1.2 算法歧视、隐私、安全/责任、机器人权利等AI伦理问题日益浮现
所以我们看到,AI确实是一场正在发生的社会变革,潜在的好处是巨大的。但是,我们也不能忽视AI背后的伦理问题。我今天主要讲四个方面的伦理问题。
第一个是算法歧视。可能人们会说,算法是一种数学表达,很客观的,不像人类那样有各种偏见、情绪,容易受外部因素影响,怎么会产生歧视?之前的一些研究表明,法官在饿着肚子时,对犯罪嫌疑人是比较严厉的,判刑会比较重,所以人们常说,正义取决于法官有没有吃早餐。但是,算法也正在带来类似的歧视问题。比如,美国一些法院使用的一个犯罪风险评估算法COMPAS被证明是对黑人造成了系统性歧视。什么意思?就是说,如果你是一个黑人,一旦你犯了罪,你就更有可能被这个系统错误地标记为具有高犯罪风险,从而被法官判处监禁,或者判处更长的刑期,即使你本应得到缓刑。此外,一些图像识别软件之前还将黑人错误地标记为“黑猩猩”或者“猿猴”;去年3月,微软在Twitter上上线的聊天机器人Tay在与网民互动过程中,成为了一个集性别歧视、种族歧视等于一身的“不良少女”。随着算法决策越来越多,类似的歧视也会越来越多。
算法歧视具有危害性。一些推荐算法决策可能是无伤大雅的,但是如果将算法应用在犯罪评估、信用贷款、雇佣评估等关切人身利益的场合,因为它是规模化运作的,并不是仅仅针对某一个人,可能影响具有类似情况的一群人或者种族的利益,所以规模性是很大的。而且,算法决策的一次小的失误或者歧视,会在后续的决策中得到增强,可能就成了连锁效应,这次倒霉了,后面很多次都会跟着倒霉。此外,深度学习是一个典型的“黑箱”算法,连设计者可能都不知道算法如何决策,要在系统中发现有没有存在歧视和歧视根源,在技术上可能是比较困难的。
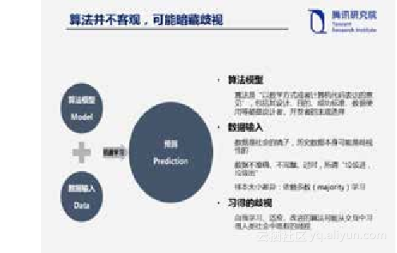
现在说一下为什么算法不是很客观,可能暗藏歧视。算法决策在很多时候其实就是一种预测,用过去的数据预测未来的趋势。算法模型和数据输入决定着预测的结果。因此,这两个要素也就成为了算法歧视的主要来源。一方面,算法在本质上是“以数学方式或者计算机代码表达的意见”,包括其设计、目的、成功标准、数据使用等都是设计者、开发者的主观选择,他们可能将自己的偏见嵌入算法系统。另一方面,数据的有效性、准确性,也会影响整个算法决策和预测的准确性。比如,数据是社会现实的反应,训练数据本身可能是歧视性的,用这样的数据训练出来的AI系统自然也会带上歧视的影子;再比如,数据可能是不正确、不完整或者过时的,带来所谓的“垃圾进,垃圾出”的现象;更进一步,如果一个AI系统依赖多数学习,自然不能兼容少数族裔的利益。此外,算法歧视可能是具有自我学习和适应能力的算法在交互过程中习得的,AI系统在与现实世界交互过程中,可能没法区别什么是歧视、什么不是歧视。

最后,算法倾向于将歧视固化或者放大,使歧视自我长存于整个算法里面。奥威尔在他的政治小说《1984》中写过一句很著名的话:“谁掌握过去,谁就掌握未来;谁掌握现在,谁就掌握过去。”这句话其实也可以用来类比算法歧视。归根到底,算法决策是在用过去预测未来,而过去的歧视可能会在算法中得到巩固并在未来得到加强,因为错误的输入形成的错误输出作为反馈,进一步加深了错误。最终,算法决策不仅仅会将过去的歧视做法代码化,而且会创造自己的现实,形成一个“自我实现的歧视性反馈循环”。因为如果用过去的不准确或者有偏见的数据去训练算法,出来的结果肯定也是有偏见的;然后再用这一输出产生的新数据对系统进行反馈,就会使偏见得到巩固,最终可能让算法来创造现实。包括预测性警务、犯罪风险评估等等都存在类似的问题。所以,算法决策其实缺乏对未来的想象力,而人类社会的进步需要这样的想象力。
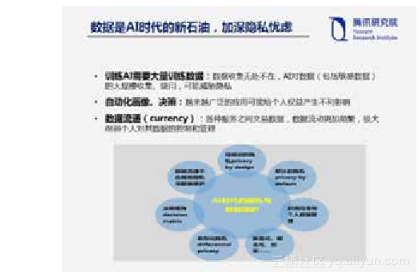
第二个是隐私。很多AI系统,包括深度学习都是大数据学习,需要大量的数据来训练学习算法。所以人们说数据已经成了AI时代的新石油。这带来新的隐私忧虑。一方面,AI对数据包括敏感数据的大规模收集、使用,可能威胁隐私,尤其是如果在深度学习过程中使用大量的敏感数据比如医疗健康数据,这些数据可能会在后续过程中被揭露出去,对个人的隐私会产生影响。所以国外的AI研究人员已经在提倡如何在深度学习过程中保护个人隐私,一篇名为“Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data”寻求在深度学习过程中包含隐私,在今年的AAAI会议上被评为优秀论文。另一方面,用户画像、自动化决策的广泛应用也可能给个人权益产生不利影响。此外,考虑到各种服务之间大量交易数据,数据流动不断频繁,数据成为新的流通物,可能削弱个人对其个人数据的控制和管理。当然,其实现在已经有一些可以利用的工具在AI时代加强隐私保护,诸如经规划的隐私、默认的隐私、个人数据管理工具、匿名化、假名化、加密、差别化隐私等都是在不断发展和完善的一些标准,值得在深度学习中提倡。
第三个是责任与安全。一些名人如霍金、施密特等之前都警惕强人工智能或者超人工智能可能威胁人类生存。但我这里想说的AI安全,其实是指智能机器人运行过程中的安全、可控性,包括行为安全和人类控制。从阿西莫夫提出的机器人三定律,到2017年阿西洛马会议提出的23条人工智能原则,AI安全始终是人们关注的一个重点。此外,安全往往与责任相伴。现在无人驾驶汽车也会发生车祸,那么如果智能机器人造成人身、财产损害,谁来承担责任?如果按照现有的法律责任规则,因为系统是自主性很强的,它的开发者是不能预测的,包括黑箱的存在,很难解释事故的原因,未来可能会产生责任鸿沟。

最后一个是机器人权利,即如何界定AI的人道主义待遇。随着自主智能机器人越来越强大,那么它们在人类社会到底应该扮演什么样的角色?是不是可以在某些方面获得像人一样的待遇,也就是说,享有一定的权利?我们可以虐待、折磨或者杀死机器人吗?比如,拿陈老师团队开发的智能机器人“佳佳”来说,如果有人误以为佳佳是人类,然后上前猥亵,我们可以起诉他犯了强制猥亵、侮辱妇女罪吗?但是这里出现了犯罪客体错误的问题,因为佳佳不是人类意义上的妇女。那么,自主智能机器人到底在法律上是什么?自然人?法人?动物?物?其实欧盟已经在考虑要不要赋予智能机器人“电子人”的法律人格,具有权利义务并对其行为负责。这个问题未来可能值得更多探讨。