query使用一个readview,所以快照的分配和释放与事务的开始和结束不完全对应。
同时,后台purge线程进行一次purge操作的过程是
1. 从全局readview链表中找到oldest readview
2. 使用oldest readview去回收undo日志
看到这里可以很清楚的明白一件事:必定存在一把锁保护全局readview链表。没错,这把锁就是InnoDB事务系统的全局大锁(trx_sys->mutex)。这把大锁不光保护了全局的readview链表,还保护了全局的活跃事务链表等对象,事务在begin和commit等过程中也要竞争这把大锁,所以这是一把比较热的锁。
为了减少这把锁的争用,MySQL 5.7对一些特定场景做了优化。比如对于autocommit的只读事务,优化了readview的创建过程。优化的原理是:如果上次快照读与这次快照读之间没有写事务发生,那么一定也没有任何数据被修改,所以理论上可以直接复用上次的readview,这样做能够很大程度减少事务系统全局锁的争用开销。
根据WL#6578的描述,优化后只读事务快照读的步骤如下:
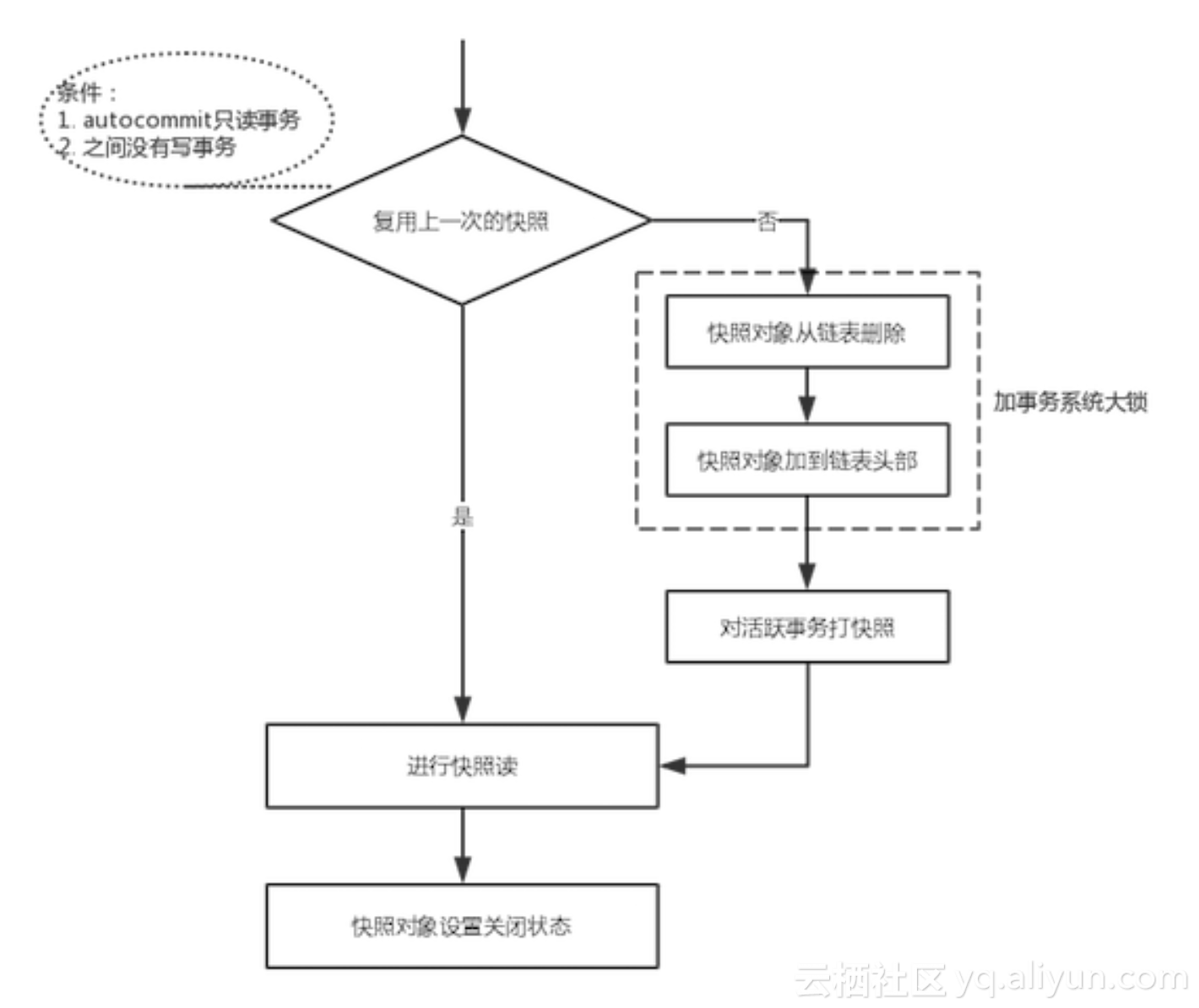
改进之后,autocommit只读事务完成快照读后,并不会将快照从全局readview链表中删除,而只是将它设置成close状态。再次进行快照读时,如果可以复用上次的快照则不需要操作全局readview链表,自然也不需要争用事务系统全局锁。而如果不能复用快照,依然需要操作全局readview链表,但是相对于改进前少了一次全局事务锁的争用。根据前面dimitrik做的5.6与5.7只读事务性能比较对比测试图,可以看到只读场景下5.7性能有了飞跃提升。
带来的问题
这样优化之后虽然对autocommit的只读事务的性能友好,但是某些场景下反而带来了性能劣化。为什么这么讲呢?因为我们实实在在踩到了这个坑!
让我们从原理上分析性能劣化的原因,这样修改之后虽然autocommit只读事务减少了对全局readview链表的操作,但是全局readview链表中却多出了很多close状态的readview,链表长度无端变长了!!
这样带来的最直接的影响是purge线程在获取oldest readview的开销变大了。之前只要获取全readview最末尾的readview就是oldest readview,但是修改之后需要从全局readview链表末端往前遍历,直到
找到第一个非close状态的readview。
在我们的业务场景下有非常多autocommit的query语句,这些query查询就是一个个的autocommit只读事务,因此它们提交时readview会留在全局readview链表中。下图是我们在全链路压测时一个业务节点上抓取的全局readview链表的长度。
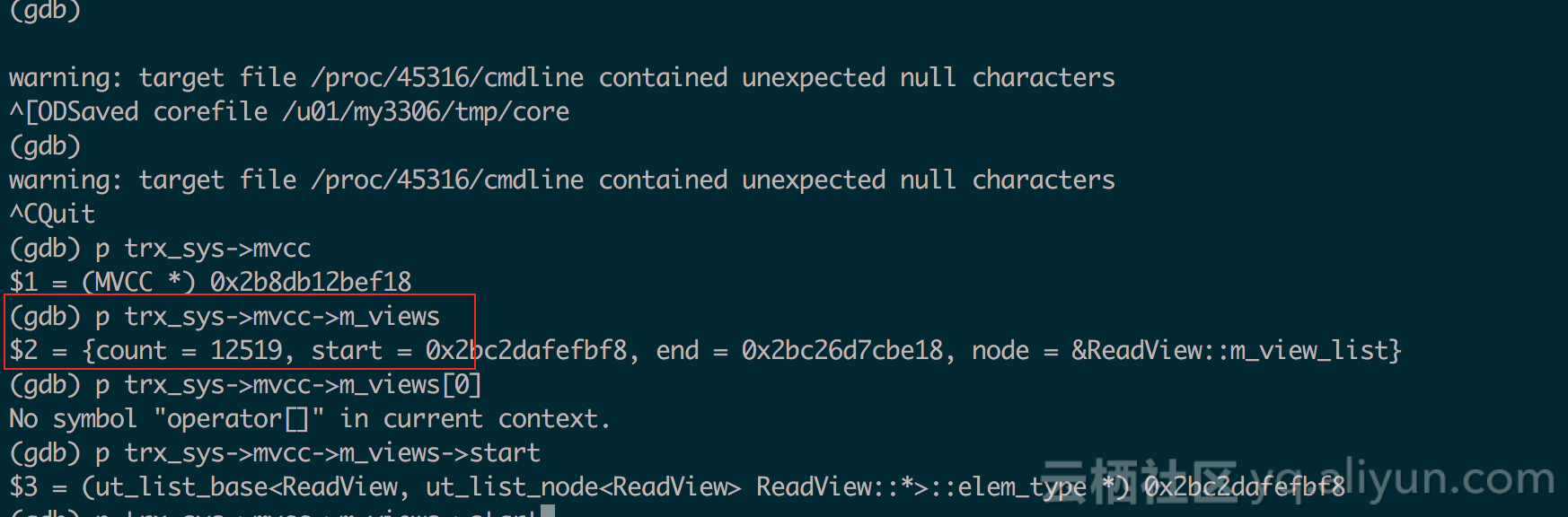
这样一万多个readview大部分都是close状态,导致purge线程在查找oldest readview时须对链表进行大量的扫描,直接导致此过程非常耗时。下图是我们用perf抓的函数cpu开销
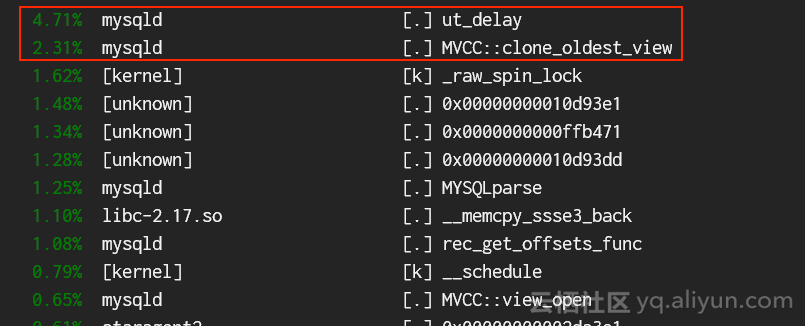
更加要命的是,后台purge线程在扫描全局readview链表时持有事务系统的全局锁,从而导致这把锁的争用更加激烈,从perf结果上可以看到ut_delay()函数调用稳居前列。
全链路压测过程我们一个核心业务上第一次暴露此问题,直接反应就是rt飙升吞吐下降。下图是压测过程中业务的rt表现(单位:us,平均RT已经到了8ms左右)
为什么是全链路压测过程中暴露此问题,因为此时业务场景满足了以下几个条件:
1. 活跃连接数够多,高峰能达到10000+;
2. autocommit只读事务和写事务混合并发;
3. 大部分是单条sql的简单事务;
这是因为,有autocommit只读事务且事务并发度高才会导致全局readview链表中close的readview足够多。有写事务并发才会产生undo日志,后台purge线程才需要进行回收,这样才会去查找oldest readview。都是单条sql的简单事务,事务begin和commit的开销占比才够大,竞争事务系统的全局大锁才能影响到rt和吞吐。
虽然是全链路压测过程中才集中爆发的问题,但是我们通过复盘系统监控发现此问题会经常导致rt飙升。这是因为业务习惯使用autocommit只读事务(autocommit=1时,一条query就是一个autocmmit只读事务),一旦读压力上升就会导致全局readview链表变长,后台purge线程获取oldest readview时会"长时间"持有全局事务锁,此时必然影响所有事务的begin和commit,尤其对于大多数小事务场景特别明显。
由于这是一个非常普遍的问题,我们已经将它提交给了MySQL官方。所以,如果平时你的系统会有rt突然飙升的情况发生,可以考虑从这个方向思考。
如何解决
问题产生的根本原因是全局readview链表中close状态的readview太多了,导致查找oldest readview时需要遍历非常多的无效节点,而产生这个问题的原因是autocommit只读事务延迟释放readview。清楚这一点后问题就很好解决了:autocommit只读事务结束快照读后随即将readviwe从全局链表中删除。这样修改后,查找oldest readview时依然只需找到全局readview链表最后一个节点即可,非常地快捷。
修改后的影响:
1, 只读场景是否会降低到5.6的水平?
答:不会的,5.7对只读场景的优化是多方面的,既包括上层元数据锁的优化也包括InnoDB层的若干优化,这些优化叠加起来在我们的环境下测试约有30%+的性能提升,而readview延迟的
优化只占了很小一块,根据我们的测试性能下降大概在5%以内
2, 对纯读写事务并发是否有影响?
答:没有影响,延迟释放readview只对autocommit只读事务有效,读写事务的readview完成快照读后依然是要从全局readview链表中摘除,因此此修改对读写事务没有影响。
3, 对只读事务和读写事务混合场景的影响?
答:此场景下性能是有提升的,因为能够降低事务系统全局锁的竞争。下图是修改后的rt(单位:us。相同的压力下,RT从修复前的8ms下降到了0.2ms)