时间:2016年10月29日凌晨
地点:阿里巴巴西溪园区“光明顶”
事件:200多人聚在一起,精神抖擞,摩拳擦掌。这阵势,是要去约群架吗?别紧张,他们只是在进行一次双11的模拟演习—全链路压测。

历年的双11备战过程当中,最大的困难在于评估从用户登录到完成购买的整个链条中,核心页面和交易支付的实际承载能力。自2009年第一次双11以来,每年双11的业务规模增长迅速,0点的峰值流量带给我们的不确定性越来越大。
2010年,我们上线了容量规划平台从单个点的维度解决了容量规划的问题,然而在进行单点容量规划的时候,有一个前提条件:下游依赖的服务状态是非常好的。实际情况并非如此,双11 当天0点到来的时候,从CDN到接入层、前端应用、后端服务、缓存、存储、中间件整个链路上都面临着巨大流量,这个时候应用的服务状态除了受自身影响,还会受到依赖环境影响,并且影响面会继续传递到上游,哪怕一个环节出现一点误差,误差在上下游经过几层累积后会造成什么影响谁都无法确定。
所以除了进行事先的容量规划,我们还需要建立起一套验证机制,来验证我们各个环节的准备都是符合预期的。验证的最佳方法就是让事件提前发生,如果我们的系统能够提前经历几次“双11”,容量的不确定性问题也就解决了。全链路压测的诞生解决了容量的确定性问题!
全链路压测1.0从无到有
提前对双11进行模拟听起来就不简单,毕竟双11的规模和复杂性都是空前的,要将双11提前模拟出来,难度可想而知:
1、跟双11相关的业务系统上百个,并且牵涉到整条链路上所有的基础设施和中间件,如何确保压测流量能够通畅无阻,没有死角?
2、压测的数据怎么构造(亿万级的商品和用户),数据模型如何与双11贴近?
3、全链路压测直接在线上的真实环境进行双11模拟,怎么样来保障对线上无影响?
4、双11是一个上亿用户参与的盛大活动,所带来的巨大流量要怎么样制作出来?
来看下我们需要面对的挑战:
以2016年双11前30分钟为例,每秒交易峰值17.5W笔,每秒支付峰值12W笔,相关链路光核心系统上百个,还有庞大的底层基础设施(网络、IDC、硬件、虚拟化、调度、弹性能力等),以及所有的中间件服务、数据库、存储,我们保障双11的需求分层依次是确保没有瓶颈短板、合理规划容量配比降低成本、根据压测模型动态调配容量配比。
但是线下压测(没有参考价值)、单机类型压测+估算模型(无法识别全局瓶颈)、单链路压测(无法识别真实业务场景下多链路冲击下的短板)都显然远远无法满足需求,为了让最真实的情况能够提前预演,我们最终采用了这套模拟全球几亿用户一起购物狂欢的方案-全链路压测平台。而它从2013年到2016年的4个年头里已经发展到3.0版本。
下图是这几年主要完成的工作。
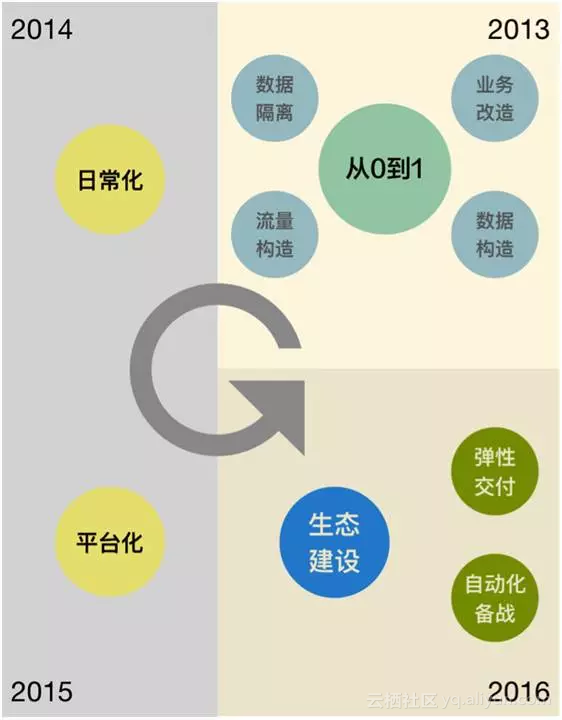
下面就其中一些关键点做下说明:
关于业务改造
涉及业务点100多个,交易链路几十条,相关研发同学几百号人,只要是写相关接口肯定需要改造,压测设计的原则是业务系统的代码尽可能的不做修改、通用的技术通过基础设施和中间件来处理,比如压测流量的标识怎么在整个请求生命周期中一直传递下去、怎么样来对非法的请求做拦截处理。
关于数据构造
数据构造有两个关键点:
1、由于参与双11的买家、卖家、商品数量都非常庞大,需要构造同数量级的庞大业务数据;
2、同时业务数据的模型要尽可能贴近双11当天0点的真实场景;
以上两个关键点必须同时做到,否则全链路压测结果的误差会比较大,参考的价值将会大打折扣。我们为此专门搭建了全链路压测的数据构造平台,构建业务模型,同时完成海量业务数据的自动化准备。
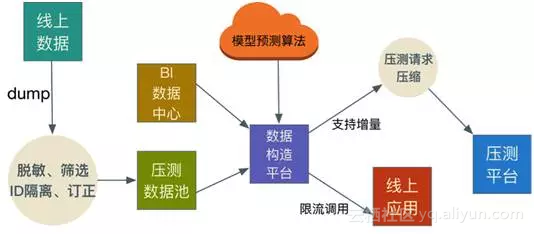
其实关于数据的模型应该是怎么样的问题。我们借助了BI工具结合预测算法对数据进行筛选建模,并结合每一年双11的业务玩法进行修订,产出一份最终的业务模型。业务模型的因子牵涉几百个业务指标,包含买家数、买家类型、卖家数、卖家类型、优惠种类、优惠比例、购物车商品数、bc比例、无线pc比例,业务的量级等等。
关于数据隔离
比如直接把测试数据和正常数据写到一起,通过特殊的标识能够区分开,出于对线上的数据的安全性和完整性不能被破坏的考量,这个方案很快就被放弃了。然后有人提出了另一个方案,在所有写数据的地方做mock,并不真的写进去,这个方案不会对线上产生污染,但也还是放弃了:mock对压测结果的准确性会产生干扰,而我们需要一个最贴近实际行为的压测结果。
经过反复的讨论,最终找到了一个既不污染线上、又能保障压测结果准确性的方案:所有写数据的地方对压测流量进行识别,判断一旦是压测流量的写,就写到隔离的位置,包括存储、缓存、搜索引擎等等。
关于流量构造
双11当天0点的峰值流量是平时高峰的几百倍,每秒钟几百万次的请求如何构造同样成了压测的大难题。浏览器引擎或者一些开源压测工具来模拟用户请求的做法经过实际测试,要制作出双11规模的用户流量需要准备几十万台服务器的规模,成本是无法接受的,并且在集群控制、请求定制上存在不少限制。既然没有现成的工具可以使用,只好选择自己研发一套全链路压测的流量平台。
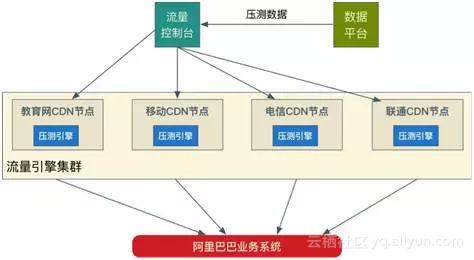
而随着集团业务需求越来越多,急需将全链路压测朝着平台化推进和实施,做到压测能力开放、业务方自主压测,让更多业务方能够享受到全链路压测的优势和便利。平台化上线之后大幅提升了全链路压测平台的服务能力,比如2015年大促备战的3个月内,压测平台总共受理近600多个压测需求(比14年提升20倍),执行压测任务3000多次(比14年提升30倍),最重要的,这也为阿里云即将推出的性能测试PTS铂金版做了很好的基础建设。
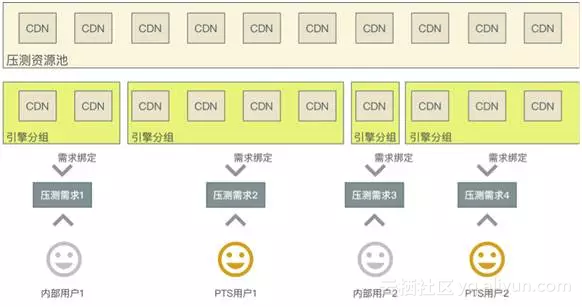
生态化
2016年在三地五单元混合云部署架构下,电商一半以上的资源都部署在云上。如何能够在最短的时间内完成一个单元的搭建和容量准备成为摆在我们面前的一道难题。“大促容量弹性交付产品”在年初的时候立项,旨在减少甚至释放活动场景的容量交付中人工投入,将大促容量交付的运维能力沉淀到系统中,使全链路容量具备“自动化”调整的能力。
我们又提出了大促自动化备战的想法,将大促容量准备的各环节进行系统层面的打通,从业务因子埋点、监控体系、模型预测、压测数据构造、压测流量发送、压测结果分析、压测报表进行自动化的串联,大幅缩减了我们在大促容量准备阶段的人员投入和时间周期。围绕全链路压测的核心基础设施,全链路压测的周边生态逐步建立起来,打通建站、容量、监控等配套技术体系。
阿里云发布T级数据压测的终极秘笈
阿里云的压测解决方案-性能测试服务 PTS 就脱胎于阿里巴巴的双11保障的核武器。在经过超高峰值、超高复杂度的千锤百炼后,性能测试 PTS(铂金版)正式对外输出,让广大企业级用户能用最低的投入,享受阿里双11保障级的性能测试服务。
PTS铂金版目前已经将异常强大的流量构造能力和简易友好的数据输入方式提供出来。阿里云希望帮助企业腾出更多时间和成本去关注业务,而不再需要投入大量资源去研究压测的引擎、改造并让它适应业务特性,也不需要搭建庞大的压测集群以支持业务的高并发度,甚至不需要专门的性能测试人员或者具备相当的测试专业知识的人员,以上这些会让企业投入大量的人力成本、机器成本,性价比较低。PTS铂金版提供了简洁、高效、优质和高性价比的方案,它的优势和特点是:
1、无限接近真实的流量:覆盖到三四线城市的节点能真正模拟高并发和发起点分散的用户行为,端到端之间的网络瓶颈也能暴露无遗;
2、超高并发能力:低成本构造千万TPS级的压测流量,多协议支持(HTTP、HTTPS、TCP、UDP 等);
3、压测能力多维度动态支持:同时支持并发和TPS两个维度设置,免除设置和换算的烦恼,压测目标设置一步到位。压测过程中还可以根据各种情况任意调整并发/TPS,灵活应对压测场景下的多变环境;
4、使用零门槛:完全面向开发的交互设计,开发自测试,贴心的提供快捷压测功能,1分钟即可设置一个简单压测场景,快速熟悉产品功能;
5、复杂场景轻松应对:即使是电商交易类复杂场景,依旧可以方便的通过脚本拼装,完全模拟用户真实行为;
6、丰富的展现形式:压测过程中重要指标实时展现,配合阿里云互联网中间件的业务实时监控ARMS、分布式应用服务EDAS,可提供更全面、细致的性能指标,快速识别性能瓶颈。
来源:阿里技术
原文链接