3.3 批量处理操作
现在我们已经介绍过添加、检索和删除表中数据的操作了,不过前面介绍的操作都是基于单个实例或基于列表的操作。这一节将会介绍一些API调用,这些调用可以批量处理跨多行的不同操作。
文字事实上,许多基于列表的操作,如delete(List deletes)或者get(List gets),都是基于batch()方法实现的。它们都是一些为了方便用户使用而保留的方法。如果你是新手,推荐使用batch()方法进行所有操作。
下面的客户端API方法提供了批量处理操作。用户可能注意到这里引入了一个新的名为Row的类,它是Put、Get和Delete的祖先,或者说是父类。
void batch(List< Row> actions,Object[] results)
throws IOException,InterruptedException
Object[] batch(List< Row> actions)
throws IOException,InterruptedException
使用同样的父类允许在列表中实现多态,即放入以上3种不同的子类。这种调用跟之前介绍的基于列表的调用方法一样简单易用。下面的例3.16展示了如何把不同的操作融合为一个服务器端调用。
图像说明文字请注意,不可以将针对同一行的Put和Delete操作放在同一个批量处理请求中。为了保证最好的性能,这些操作的处理顺序可能不同,但是这样会产生不可预料的结果。由于资源竞争,某些情况下,用户会看到波动的结果。
例3.16 使用批量处理操作的应用示例
private final static byte[] ROW1 = Bytes.toBytes("row1");
private final static byte[] ROW2 = Bytes.toBytes("row2");
private final static byte[] COLFAM1 = Bytes.toBytes("colfam1");
private final static byte[] COLFAM2 = Bytes.toBytes("colfam2");
private final static byte[] QUAL1 = Bytes.toBytes("qual1");
private final static byte[] QUAL2 = Bytes.toBytes("qual2");
List< Row> batch = new ArrayList< Row>();
Put put = new Put(ROW2);
put.add(COLFAM2,QUAL1,Bytes.toBytes("val5"));
batch.add(put);
Get get1 = new Get(ROW1);
get1.addColumn(COLFAM1,QUAL1);
batch.add(get1);
Delete delete = new Delete(ROW1);
delete.deleteColumns(COLFAM1,QUAL2);
batch.add(delete);
Get get2 = new Get(ROW2);
get2.addFamily(Bytes.toBytes("BOGUS"));
batch.add(get2);
Object[] results = new Object[batch.size()];
try {
table.batch(batch,results);
} catch(Exception e){
System.err.println("Error: " + e);
}
for(int i = 0;i < results.length;i++){
System.out.println("Result[" + i + "]: " + results[i]);
}
使用常量可以方便重用。
创建列表存放所有操作。
添加一个Put实例。
添加一个针对不同行的Get实例。
添加一个Delete实例。
添加一个会失败的Get实例。
创建一个结果数组。
打印捕获的异常。
打印所有结果。
从控制台上可以看到以下结果:
Before batch call...
KV: row1/colfam1:qual1/1/Put/vlen=4,Value: val1
KV: row1/colfam1:qual2/2/Put/vlen=4,Value: val2
KV: row1/colfam1:qual3/3/Put/vlen=4,Value: val3
Result[0]: keyvalues=NONE
Result[1]: keyvalues={row1/colfam1:qual1/1/Put/vlen=4}
Result[2]: keyvalues=NONE
Result[3]: org.apache.hadoop.hbase.regionserver.NoSuchColumnFamilyException:
org.apache.hadoop.hbase.regionserver.NoSuchColumnFamilyException:
Column family BOGUS does not exist in ...
After batch call...
KV: row1/colfam1:qual1/1/Put/vlen=4,Value: val1
KV: row1/colfam1:qual3/3/Put/vlen=4,Value: val3
KV: row2/colfam2:qual1/1308836506340/Put/vlen=4,Value: val5
Error: org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException:
Failed 1 action: NoSuchColumnFamilyException: 1 time,
servers with issues: 10.0.0.43:60020,
与之前的例子一样,在执行批量处理之前,由于插入了测试行的数据,因此先打印了测试行的相关输出。首先输出的是表的原内容,然后是示例代码产生的输出,最后输出的是操作以后的表的内容。由输出结果可见,要删除的列被删除了,新添加的列也成功添加了。
Get操作的结果需要观察输出结果的中间部分,即示例代码产生的输出。那些以Result[n](n从0到3)开头的输出是actions参数中对应操作的结果。示例中第一个操作是Put,对应的结果是一个空的Result实例,其中没有KeyValue实例。这是批量处理调用返回值的通常规则,它们给每个输入操作返回一个最佳匹配的结果,可能的返回值如表3-7所示。
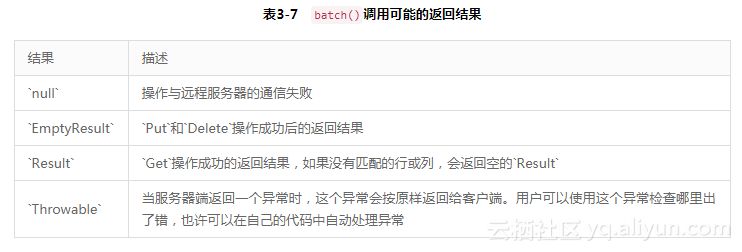
更进一步地观察控制台上输出的返回结果数组,你会发现空的Result实例打印出来是:keyvalues=NONE。Get请求成功找到了相匹配的结果,返回一个对应的KeyValue实例。最后,有一个BOGUS列族的操作请求并返回一个异常供用户参考。
文字当用户使用batch()功能时,Put实例不会被客户端写入缓冲区缓冲。batch()请求是同步的,会把操作直接发送到服务器端,这个过程没有什么延迟或其他中间操作。这与put()调用明显不同,所以请慎重挑选需要的方法。
有两种不同的批量处理操作看起来非常相似。不同之处在于,一个需要用户输入包含返回结果的Object数组,而另一个由函数帮助用户创建这个数组。为什么需要两个方法呢?它们的语义有什么不同吗(如果有不同的话)?它们都可能抛出之前见到过的RetriesExhaustedWithDetailsException,所以关键的不同在于:
void batch(List<Row> actions,Object[] results)
throws IOException,InterruptedException
上面这个方法让用户可以访问部分结果,而下面这个方法不行:
Object[] batch(List<Row> actions)
throws IOException,InterruptedException
后面这个方法如果抛出异常的话,不会有任何返回结果,因为新结果数组返回之前,控制流就中断了。
而之前的方法会先向用户提供的数组中填充数据,然后再抛出异常。例3.16的代码就采用了前一种方法,并提交了结果数组。下面是一些batch()方法特性的汇总。
两种方法的共同点
get、put和delete都支持。如果执行时出现问题,客户端将抛出异常并报告问题。它们都不使用客户端写缓冲区。
void batch(actions, results)
能够访问成功操作的结果,同时也可以获取远程远程什么需要两个方法呢?他失败时的异常。
Object[] batch(actions)
只返回客户端异常,不能访问程序执行中的部分结果。
文字在检查结果之前,所有的批量处理操作都被执行了:即使用户收到一个操作的异常,其他操作也都已经执行了。不过,在最坏的情况下,可能所有操作都会返回异常。
另外,批量处理可以感知暂时性错误,例如NotServingRegionException(表明一个region已经被移动)会多次重试这个操作。用户可以通过调整hbase.client.retries.number配置项(默认是10)来增加或减少重试次数。